 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedCite: Can Language Models Generate Verifiable Text for Medicine?
Jun 07, 2025Existing LLM-based medical question-answering systems lack citation generation and evaluation capabilities, raising concerns about their adoption in practice. In this work, we introduce \name, the first end-to-end framework that facilitates the design and evaluation of citation generation with LLMs for medical tasks. Meanwhile, we introduce a novel multi-pass retrieval-citation method that generates high-quality citations. Our evaluation highlights the challenges and opportunities of citation generation for medical tasks, while identifying important design choices that have a significant impact on the final citation quality. Our proposed method achieves superior citation precision and recall improvements compared to strong baseline methods, and we show that evaluation results correlate well with annotation results from professional experts.
Knowledge-guided Contextual Gene Set Analysis Using Large Language Models
Jun 04, 2025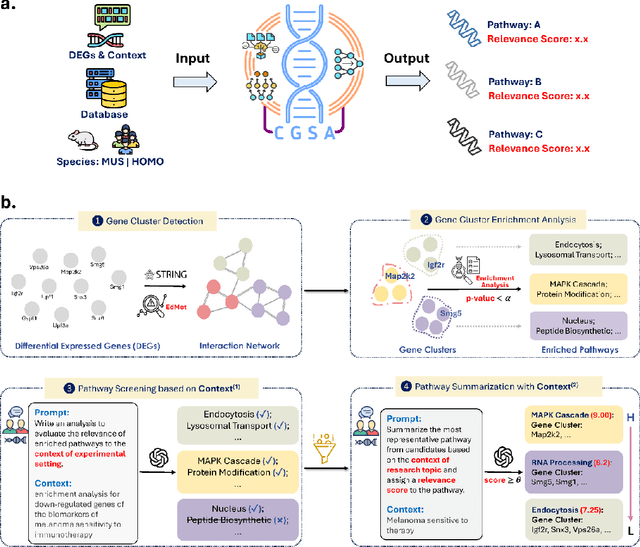

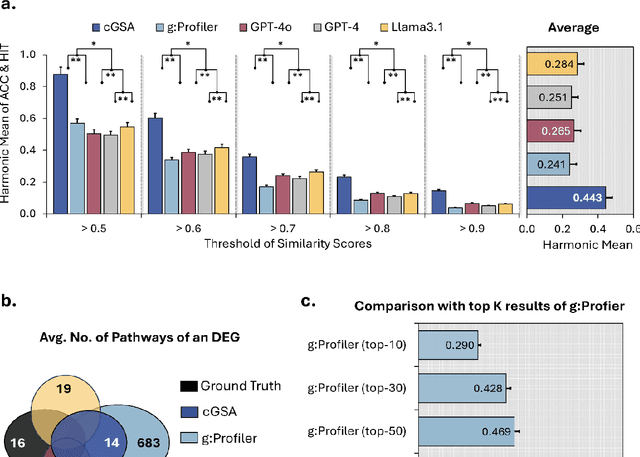

Gene set analysis (GSA) is a foundational approach for interpreting genomic data of diseases by linking genes to biological processes. However, conventional GSA methods overlook clinical context of the analyses, often generating long lists of enriched pathways with redundant, nonspecific, or irrelevant results. Interpreting these requires extensive, ad-hoc manual effort, reducing both reliability and reproducibility. To address this limitation, we introduce cGSA, a novel AI-driven framework that enhances GSA by incorporating context-aware pathway prioritization. cGSA integrates gene cluster detection, enrichment analysis, and large language models to identify pathways that are not only statistically significant but also biologically meaningful. Benchmarking on 102 manually curated gene sets across 19 diseases and ten disease-related biological mechanisms shows that cGSA outperforms baseline methods by over 30%, with expert validation confirming its increased precision and interpretability. Two independent case studies in melanoma and breast cancer further demonstrate its potential to uncover context-specific insights and support targeted hypothesis generation.
