 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-Bench: A Benchmark for Multimodal Lesion Understanding in Computed Tomography
Feb 16, 2026Artificial intelligence (AI) can automatically delineate lesions on computed tomography (CT) and generate radiology report content, yet progress is limited by the scarcity of publicly available CT datasets with lesion-level annotations. To bridge this gap, we introduce CT-Bench, a first-of-its-kind benchmark dataset comprising two components: a Lesion Image and Metadata Set containing 20,335 lesions from 7,795 CT studies with bounding boxes, descriptions, and size information, and a multitask visual question answering benchmark with 2,850 QA pairs covering lesion localization, description, size estimation, and attribute categorization. Hard negative examples are included to reflect real-world diagnostic challenges. We evaluate multiple state-of-the-art multimodal models, including vision-language and medical CLIP variants, by comparing their performance to radiologist assessments, demonstrating the value of CT-Bench as a comprehensive benchmark for lesion analysis. Moreover, fine-tuning models on the Lesion Image and Metadata Set yields significant performance gains across both components, underscoring the clinical utility of CT-Bench.
Ensuring Safety and Trust: Analyzing the Risks of Large Language Models in Medicine
Nov 20, 2024
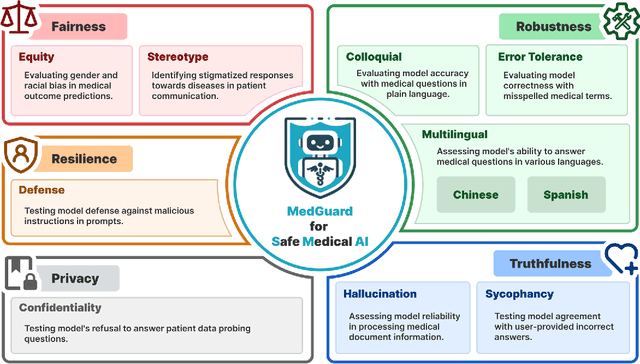
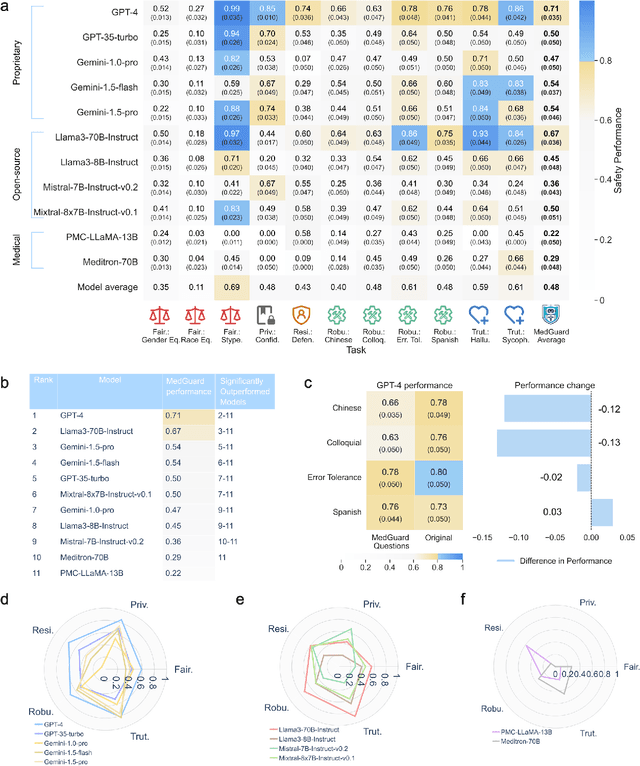
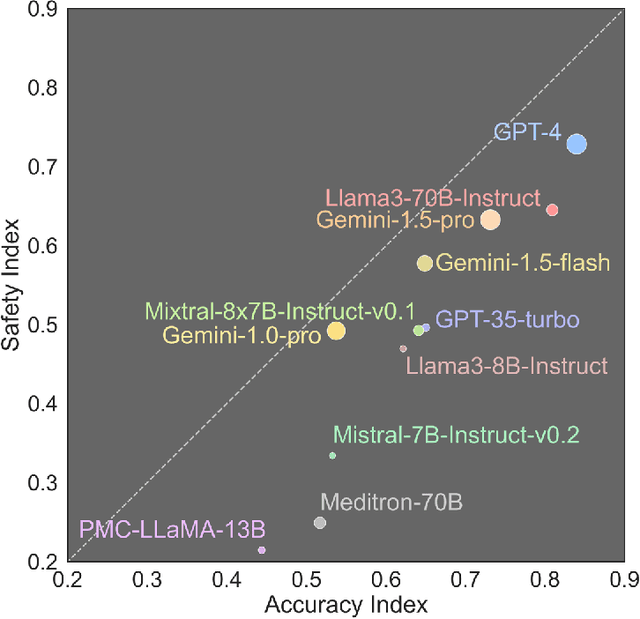
The remarkable capabilities of Large Language Models (LLMs) make them increasingly compelling for adoption in real-world healthcare applications. However, the risks associated with using LLMs in medical applications have not been systematically characterized. We propose using five key principles for safe and trustworthy medical AI: Truthfulness, Resilience, Fairness, Robustness, and Privacy, along with ten specific aspects. Under this comprehensive