 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVECO 2.0: Cross-lingual Language Model Pre-training with Multi-granularity Contrastive Learning
Paper and Code
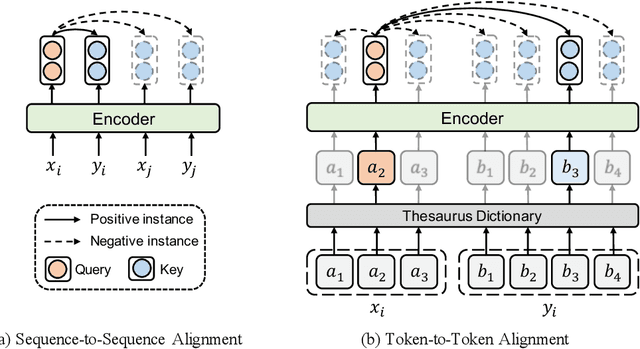
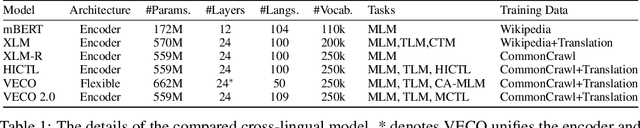
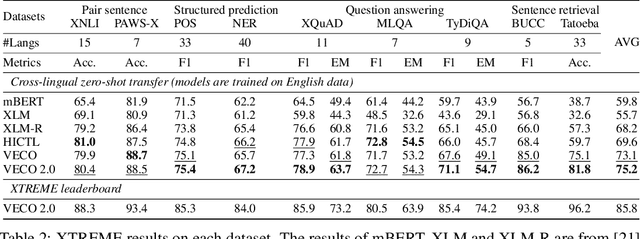
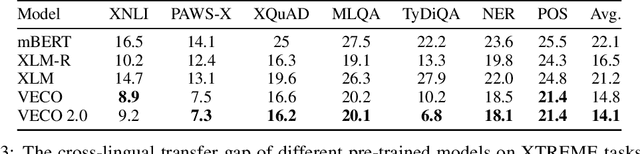
Recent studies have demonstrated the potential of cross-lingual transferability by training a unified Transformer encoder for multiple languages. In addition to involving the masked language model objective, existing cross-lingual pre-training works leverage sentence-level contrastive learning or plugs in extra cross-attention module to complement the insufficient capabilities of cross-lingual alignment. Nonetheless, synonym pairs residing in bilingual corpus are not exploited and aligned, which is more crucial than sentence interdependence establishment for token-level tasks. In this work, we propose a cross-lingual pre-trained model VECO~2.0 based on contrastive learning with multi-granularity alignments. Specifically, the sequence-to-sequence alignment is induced to maximize the similarity of the parallel pairs and minimize the non-parallel pairs. Then, token-to-token alignment is integrated to bridge the gap between synonymous tokens excavated via the thesaurus dictionary from the other unpaired tokens in a bilingual instance. Experiments show the effectiveness of the proposed strategy for cross-lingual model pre-training on the XTREME benchmark.