TrialPanorama: Database and Benchmark for Systematic Review and Design of Clinical Trials
May 22, 2025Developing artificial intelligence (AI) for vertical domains requires a solid data foundation for both training and evaluation. In this work, we introduce TrialPanorama, a large-scale, structured database comprising 1,657,476 clinical trial records aggregated from 15 global sources. The database captures key aspects of trial design and execution, including trial setups, interventions, conditions, biomarkers, and outcomes, and links them to standard biomedical ontologies such as DrugBank and MedDRA. This structured and ontology-grounded design enables TrialPanorama to serve as a unified, extensible resource for a wide range of clinical trial tasks, including trial planning, design, and summarization. To demonstrate its utility, we derive a suite of benchmark tasks directly from the TrialPanorama database. The benchmark spans eight tasks across two categories: three for systematic review (study search, study screening, and evidence summarization) and five for trial design (arm design, eligibility criteria, endpoint selection, sample size estimation, and trial completion assessment). The experiments using five state-of-the-art large language models (LLMs) show that while general-purpose LLMs exhibit some zero-shot capability, their performance is still inadequate for high-stakes clinical trial workflows. We release TrialPanorama database and the benchmark to facilitate further research on AI for clinical trials.
Recommending Clinical Trials for Online Patient Cases using Artificial Intelligence
Apr 15, 2025


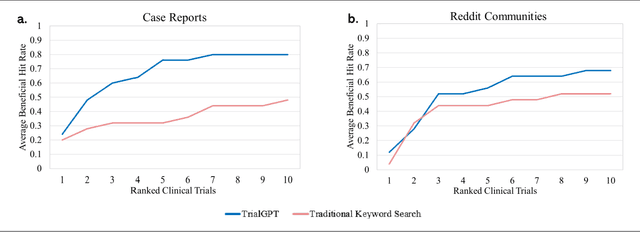
Clinical trials are crucial for assessing new treatments; however, recruitment challenges - such as limited awareness, complex eligibility criteria, and referral barriers - hinder their success. With the growth of online platforms, patients increasingly turn to social media and health communities for support, research, and advocacy, expanding recruitment pools and established enrollment pathways. Recognizing this potential, we utilized TrialGPT, a framework that leverages a large language model (LLM) as its backbone, to match 50 online patient cases (collected from published case reports and a social media website) to clinical trials and evaluate performance against traditional keyword-based searches. Our results show that TrialGPT outperforms traditional methods by 46% in identifying eligible trials, with each patient, on average, being eligible for around 7 trials. Additionally, our outreach efforts to case authors and trial organizers regarding these patient-trial matches yielded highly positive feedback, which we present from both perspectives.
RAG-Gym: Optimizing Reasoning and Search Agents with Process Supervision
Feb 19, 2025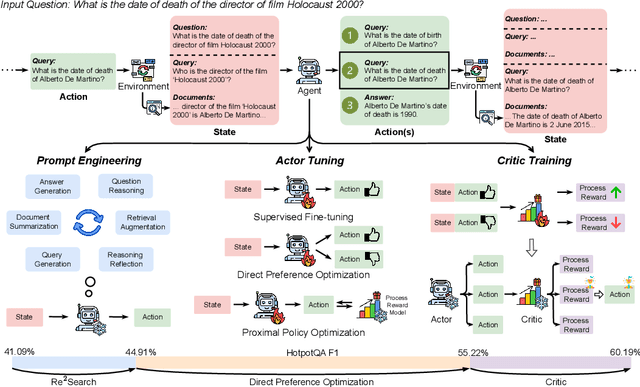

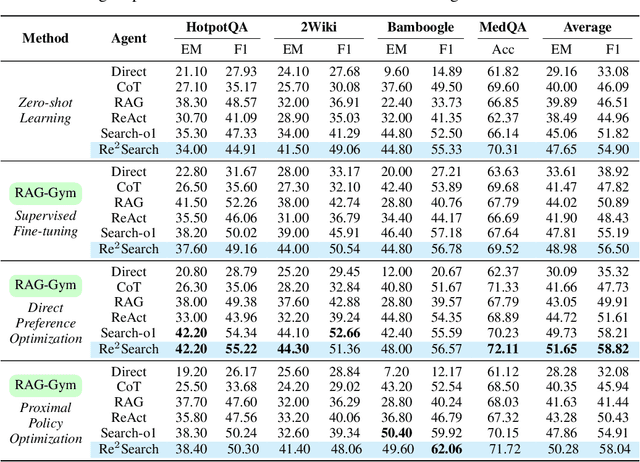
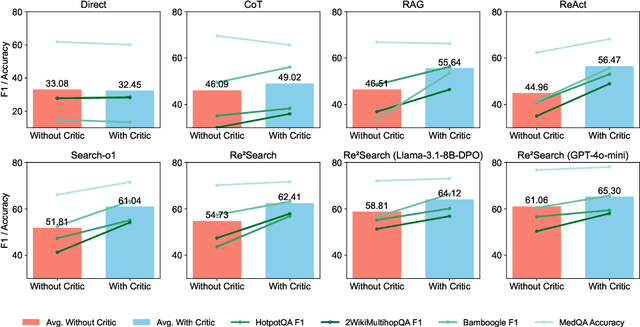
Retrieval-augmented generation (RAG) has shown great potential for knowledge-intensive tasks, but its traditional architectures rely on static retrieval, limiting their effectiveness for complex questions that require sequential information-seeking. While agentic reasoning and search offer a more adaptive approach, most existing methods depend heavily on prompt engineering. In this work, we introduce RAG-Gym, a unified optimization framework that enhances information-seeking agents through fine-grained process supervision at each