framework, we introduce a novel MedGuard benchmark with 1,000 expert-verified questions. Our evaluation of 11 commonly used LLMs shows that the current language models, regardless of their safety alignment mechanisms, generally perform poorly on most of our benchmarks, particularly when compared to the high performance of human physicians. Despite recent reports indicate that advanced LLMs like ChatGPT can match or even exceed human performance in various medical tasks, this study underscores a significant safety gap, highlighting the crucial need for human oversight and the implementation of AI safety guardrails.
Demystifying Large Language Models for Medicine: A Primer
Oct 24, 2024



Large language models (LLMs) represent a transformative class of AI tools capable of revolutionizing various aspects of healthcare by generating human-like responses across diverse contexts and adapting to novel tasks following human instructions. Their potential application spans a broad range of medical tasks, such as clinical documentation, matching patients to clinical trials, and answering medical questions. In this primer paper, we propose an actionable guideline to help healthcare professionals more efficiently utilize LLMs in their work, along with a set of best practices. This approach consists of several main phases, including formulating the task, choosing LLMs, prompt engineering, fine-tuning, and deployment. We start with the discussion of critical considerations in identifying healthcare tasks that align with the core capabilities of LLMs and selecting models based on the selected task and data, performance requirements, and model interface. We then review the strategies, such as prompt engineering and fine-tuning, to adapt standard LLMs to specialized medical tasks. Deployment considerations, including regulatory compliance, ethical guidelines, and continuous monitoring for fairness and bias, are also discussed. By providing a structured step-by-step methodology, this tutorial aims to equip healthcare professionals with the tools necessary to effectively integrate LLMs into clinical practice, ensuring that these powerful technologies are applied in a safe, reliable, and impactful manner.
