 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVICPRESS: Joint KV-Cache Compression and Eviction for Efficient LLM Serving
Dec 16, 2025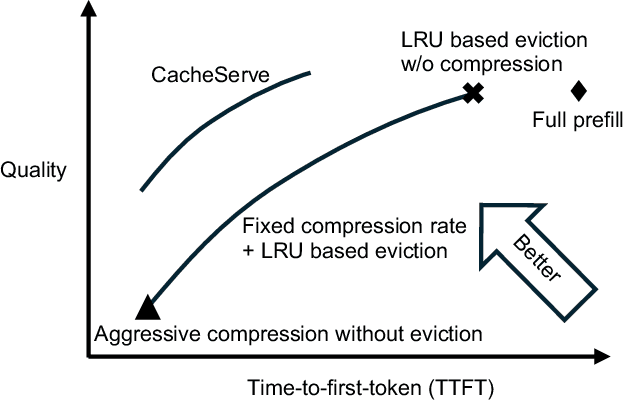
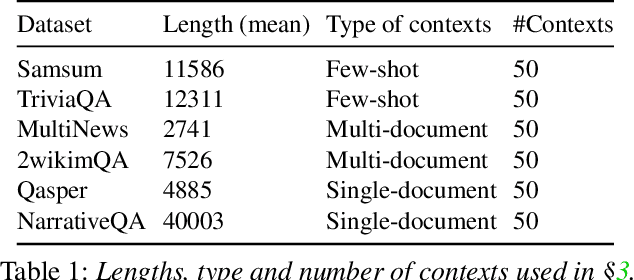
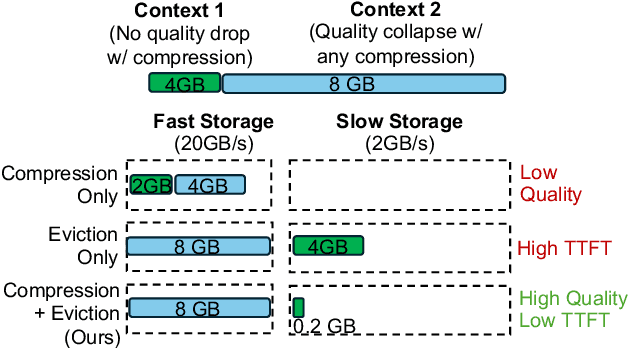
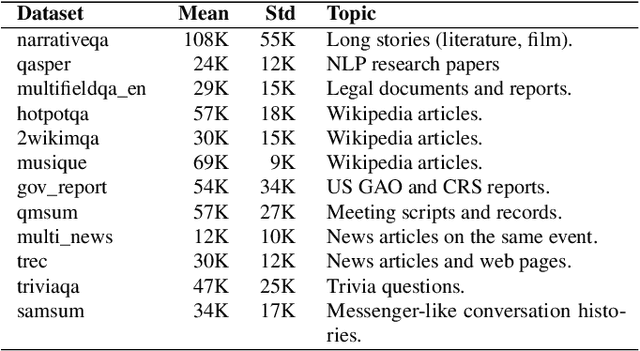
Reusing KV cache is essential for high efficiency of Large Language Model (LLM) inference systems. With more LLM users, the KV cache footprint can easily exceed GPU memory capacity, so prior work has proposed to either evict KV cache to lower-tier storage devices, or compress KV cache so that more KV cache can be fit in the fast memory. However, prior work misses an important opportunity: jointly optimizing the eviction and compression decisions across all KV caches to minimize average generation latency without hurting quality. We propose EVICPRESS, a KV-cache management system that applies lossy compression and adaptive eviction to KV cache across multiple storage tiers. Specifically, for each KV cache of a context, EVICPRESS considers the effect of compression and eviction of the KV cache on the average generation quality and delay across all contexts as a whole. To achieve this, EVICPRESS proposes a unified utility function that quantifies the effect of quality and delay of the lossy compression or eviction. To this end, EVICPRESS's profiling module periodically updates the utility function scores on all possible eviction-compression configurations for all contexts and places KV caches using a fast heuristic to rearrange KV caches on all storage tiers, with the goal of maximizing the utility function scores on each storage tier. Compared to the baselines that evict KV cache or compress KV cache, EVICPRESS achieves higher KV-cache hit rates on fast devices, i.e., lower delay, while preserving high generation quality by applying conservative compression to contexts that are sensitive to compression errors. Evaluation on 12 datasets and 5 models demonstrates that EVICPRESS achieves up to 2.19x faster time-to-first-token (TTFT) at equivalent generation quality.
