 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Retrieval via Diffusion Transformer with Metric-Ordered Sequence Training and Hybrid-Policy Preference Optimization
Jun 25, 2026Embedding-based retrieval ranks items by their similarity to a query in a shared vector space and usually aims to return the highest-scoring items. In many production settings this is not what is wanted: given a seed set that expresses a fine-grained pattern, one needs more items that both satisfy a target attribute and stay within that pattern. We formalize this as pattern-preserving attribute retrieval. The two goals pull against each other: averaging the seeds preserves the pattern but stays in a low-attribute region, while global attribute retrieval drifts to unrelated patterns. We approach the task with continuous generative retrieval, where a model reads a sequence of item embeddings and generates query embeddings for nearest-neighbor search. We propose MO-DiT+HPPO, a staged framework with raw-sequence pretraining, multi-domain metric-ordered continuation pretraining, tail-centroid fine-tuning, and HPPO. Metric-ordered training turns sparse online retrieval labels into in-pattern trajectories ordered from low to high predicted attribute density, teaching one model the metric-improvement direction across domains. HPPO aligns the generated query distribution with the true online objective by labeling a hybrid candidate pool with the online intersection metric and applying reference-anchored preference optimization. A Pareto pair filter keeps only winner pairs that do not lower same-pattern purity, raising the attribute metric without sacrificing the pattern. Across four attribute domains under item- and pattern-holdout protocols, metric-ordered DiT improves the intersection metric over a pretrained generative retriever, and HPPO improves it further, with significant gains on seven of eight domain-split cells and a marginal tie on the hardest split. Metric-predictor validation, order ablations, CPT/SFT comparisons, and a candidate-policy ablation show where the gains come from.
PACE: Phase-Aware Chunk Execution for Robot Policies with Action Chunking
May 30, 2026Recent vision-language-action and diffusion-based robot policies often use action chunking, where each policy query predicts a sequence of future actions and the robot executes an open-loop prefix before re-querying. While this interface improves local motion continuity, deployment still requires choosing the execution horizon: how much of each predicted chunk should be executed before acquiring a new observation. However, our experiments show that success is strongly task-dependent and non-monotonic with respect to the execution horizon, making a single constant horizon an unreliable deployment rule. We propose PACE (Phase-Aware Chunk Execution), a training-free test-time execution method that selects the execution horizon online from the predicted chunk itself. PACE exploits the phase-dependent kinematic structure of manipulation trajectories by identifying low-speed transition points in the predicted speed profile and using them as candidate replanning boundaries. Because PACE uses only the predicted action chunk, it is plug-and-play and requires no retraining or access to policy internals. We validate PACE through large-scale evaluations in both simulation and real-robot settings. On 50 RoboTwin2.0 tasks, PACE raises the average success rate from 57.8% to 64.2%. In real-robot experiments on bimanual ALOHA and single-arm Franka platforms, PACE improves the average task score from 60.7 to 77.7 and the average success rate from 50.7% to 70.4%. Ablations and rollout-level analyses show that PACE adapts execution horizons across manipulation phases, shortening near transitions while preserving longer execution during coherent motion.
VFEAgent: A Multimodal Agent Framework for End-to-End Automated Finite Element Analysis
May 27, 2026Finite Element Analysis (FEA) serves as the cornerstone of modern engineering design. However, its workflow is inherently complex and relies heavily on domain expertise. Although recent efforts have integrated Large Language Models (LLMs) into FEA, existing approaches face limitations in handling multimodal inputs and executing complex tasks. To address these limitations, we propose VFEAgent, an end-to-end multi-agent system designed to automate FEA modeling and simulation directly from input images and problem descriptions. Our methodology integrates two core components: (1) a multimodal vision-language multi-agent pipeline that employs ReAct-driven reasoning to extract structured FEA specifications from heterogeneous inputs and (2) a verification-first code synthesis framework, incorporating robust self-debugging and fallback mechanisms to ensure executability and physical validity. We systematically evaluated the system across various engineering mechanics scenarios. The results demonstrate that VFEAgent achieves a high success rate in generating complete and physically valid simulations, outperforming LLM-based baseline methods in reliability and correctness. These findings validate the feasibility of automating the complete FEA workflow, highlighting the framework's potential to liberate engineers from tedious manual analysis.