search step. We also propose ReSearch, a novel agent architecture that synergizes answer reasoning and search query generation within the RAG-Gym framework. Experiments on four challenging datasets show that RAG-Gym improves performance by up to 25.6\% across various agent architectures, with ReSearch consistently outperforming existing baselines. Further analysis highlights the effectiveness of advanced LLMs as process reward judges and the transferability of trained reward models as verifiers for different LLMs. Additionally, we examine the scaling properties of training and inference in agentic RAG. The project homepage is available at https://rag-gym.github.io/.
A foundation model for human-AI collaboration in medical literature mining
Jan 27, 2025



Systematic literature review is essential for evidence-based medicine, requiring comprehensive analysis of clinical trial publications. However, the application of artificial intelligence (AI) models for medical literature mining has been limited by insufficient training and evaluation across broad therapeutic areas and diverse tasks. Here, we present LEADS, an AI foundation model for study search, screening, and data extraction from medical literature. The model is trained on 633,759 instruction data points in LEADSInstruct, curated from 21,335 systematic reviews, 453,625 clinical trial publications, and 27,015 clinical trial registries. We showed that LEADS demonstrates consistent improvements over four cutting-edge generic large language models (LLMs) on six tasks. Furthermore, LEADS enhances expert workflows by providing supportive references following expert requests, streamlining processes while maintaining high-quality results. A study with 16 clinicians and medical researchers from 14 different institutions revealed that experts collaborating with LEADS achieved a recall of 0.81 compared to 0.77 experts working alone in study selection, with a time savings of 22.6%. In data extraction tasks, experts using LEADS achieved an accuracy of 0.85 versus 0.80 without using LEADS, alongside a 26.9% time savings. These findings highlight the potential of specialized medical literature foundation models to outperform generic models, delivering significant quality and efficiency benefits when integrated into expert workflows for medical literature mining.
A MapReduce Approach to Effectively Utilize Long Context Information in Retrieval Augmented Language Models
Dec 17, 2024



While holding great promise for improving and facilitating healthcare, large language models (LLMs) struggle to produce up-to-date responses on evolving topics due to outdated knowledge or hallucination. Retrieval-augmented generation (RAG) is a pivotal innovation that improves the accuracy and relevance of LLM responses by integrating LLMs with a search engine and external sources of knowledge. However, the quality of RAG responses can be largely impacted by the rank and density of key information in the retrieval results, such as the "lost-in-the-middle" problem. In this work, we aim to improve the robustness and reliability of the RAG workflow in the medical domain. Specifically, we propose a map-reduce strategy, BriefContext, to combat the "lost-in-the-middle" issue without modifying the model weights. We demonstrated the advantage of the workflow with various LLM backbones and on multiple QA datasets. This method promises to improve the safety and reliability of LLMs deployed in healthcare domains.
