 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Summarization for Video-containing Documents
Paper and Code
Sep 17, 2020
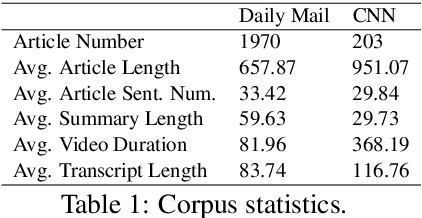

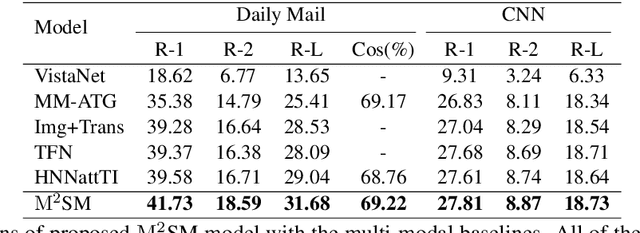
Summarization of multimedia data becomes increasingly significant as it is the basis for many real-world applications, such as question answering, Web search, and so forth. Most existing multi-modal summarization works however have used visual complementary features extracted from images rather than videos, thereby losing abundant information. Hence, we propose a novel multi-modal summarization task to summarize from a document and its associated video. In this work, we also build a baseline general model with effective strategies, i.e., bi-hop attention and improved late fusion mechanisms to bridge the gap between different modalities, and a bi-stream summarization strategy to employ text and video summarization simultaneously. Comprehensive experiments show that the proposed model is beneficial for multi-modal summarization and superior to existing methods. Moreover, we collect a novel dataset and it provides a new resource for future study that results from documents and videos.