 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMM: Retrieval-augmented Biomedical Visual Question Answering with Multi-modal Pre-training
Paper and Code

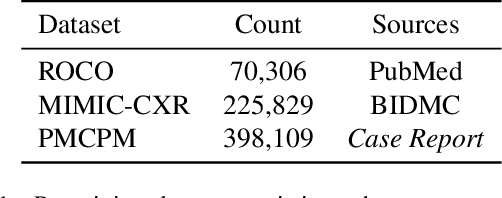
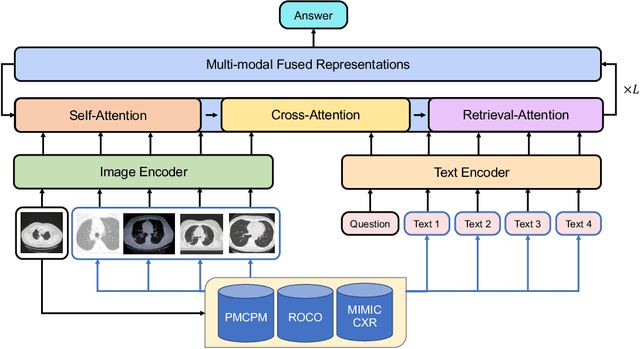
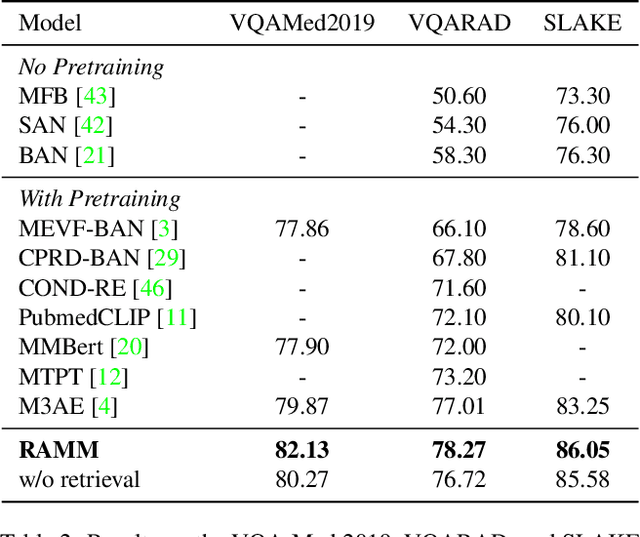
Vision-and-language multi-modal pretraining and fine-tuning have shown great success in visual question answering (VQA). Compared to general domain VQA, the performance of biomedical VQA suffers from limited data. In this paper, we propose a retrieval-augmented pretrain-and-finetune paradigm named RAMM for biomedical VQA to overcome the data limitation issue. Specifically, we collect a new biomedical dataset named PMCPM which offers patient-based image-text pairs containing diverse patient situations from PubMed. Then, we pretrain the biomedical multi-modal model to learn visual and textual representation for image-text pairs and align these representations with image-text contrastive objective (ITC). Finally, we propose a retrieval-augmented method to better use the limited data. We propose to retrieve similar image-text pairs based on ITC from pretraining datasets and introduce a novel retrieval-attention module to fuse the representation of the image and the question with the retrieved images and texts. Experiments demonstrate that our retrieval-augmented pretrain-and-finetune paradigm obtains state-of-the-art performance on Med-VQA2019, Med-VQA2021, VQARAD, and SLAKE datasets. Further analysis shows that the proposed RAMM and PMCPM can enhance biomedical VQA performance compared with previous resources and methods. We will open-source our dataset, codes, and pretrained model.