 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommending Clinical Trials for Online Patient Cases using Artificial Intelligence
Apr 15, 2025


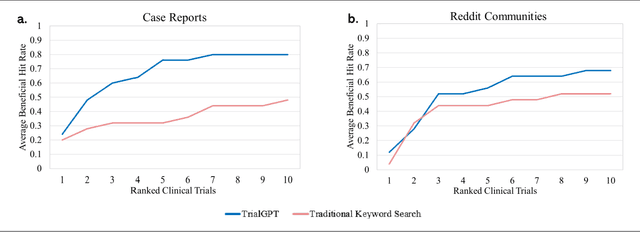
Clinical trials are crucial for assessing new treatments; however, recruitment challenges - such as limited awareness, complex eligibility criteria, and referral barriers - hinder their success. With the growth of online platforms, patients increasingly turn to social media and health communities for support, research, and advocacy, expanding recruitment pools and established enrollment pathways. Recognizing this potential, we utilized TrialGPT, a framework that leverages a large language model (LLM) as its backbone, to match 50 online patient cases (collected from published case reports and a social media website) to clinical trials and evaluate performance against traditional keyword-based searches. Our results show that TrialGPT outperforms traditional methods by 46% in identifying eligible trials, with each patient, on average, being eligible for around 7 trials. Additionally, our outreach efforts to case authors and trial organizers regarding these patient-trial matches yielded highly positive feedback, which we present from both perspectives.
A foundation model for human-AI collaboration in medical literature mining
Jan 27, 2025



Systematic literature review is essential for evidence-based medicine, requiring comprehensive analysis of clinical trial publications. However, the application of artificial intelligence (AI) models for medical literature mining has been limited by insufficient training and evaluation across broad therapeutic areas and diverse tasks. Here, we present LEADS, an AI foundation model for study search, screening, and data extraction from medical literature. The model is trained on 633,759 instruction data points in LEADSInstruct, curated from 21,335 systematic reviews, 453,625 clinical trial publications, and 27,015 clinical trial registries. We showed that LEADS demonstrates consistent improvements over four cutting-edge generic large language models (LLMs) on six tasks. Furthermore, LEADS enhances expert workflows by providing supportive references following expert requests, streamlining processes while maintaining high-quality results. A study with 16 clinicians and medical researchers from 14 different institutions revealed that experts collaborating with LEADS achieved a recall of 0.81 compared to 0.77 experts working alone in study selection, with a time savings of 22.6%. In data extraction tasks, experts using LEADS achieved an accuracy of 0.85 versus 0.80 without using LEADS, alongside a 26.9% time savings. These findings highlight the potential of specialized medical literature foundation models to outperform generic models, delivering significant quality and efficiency benefits when integrated into expert workflows for medical literature mining.
Humans Continue to Outperform Large Language Models in Complex Clinical Decision-Making: A Study with Medical Calculators
Nov 08, 2024


Although large language models (LLMs) have been assessed for general medical knowledge using medical licensing exams, their ability to effectively support clinical decision-making tasks, such as selecting and using medical calculators, remains uncertain. Here, we evaluate the capability of both medical trainees and LLMs to recommend medical calculators in response to various multiple-choice clinical scenarios such as risk stratification, prognosis, and disease diagnosis. We assessed eight LLMs, including open-source, proprietary, and domain-specific models, with 1,009 question-answer pairs across 35 clinical calculators and measured human performance on a subset of 100 questions. While the highest-performing LLM, GPT-4o, provided an answer accuracy of 74.3% (CI: 71.5-76.9%), human annotators, on average, outperformed LLMs with an accuracy of 79.5% (CI: 73.5-85.0%). With error analysis showing that the highest-performing LLMs continue to make mistakes in comprehension (56.6%) and calculator knowledge (8.1%), our findings emphasize that humans continue to surpass LLMs on complex clinical tasks such as calculator recommendation.
Beyond Multiple-Choice Accuracy: Real-World Challenges of Implementing Large Language Models in Healthcare
Oct 24, 2024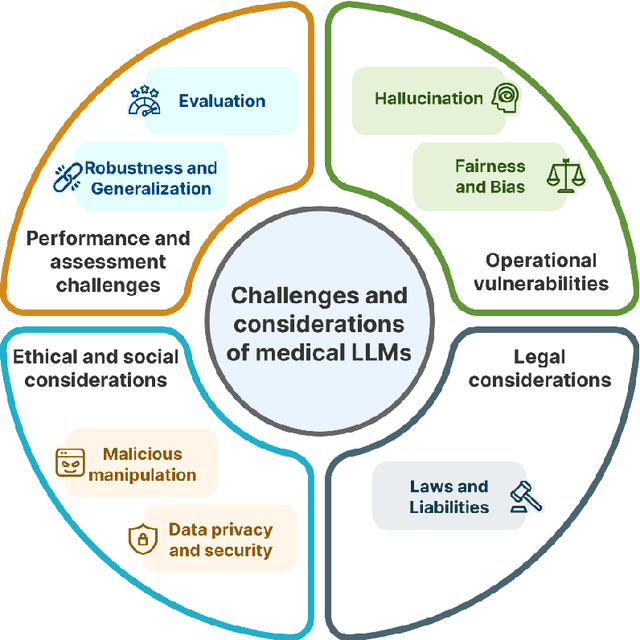
Large Language Models (LLMs) have gained significant attention in the medical domain for their human-level capabilities, leading to increased efforts to explore their potential in various healthcare applications. However, despite such a promising future, there are multiple challenges and obstacles that remain for their real-world uses in practical settings. This work discusses key challenges for LLMs in medical applications from four unique aspects: operational vulnerabilities, ethical and social considerations, performance and assessment difficulties, and legal and regulatory compliance. Addressing these challenges is crucial for leveraging LLMs to their full potential and ensuring their responsible integration into healthcare.
Demystifying Large Language Models for Medicine: A Primer
Oct 24, 2024



Large language models (LLMs) represent a transformative class of AI tools capable of revolutionizing various aspects of healthcare by generating human-like responses across diverse contexts and adapting to novel tasks following human instructions. Their potential application spans a broad range of medical tasks, such as clinical documentation, matching patients to clinical trials, and answering medical questions. In this primer paper, we propose an actionable guideline to help healthcare professionals more efficiently utilize LLMs in their work, along with a set of best practices. This approach consists of several main phases, including formulating the task, choosing LLMs, prompt engineering, fine-tuning, and deployment. We start with the discussion of critical considerations in identifying healthcare tasks that align with the core capabilities of LLMs and selecting models based on the selected task and data, performance requirements, and model interface. We then review the strategies, such as prompt engineering and fine-tuning, to adapt standard LLMs to specialized medical tasks. Deployment considerations, including regulatory compliance, ethical guidelines, and continuous monitoring for fairness and bias, are also discussed. By providing a structured step-by-step methodology, this tutorial aims to equip healthcare professionals with the tools necessary to effectively integrate LLMs into clinical practice, ensuring that these powerful technologies are applied in a safe, reliable, and impactful manner.