MedCalc-Bench: Evaluating Large Language Models for Medical Calculations
Jun 17, 2024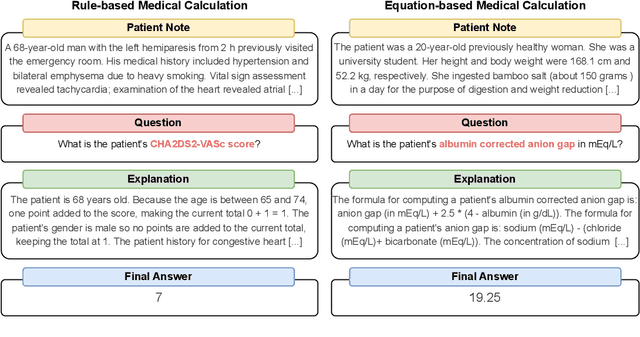
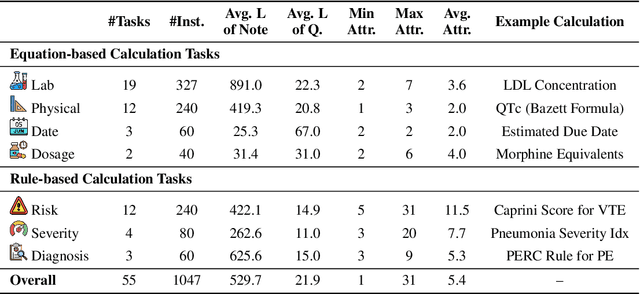
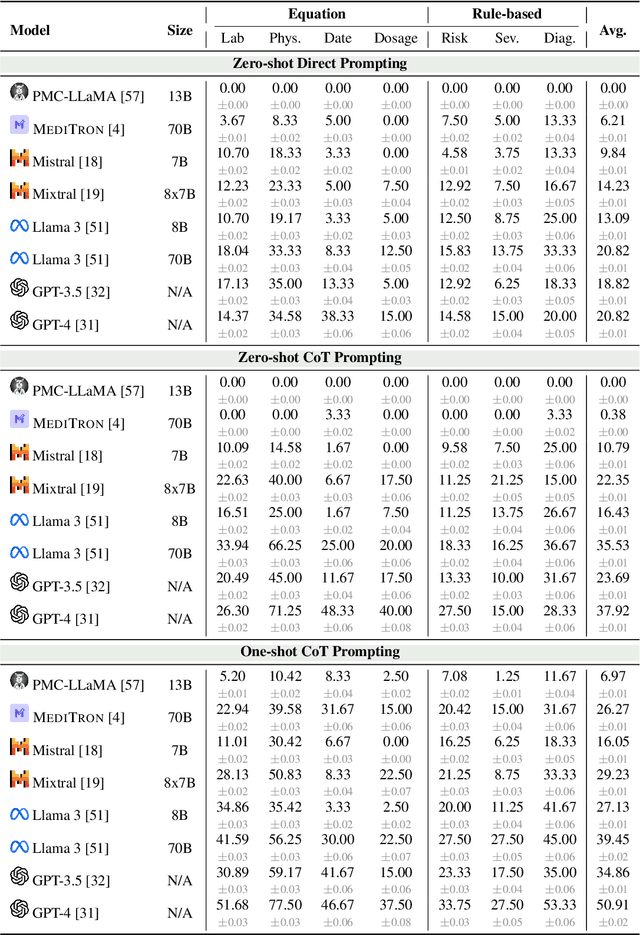
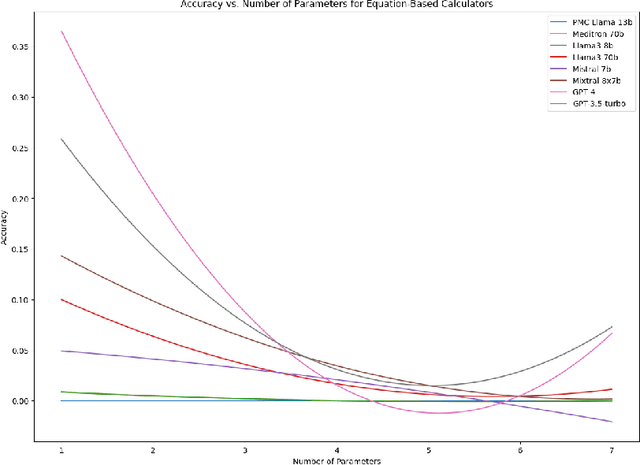
As opposed to evaluating computation and logic-based reasoning, current bench2 marks for evaluating large language models (LLMs) in medicine are primarily focused on question-answering involving domain knowledge and descriptive rea4 soning. While such qualitative capabilities are vital to medical diagnosis, in real5 world scenarios, doctors frequently use clinical calculators that follow quantitative equations and rule-based reasoning paradigms for evidence-based decision support. To this end, we propose MedCalc-Bench, a first-of-its-kind dataset focused on evaluating the medical calculation capability of LLMs. MedCalc-Bench contains an evaluation set of over 1000 manually reviewed instances from 55 different medical calculation tasks. Each instance in MedCalc-Bench consists of a patient note, a question requesting to compute a specific medical value, a ground truth answer, and a step-by-step explanation showing how the answer is obtained. While our evaluation results show the potential of LLMs in this area, none of them are effective enough for clinical settings. Common issues include extracting the incorrect entities, not using the correct equation or rules for a calculation task, or incorrectly performing the arithmetic for the computation. We hope our study highlights the quantitative knowledge and reasoning gaps in LLMs within medical settings, encouraging future improvements of LLMs for various clinical calculation tasks.