 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentless: Demystifying LLM-based Software Engineering Agents
Jul 01, 2024



Recent advancements in large language models (LLMs) have significantly advanced the automation of software development tasks, including code synthesis, program repair, and test generation. More recently, researchers and industry practitioners have developed various autonomous LLM agents to perform end-to-end software development tasks. These agents are equipped with the ability to use tools, run commands, observe feedback from the environment, and plan for future actions. However, the complexity of these agent-based approaches, together with the limited abilities of current LLMs, raises the following question: Do we really have to employ complex autonomous software agents? To attempt to answer this question, we build Agentless -- an agentless approach to automatically solve software development problems. Compared to the verbose and complex setup of agent-based approaches, Agentless employs a simplistic two-phase process of localization followed by repair, without letting the LLM decide future actions or operate with complex tools. Our results on the popular SWE-bench Lite benchmark show that surprisingly the simplistic Agentless is able to achieve both the highest performance (27.33%) and lowest cost (\$0.34) compared with all existing open-source software agents! Furthermore, we manually classified the problems in SWE-bench Lite and found problems with exact ground truth patch or insufficient/misleading issue descriptions. As such, we construct SWE-bench Lite-S by excluding such problematic issues to perform more rigorous evaluation and comparison. Our work highlights the current overlooked potential of a simple, interpretable technique in autonomous software development. We hope Agentless will help reset the baseline, starting point, and horizon for autonomous software agents, and inspire future work along this crucial direction.
NExT: Teaching Large Language Models to Reason about Code Execution
Apr 23, 2024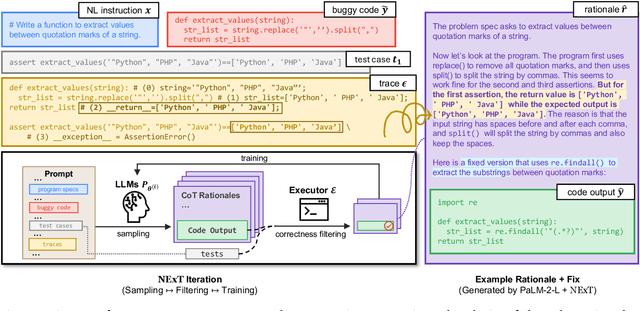



A fundamental skill among human developers is the ability to understand and reason about program execution. As an example, a programmer can mentally simulate code execution in natural language to debug and repair code (aka. rubber duck debugging). However, large language models (LLMs) of code are typically trained on the surface textual form of programs, thus may lack a semantic understanding of how programs execute at run-time. To address this issue, we propose NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales. Specifically, NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation. Experiments on program repair tasks based on MBPP and HumanEval demonstrate that NExT improves the fix rate of a PaLM 2 model, by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters. Our model can also generalize to scenarios where program traces are absent at test-time.
Top Leaderboard Ranking = Top Coding Proficiency, Always? EvoEval: Evolving Coding Benchmarks via LLM
Mar 28, 2024LLMs have become the go-to choice for code generation tasks, with an exponential increase in the training, development, and usage of LLMs specifically for code generation. To evaluate the ability of LLMs on code, both academic and industry practitioners rely on popular handcrafted benchmarks. However, prior benchmarks contain only a very limited set of problems, both in quantity and variety. Further, due to popularity and age, many benchmarks are prone to data leakage where example solutions can be readily found on the web and thus potentially in training data. Such limitations inevitably lead us to inquire: Is the leaderboard performance on existing benchmarks reliable and comprehensive enough to measure the program synthesis ability of LLMs? To address this, we introduce EvoEval -- a program synthesis benchmark suite created by evolving existing benchmarks into different targeted domains for a comprehensive evaluation of LLM coding abilities. Our study on 51 LLMs shows that compared to the high performance obtained on standard benchmarks like HumanEval, there is a significant drop in performance (on average 39.4%) when using EvoEval. Additionally, the decrease in performance can range from 19.6% to 47.7%, leading to drastic ranking changes amongst LLMs and showing potential overfitting of existing benchmarks. Furthermore, we showcase various insights, including the brittleness of instruction-following models when encountering rewording or subtle changes as well as the importance of learning problem composition and decomposition. EvoEval not only provides comprehensive benchmarks, but can be used to further evolve arbitrary problems to keep up with advances and the ever-changing landscape of LLMs for code. We have open-sourced our benchmarks, tools, and complete LLM generations at https://github.com/evo-eval/evoeval
White-box Compiler Fuzzing Empowered by Large Language Models
Oct 24, 2023



