 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning
Jun 04, 2021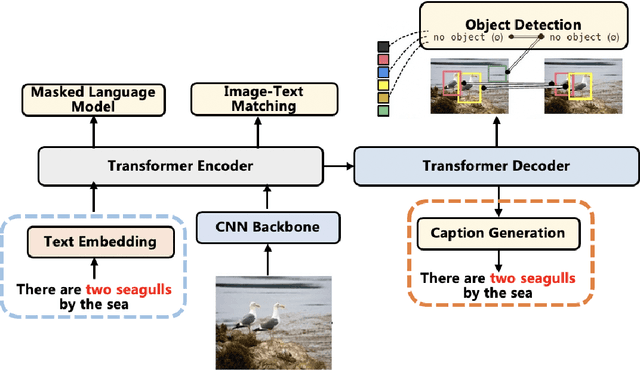

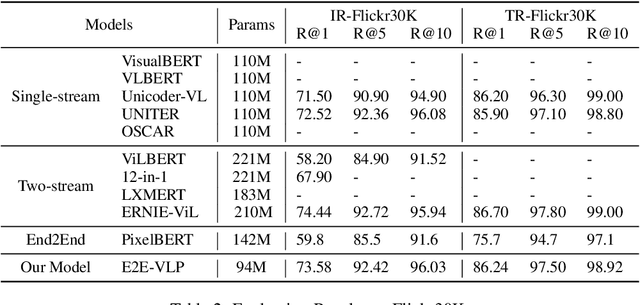
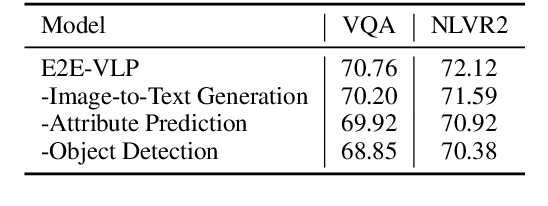
Vision-language pre-training (VLP) on large-scale image-text pairs has achieved huge success for the cross-modal downstream tasks. The most existing pre-training methods mainly adopt a two-step training procedure, which firstly employs a pre-trained object detector to extract region-based visual features, then concatenates the image representation and text embedding as the input of Transformer to train. However, these methods face problems of using task-specific visual representation of the specific object detector for generic cross-modal understanding, and the computation inefficiency of two-stage pipeline. In this paper, we propose the first end-to-end vision-language pre-trained model for both V+L understanding and generation, namely E2E-VLP, where we build a unified Transformer framework to jointly learn visual representation, and semantic alignments between image and text. We incorporate the tasks of object detection and image captioning into pre-training with a unified Transformer encoder-decoder architecture for enhancing visual learning. An extensive set of experiments have been conducted on well-established vision-language downstream tasks to demonstrate the effectiveness of this novel VLP paradigm.
Lexicon Enhanced Chinese Sequence Labeling Using BERT Adapter
May 20, 2021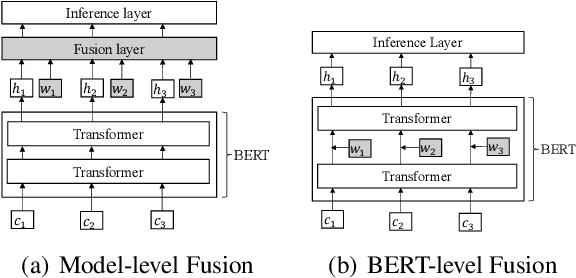
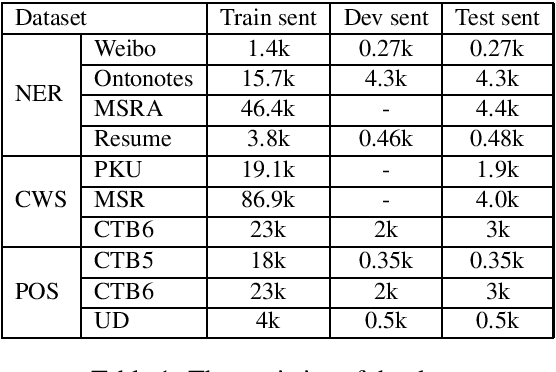
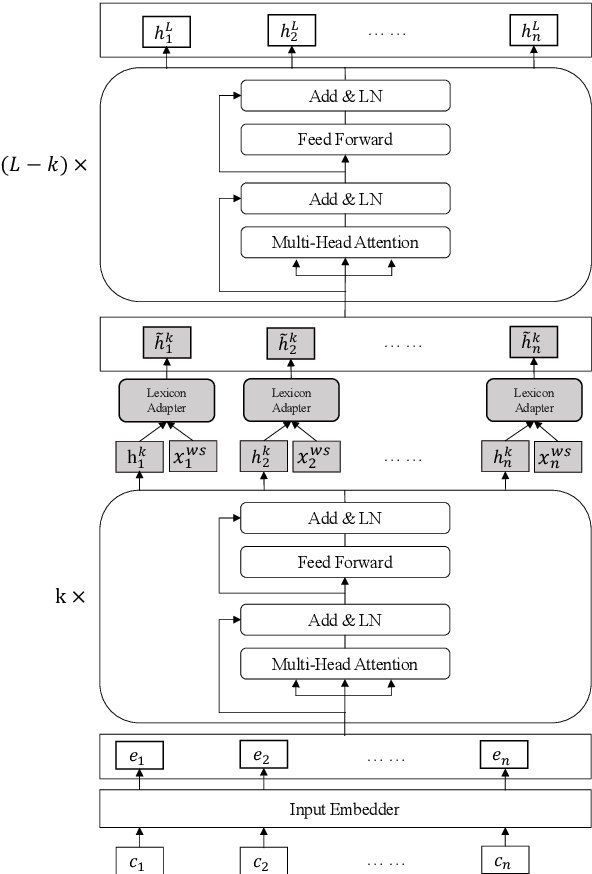
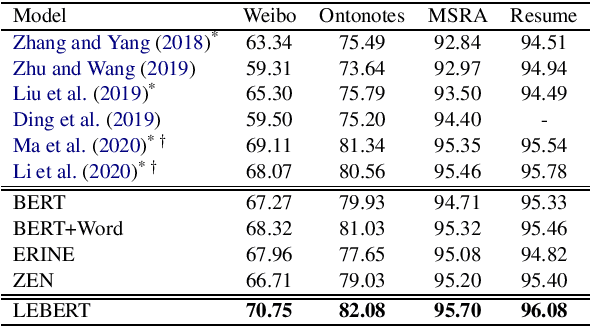
Lexicon information and pre-trained models, such as BERT, have been combined to explore Chinese sequence labelling tasks due to their respective strengths. However, existing methods solely fuse lexicon features via a shallow and random initialized sequence layer and do not integrate them into the bottom layers of BERT. In this paper, we propose Lexicon Enhanced BERT (LEBERT) for Chinese sequence labelling, which integrates external lexicon knowledge into BERT layers directly by a Lexicon Adapter layer. Compared with the existing methods, our model facilitates deep lexicon knowledge fusion at the lower layers of BERT. Experiments on ten Chinese datasets of three tasks including Named Entity Recognition, Word Segmentation, and Part-of-Speech tagging, show that LEBERT achieves the state-of-the-art results.