What Frozen VLAs Already Know About Success: A Probing Study of Value-Like Structure in Foundation Robot Policies
May 27, 2026Vision--language--action (VLA) policies are trained to imitate actions; their loss never asks them to estimate reward, progress, or future success. Their frozen representations nevertheless carry such information, and it can be read out and used to guide action choice without retraining the policy. From mixed successful and failed manipulation trajectories on LIBERO-Goal, we recover Monte-Carlo outcome targets using lightweight linear probes on frozen features. The targets are consistently predictable from OpenVLA, Pi0.5, DINOv2, and CLIP features, and substantially less so from baselines built on progress, time-to-go, task identity, or proprioception. To rule out task and temporal shortcuts, we evaluate the probes under same-task, same-timestep matched comparisons: Pi0.5 probes still reach roughly 92% pairwise ordering accuracy, while label-shuffled controls stay at chance. Used as a test-time selector over sampled Pi0.5 action prefixes, the same probe turns this offline finding into behavior: on push-plate, success rises from 26.7% under greedy decoding to 44.3%, with a second positive case on wine-rack. The gains are not universal and require additional inference compute, but the underlying finding is clean: frozen VLAs already encode information about success that their imitation objective never explicitly demands.
Unlocking the Potential of Model Merging for Low-Resource Languages
Jul 04, 2024



Adapting large language models (LLMs) to new languages typically involves continual pre-training (CT) followed by supervised fine-tuning (SFT). However, this CT-then-SFT approach struggles with limited data in the context of low-resource languages, failing to balance language modeling and task-solving capabilities. We thus propose model merging as an alternative for low-resource languages, combining models with distinct capabilities into a single model without additional training. We use model merging to develop task-solving LLMs for low-resource languages without SFT data in the target languages. Our experiments based on Llama-2-7B demonstrate that model merging effectively endows LLMs for low-resource languages with task-solving abilities, outperforming CT-then-SFT in scenarios with extremely scarce data. Observing performance saturation in model merging with more training tokens, we further analyze the merging process and introduce a slack variable to the model merging algorithm to mitigate the loss of important parameters, thereby enhancing performance. We hope that model merging can benefit more human languages suffering from data scarcity with its higher data efficiency.
Synergetic Event Understanding: A Collaborative Approach to Cross-Document Event Coreference Resolution with Large Language Models
Jun 04, 2024Cross-document event coreference resolution (CDECR) involves clustering event mentions across multiple documents that refer to the same real-world events. Existing approaches utilize fine-tuning of small language models (SLMs) like BERT to address the compatibility among the contexts of event mentions. However, due to the complexity and diversity of contexts, these models are prone to learning simple co-occurrences. Recently, large language models (LLMs) like ChatGPT have demonstrated impressive contextual understanding, yet they encounter challenges in adapting to specific information extraction (IE) tasks. In this paper, we propose a collaborative approach for CDECR, leveraging the capabilities of both a universally capable LLM and a task-specific SLM. The collaborative strategy begins with the LLM accurately and comprehensively summarizing events through prompting. Then, the SLM refines its learning of event representations based on these insights during fine-tuning. Experimental results demonstrate that our approach surpasses the performance of both the large and small language models individually, forming a complementary advantage. Across various datasets, our approach achieves state-of-the-art performance, underscoring its effectiveness in diverse scenarios.
Harder Tasks Need More Experts: Dynamic Routing in MoE Models
Mar 12, 2024In this paper, we introduce a novel dynamic expert selection framework for Mixture of Experts (MoE) models, aiming to enhance computational efficiency and model performance by adjusting the number of activated experts based on input difficulty. Unlike traditional MoE approaches that rely on fixed Top-K routing, which activates a predetermined number of experts regardless of the input's complexity, our method dynamically selects experts based on the confidence level in expert selection for each input. This allows for a more efficient utilization of computational resources, activating more experts for complex tasks requiring advanced reasoning and fewer for simpler tasks. Through extensive evaluations, our dynamic routing method demonstrates substantial improvements over conventional Top-2 routing across various benchmarks, achieving an average improvement of 0.7% with less than 90% activated parameters. Further analysis shows our model dispatches more experts to tasks requiring complex reasoning skills, like BBH, confirming its ability to dynamically allocate computational resources in alignment with the input's complexity. Our findings also highlight a variation in the number of experts needed across different layers of the transformer model, offering insights into the potential for designing heterogeneous MoE frameworks. The code and models are available at https://github.com/ZhenweiAn/Dynamic_MoE.
BUS:Efficient and Effective Vision-language Pre-training with Bottom-Up Patch Summarization
Jul 17, 2023Vision Transformer (ViT) based Vision-Language Pre-training (VLP) models have demonstrated impressive performance in various tasks. However, the lengthy visual token sequences fed into ViT can lead to training inefficiency and ineffectiveness. Existing efforts address the challenge by either bottom-level patch extraction in the ViT backbone or top-level patch abstraction outside, not balancing training efficiency and effectiveness well. Inspired by text summarization in natural language processing, we propose a Bottom-Up Patch Summarization approach named BUS, coordinating bottom-level extraction and top-level abstraction to learn a concise summary of lengthy visual token sequences efficiently. Specifically, We incorporate a Text-Semantics-Aware Patch Selector (TSPS) into the ViT backbone to perform a coarse-grained visual token extraction and then attach a flexible Transformer-based Patch Abstraction Decoder (PAD) upon the backbone for top-level visual abstraction. This bottom-up collaboration enables our BUS to yield high training efficiency while maintaining or even improving effectiveness. We evaluate our approach on various visual-language understanding and generation tasks and show competitive downstream task performance while boosting the training efficiency by 50\%. Additionally, our model achieves state-of-the-art performance on many downstream tasks by increasing input image resolution without increasing computational costs over baselines.