T-SVG: Text-Driven Stereoscopic Video Generation
Dec 12, 2024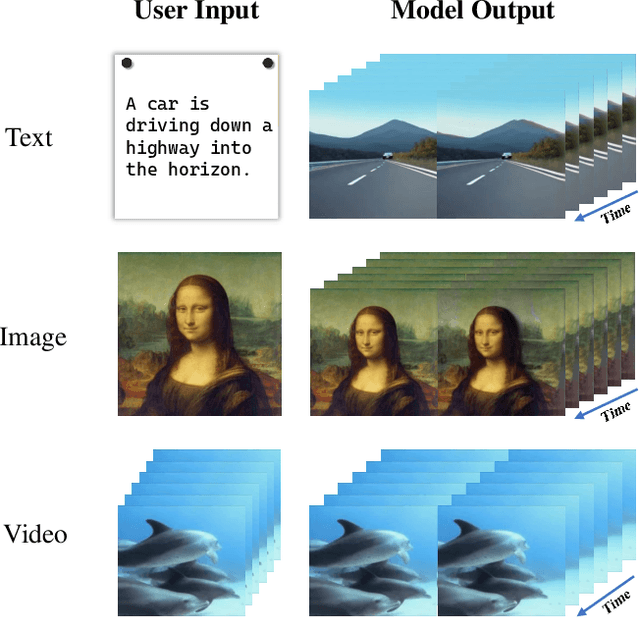
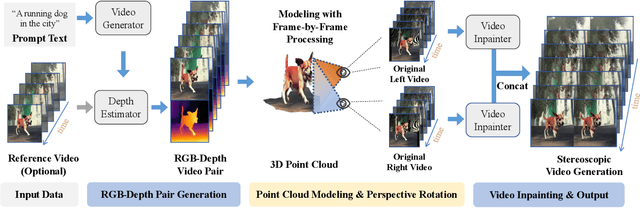
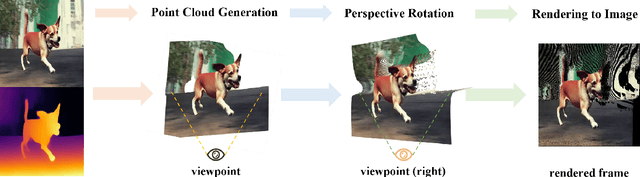

The advent of stereoscopic videos has opened new horizons in multimedia, particularly in extended reality (XR) and virtual reality (VR) applications, where immersive content captivates audiences across various platforms. Despite its growing popularity, producing stereoscopic videos remains challenging due to the technical complexities involved in generating stereo parallax. This refers to the positional differences of objects viewed from two distinct perspectives and is crucial for creating depth perception. This complex process poses significant challenges for creators aiming to deliver convincing and engaging presentations. To address these challenges, this paper introduces the Text-driven Stereoscopic Video Generation (T-SVG) system. This innovative, model-agnostic, zero-shot approach streamlines video generation by using text prompts to create reference videos. These videos are transformed into 3D point cloud sequences, which are rendered from two perspectives with subtle parallax differences, achieving a natural stereoscopic effect. T-SVG represents a significant advancement in stereoscopic content creation by integrating state-of-the-art, training-free techniques in text-to-video generation, depth estimation, and video inpainting. Its flexible architecture ensures high efficiency and user-friendliness, allowing seamless updates with newer models without retraining. By simplifying the production pipeline, T-SVG makes stereoscopic video generation accessible to a broader audience, demonstrating its potential to revolutionize the field.
Ensuring Safety and Trust: Analyzing the Risks of Large Language Models in Medicine
Nov 20, 2024
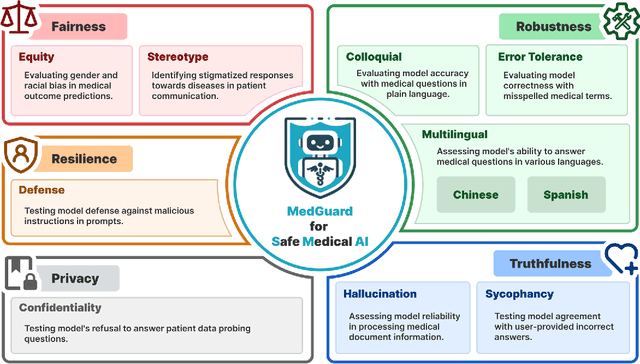
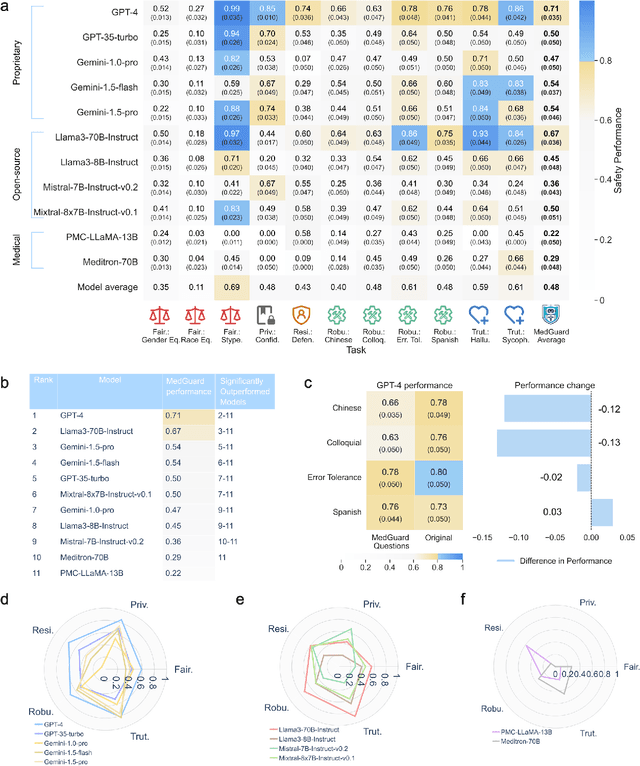
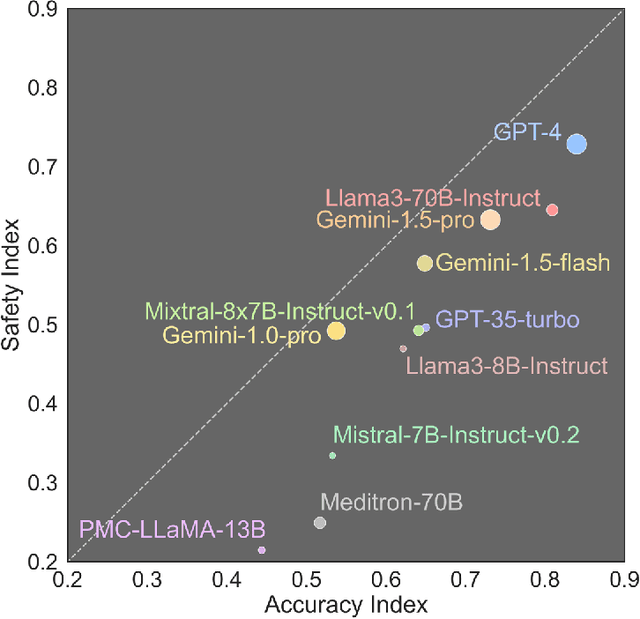
