 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentless: Demystifying LLM-based Software Engineering Agents
Jul 01, 2024



Recent advancements in large language models (LLMs) have significantly advanced the automation of software development tasks, including code synthesis, program repair, and test generation. More recently, researchers and industry practitioners have developed various autonomous LLM agents to perform end-to-end software development tasks. These agents are equipped with the ability to use tools, run commands, observe feedback from the environment, and plan for future actions. However, the complexity of these agent-based approaches, together with the limited abilities of current LLMs, raises the following question: Do we really have to employ complex autonomous software agents? To attempt to answer this question, we build Agentless -- an agentless approach to automatically solve software development problems. Compared to the verbose and complex setup of agent-based approaches, Agentless employs a simplistic two-phase process of localization followed by repair, without letting the LLM decide future actions or operate with complex tools. Our results on the popular SWE-bench Lite benchmark show that surprisingly the simplistic Agentless is able to achieve both the highest performance (27.33%) and lowest cost (\$0.34) compared with all existing open-source software agents! Furthermore, we manually classified the problems in SWE-bench Lite and found problems with exact ground truth patch or insufficient/misleading issue descriptions. As such, we construct SWE-bench Lite-S by excluding such problematic issues to perform more rigorous evaluation and comparison. Our work highlights the current overlooked potential of a simple, interpretable technique in autonomous software development. We hope Agentless will help reset the baseline, starting point, and horizon for autonomous software agents, and inspire future work along this crucial direction.
MedCalc-Bench: Evaluating Large Language Models for Medical Calculations
Jun 17, 2024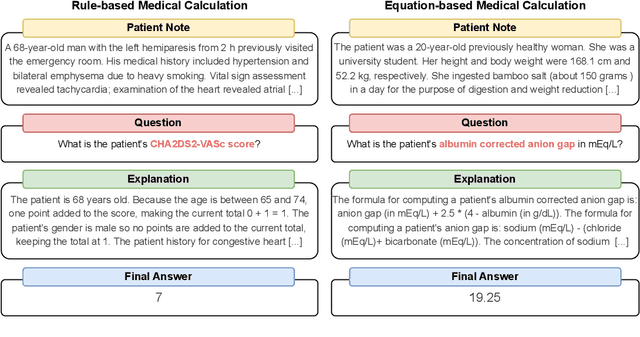
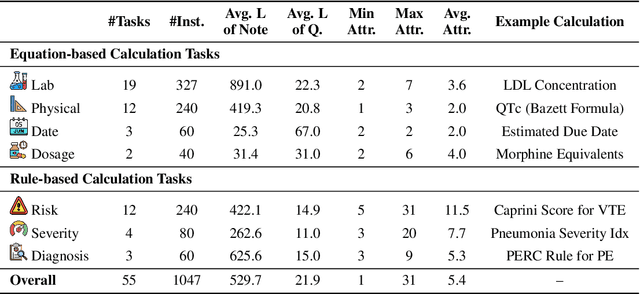
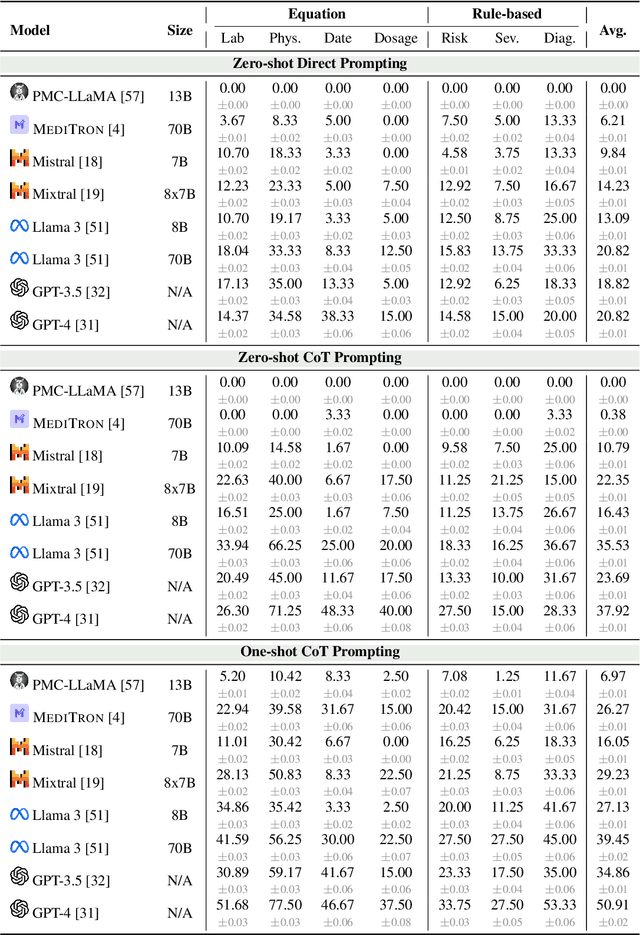
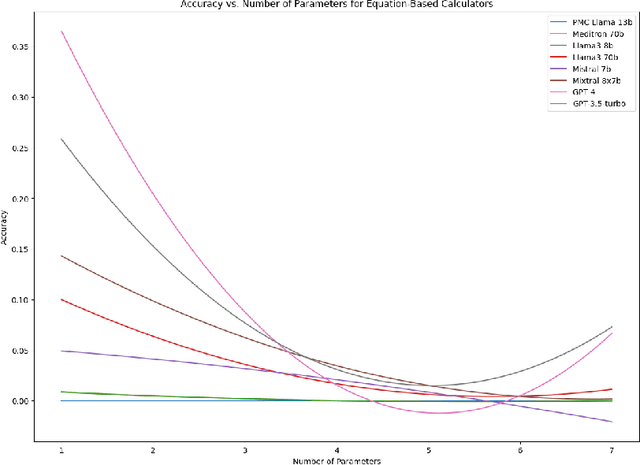
As opposed to evaluating computation and logic-based reasoning, current bench2 marks for evaluating large language models (LLMs) in medicine are primarily focused on question-answering involving domain knowledge and descriptive rea4 soning. While such qualitative capabilities are vital to medical diagnosis, in real5 world scenarios, doctors frequently use clinical calculators that follow quantitative equations and rule-based reasoning paradigms for evidence-based decision support. To this end, we propose MedCalc-Bench, a first-of-its-kind dataset focused on evaluating the medical calculation capability of LLMs. MedCalc-Bench contains an evaluation set of over 1000 manually reviewed instances from 55 different medical calculation tasks. Each instance in MedCalc-Bench consists of a patient note, a question requesting to compute a specific medical value, a ground truth answer, and a step-by-step explanation showing how the answer is obtained. While our evaluation results show the potential of LLMs in this area, none of them are effective enough for clinical settings. Common issues include extracting the incorrect entities, not using the correct equation or rules for a calculation task, or incorrectly performing the arithmetic for the computation. We hope our study highlights the quantitative knowledge and reasoning gaps in LLMs within medical settings, encouraging future improvements of LLMs for various clinical calculation tasks.