DiffDTM: A conditional structure-free framework for bioactive molecules generation targeted for dual proteins
Jun 24, 2023Advances in deep generative models shed light on de novo molecule generation with desired properties. However, molecule generation targeted for dual protein targets still faces formidable challenges including protein 3D structure data requisition for model training, auto-regressive sampling, and model generalization for unseen targets. Here, we proposed DiffDTM, a novel conditional structure-free deep generative model based on a diffusion model for dual targets based molecule generation to address the above issues. Specifically, DiffDTM receives protein sequences and molecular graphs as inputs instead of protein and molecular conformations and incorporates an information fusion module to achieve conditional generation in a one-shot manner. We have conducted comprehensive multi-view experiments to demonstrate that DiffDTM can generate drug-like, synthesis-accessible, novel, and high-binding affinity molecules targeting specific dual proteins, outperforming the state-of-the-art (SOTA) models in terms of multiple evaluation metrics. Furthermore, we utilized DiffDTM to generate molecules towards dopamine receptor D2 and 5-hydroxytryptamine receptor 1A as new antipsychotics. The experimental results indicate that DiffDTM can be easily plugged into unseen dual targets to generate bioactive molecules, addressing the issues of requiring insufficient active molecule data for training as well as the need to retrain when encountering new targets.
Towards Adaptive Prefix Tuning for Parameter-Efficient Language Model Fine-tuning
May 24, 2023
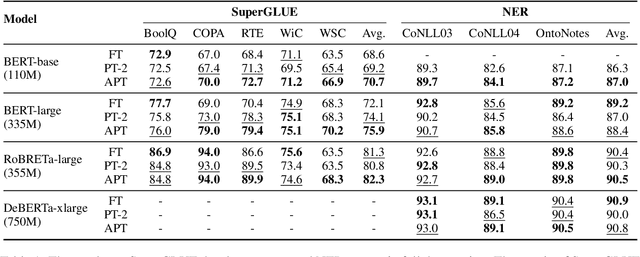
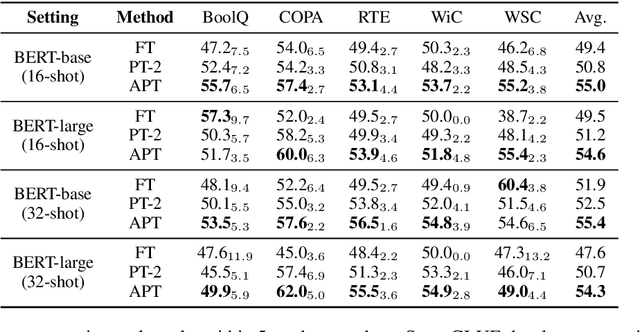
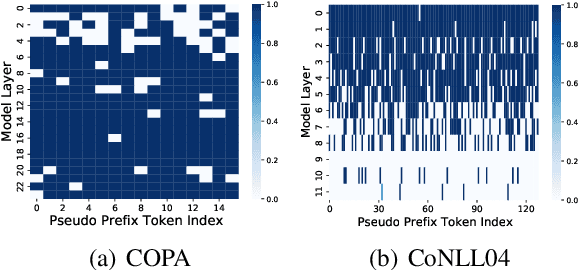
Fine-tuning large pre-trained language models on various downstream tasks with whole parameters is prohibitively expensive. Hence, Parameter-efficient fine-tuning has attracted attention that only optimizes a few task-specific parameters with the frozen pre-trained model. In this work, we focus on prefix tuning, which only optimizes continuous prefix vectors (i.e. pseudo tokens) inserted into Transformer layers. Based on the observation that the learned syntax and semantics representation varies a lot at different layers, we argue that the adaptive prefix will be further tailored to each layer than the fixed one, enabling the fine-tuning more effective and efficient. Thus, we propose Adaptive Prefix Tuning (APT) to adjust the prefix in terms of both fine-grained token level and coarse-grained layer level with a gate mechanism. Experiments on the SuperGLUE and NER datasets show the effectiveness of APT. In addition, taking the gate as a probing, we validate the efficiency and effectiveness of the variable prefix.