Compiler correctness is crucial, as miscompilation falsifying the program behaviors can lead to serious consequences. In the literature, fuzzing has been extensively studied to uncover compiler defects. However, compiler fuzzing remains challenging: Existing arts focus on black- and grey-box fuzzing, which generates tests without sufficient understanding of internal compiler behaviors. As such, they often fail to construct programs to exercise conditions of intricate optimizations. Meanwhile, traditional white-box techniques are computationally inapplicable to the giant codebase of compilers. Recent advances demonstrate that Large Language Models (LLMs) excel in code generation/understanding tasks and have achieved state-of-the-art performance in black-box fuzzing. Nonetheless, prompting LLMs with compiler source-code information remains a missing piece of research in compiler testing. To this end, we propose WhiteFox, the first white-box compiler fuzzer using LLMs with source-code information to test compiler optimization. WhiteFox adopts a dual-model framework: (i) an analysis LLM examines the low-level optimization source code and produces requirements on the high-level test programs that can trigger the optimization; (ii) a generation LLM produces test programs based on the summarized requirements. Additionally, optimization-triggering tests are used as feedback to further enhance the test generation on the fly. Our evaluation on four popular compilers shows that WhiteFox can generate high-quality tests to exercise deep optimizations requiring intricate conditions, practicing up to 80 more optimizations than state-of-the-art fuzzers. To date, WhiteFox has found in total 96 bugs, with 80 confirmed as previously unknown and 51 already fixed. Beyond compiler testing, WhiteFox can also be adapted for white-box fuzzing of other complex, real-world software systems in general.
Coverage-Guided Tensor Compiler Fuzzing with Joint IR-Pass Mutation
Feb 21, 2022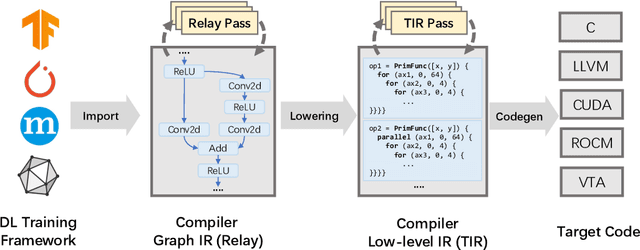

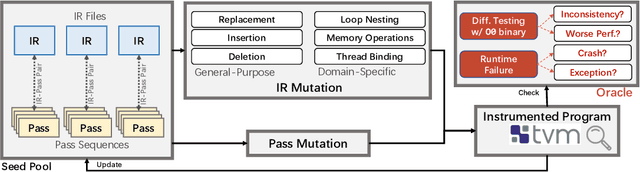

In the past decade, Deep Learning (DL) systems have been widely deployed in various domains to facilitate our daily life. Meanwhile, it is extremely challenging to ensure the correctness of DL systems (e.g., due to their intrinsic nondeterminism), and bugs in DL systems can cause serious consequences and may even threaten human lives. In the literature, researchers have explored various techniques to test, analyze, and verify DL models, since their quality directly affects the corresponding system behaviors. Recently, researchers have also proposed novel techniques for testing the underlying operator-level DL libraries (such as TensorFlow and PyTorch), which provide general binary implementations for each high-level DL operator for running various DL models on many platforms. However, there is still limited work targeting the reliability of the emerging tensor compilers, which aim to directly compile high-level tensor computation graphs into high-performance binaries for better efficiency, portability, and scalability. In this paper, we target the important problem of tensor compiler testing, and have proposed Tzer, a practical fuzzing technique for the widely used TVM tensor compiler. Tzer focuses on mutating the low-level Intermediate Representation (IR) for TVM due to the limited mutation space for the high-level IR. More specifically, Tzer leverages both general-purpose and tensor-compiler-specific mutators guided by coverage feedback for evolutionary IR mutation; furthermore, Tzer also performs pass mutation in tandem with IR mutation for more effective fuzzing. Our results show that Tzer substantially outperforms existing fuzzing techniques on tensor compiler testing, with 75% higher coverage and 50% more valuable tests than the 2nd-best technique. To date, Tzer has detected 49 previously unknown bugs for TVM, with 37 bugs confirmed and 25 bugs fixed (PR merged).