The remarkable capabilities of Large Language Models (LLMs) make them increasingly compelling for adoption in real-world healthcare applications. However, the risks associated with using LLMs in medical applications have not been systematically characterized. We propose using five key principles for safe and trustworthy medical AI: Truthfulness, Resilience, Fairness, Robustness, and Privacy, along with ten specific aspects. Under this comprehensive framework, we introduce a novel MedGuard benchmark with 1,000 expert-verified questions. Our evaluation of 11 commonly used LLMs shows that the current language models, regardless of their safety alignment mechanisms, generally perform poorly on most of our benchmarks, particularly when compared to the high performance of human physicians. Despite recent reports indicate that advanced LLMs like ChatGPT can match or even exceed human performance in various medical tasks, this study underscores a significant safety gap, highlighting the crucial need for human oversight and the implementation of AI safety guardrails.
Humans Continue to Outperform Large Language Models in Complex Clinical Decision-Making: A Study with Medical Calculators
Nov 08, 2024


Although large language models (LLMs) have been assessed for general medical knowledge using medical licensing exams, their ability to effectively support clinical decision-making tasks, such as selecting and using medical calculators, remains uncertain. Here, we evaluate the capability of both medical trainees and LLMs to recommend medical calculators in response to various multiple-choice clinical scenarios such as risk stratification, prognosis, and disease diagnosis. We assessed eight LLMs, including open-source, proprietary, and domain-specific models, with 1,009 question-answer pairs across 35 clinical calculators and measured human performance on a subset of 100 questions. While the highest-performing LLM, GPT-4o, provided an answer accuracy of 74.3% (CI: 71.5-76.9%), human annotators, on average, outperformed LLMs with an accuracy of 79.5% (CI: 73.5-85.0%). With error analysis showing that the highest-performing LLMs continue to make mistakes in comprehension (56.6%) and calculator knowledge (8.1%), our findings emphasize that humans continue to surpass LLMs on complex clinical tasks such as calculator recommendation.