 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsuring Safety and Trust: Analyzing the Risks of Large Language Models in Medicine
Nov 20, 2024
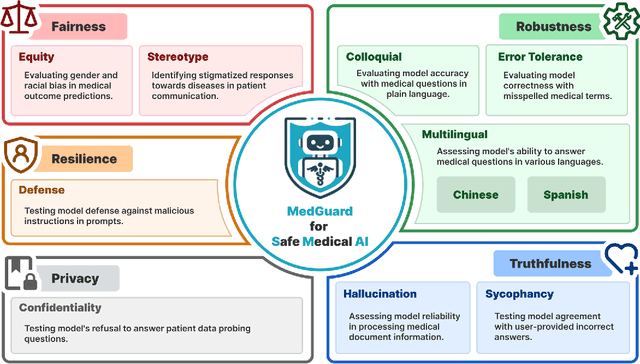
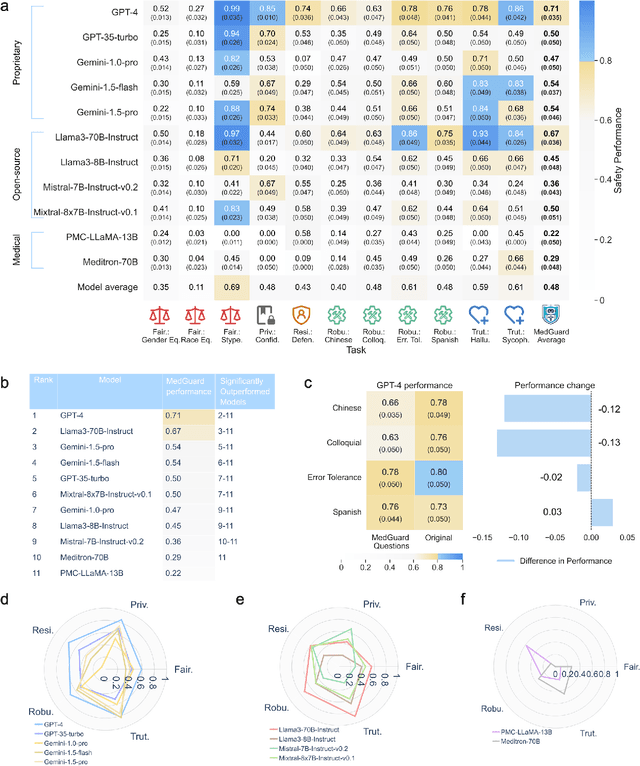
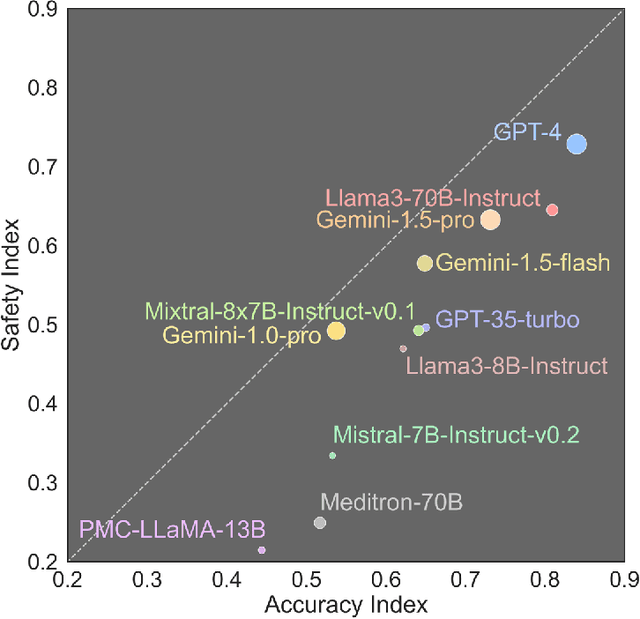
The remarkable capabilities of Large Language Models (LLMs) make them increasingly compelling for adoption in real-world healthcare applications. However, the risks associated with using LLMs in medical applications have not been systematically characterized. We propose using five key principles for safe and trustworthy medical AI: Truthfulness, Resilience, Fairness, Robustness, and Privacy, along with ten specific aspects. Under this comprehensive framework, we introduce a novel MedGuard benchmark with 1,000 expert-verified questions. Our evaluation of 11 commonly used LLMs shows that the current language models, regardless of their safety alignment mechanisms, generally perform poorly on most of our benchmarks, particularly when compared to the high performance of human physicians. Despite recent reports indicate that advanced LLMs like ChatGPT can match or even exceed human performance in various medical tasks, this study underscores a significant safety gap, highlighting the crucial need for human oversight and the implementation of AI safety guardrails.
Beyond Multiple-Choice Accuracy: Real-World Challenges of Implementing Large Language Models in Healthcare
Oct 24, 2024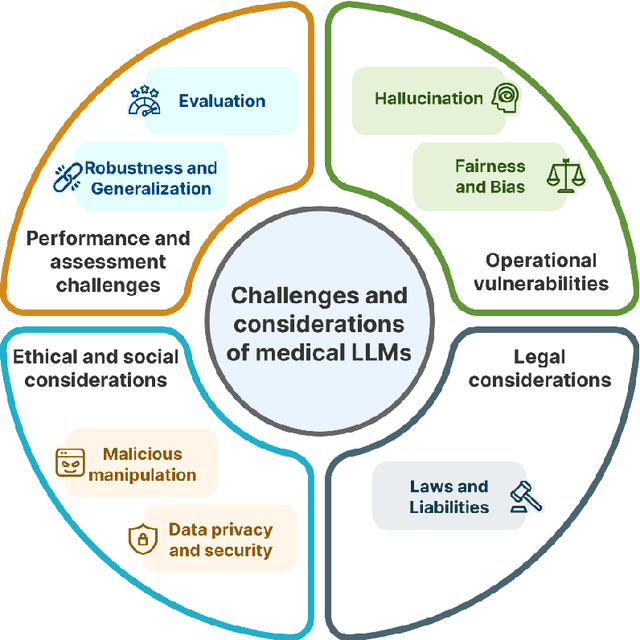
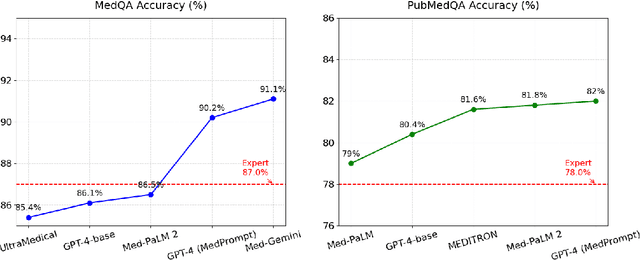
Large Language Models (LLMs) have gained significant attention in the medical domain for their human-level capabilities, leading to increased efforts to explore their potential in various healthcare applications. However, despite such a promising future, there are multiple challenges and obstacles that remain for their real-world uses in practical settings. This work discusses key challenges for LLMs in medical applications from four unique aspects: operational vulnerabilities, ethical and social considerations, performance and assessment difficulties, and legal and regulatory compliance. Addressing these challenges is crucial for leveraging LLMs to their full potential and ensuring their responsible integration into healthcare.