Optimal Beamforming for Multi-Target Multi-User ISAC Exploiting Prior Information: How Many Sensing Beams Are Needed?
Mar 05, 2025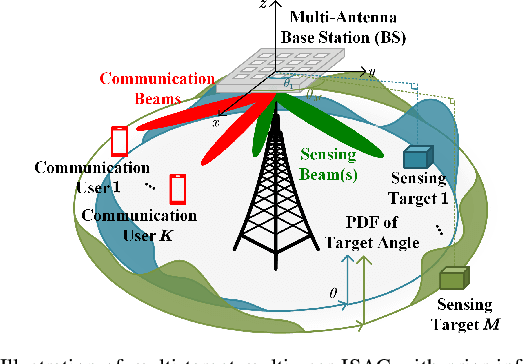
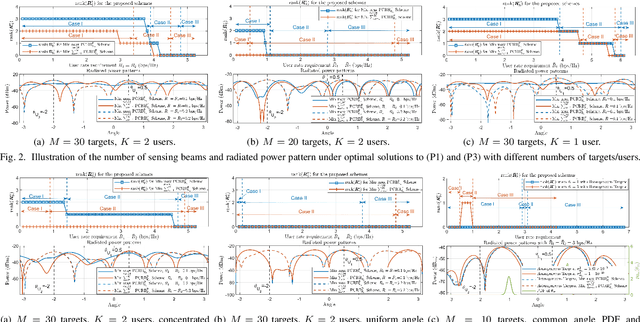


This paper studies a multi-target multi-user integrated sensing and communication (ISAC) system where a multi-antenna base station (BS) communicates with multiple single-antenna users in the downlink and senses the unknown and random angle information of multiple targets based on their reflected echo signals at the BS receiver as well as their prior probability information. We focus on a general beamforming structure with both communication beams and dedicated sensing beams, whose design is highly non-trivial as more sensing beams provide more flexibility in sensing, but introduce extra interference to communication. To resolve this trade-off, we first characterize the periodic posterior Cram\'er-Rao bound (PCRB) as a lower bound of the mean-cyclic error (MCE) in multi-target sensing. Then, we optimize the beamforming to minimize the maximum periodic PCRB among all targets to ensure fairness, subject to individual communication rate constraints at multiple users. Despite the non-convexity of this problem, we propose a general construction method for the optimal solution by leveraging semi-definite relaxation (SDR), and derive a general bound on the number of sensing beams needed. Moreover, we unveil specific structures of the optimal solution in various cases, where tighter bounds on the number of sensing beams needed are derived (e.g., no or at most one sensing beam is needed under stringent rate constraints or with homogeneous targets). Next, we study the beamforming optimization to minimize the sum periodic PCRB under user rate constraints. By applying SDR, we propose a general construction method for the optimal solution and its specific structures which yield lower computational complexities. We derive a general bound and various tighter bounds on the number of sensing beams needed. Numerical results validate our analysis and effectiveness of our proposed beamforming designs.
Preconditioned Subspace Langevin Monte Carlo
Dec 18, 2024


We develop a new efficient method for high-dimensional sampling called Subspace Langevin Monte Carlo. The primary application of these methods is to efficiently implement Preconditioned Langevin Monte Carlo. To demonstrate the usefulness of this new method, we extend ideas from subspace descent methods in Euclidean space to solving a specific optimization problem over Wasserstein space. Our theoretical analysis demonstrates the advantageous convergence regimes of the proposed method, which depend on relative conditioning assumptions common to mirror descent methods. We back up our theory with experimental evidence on sampling from an ill-conditioned Gaussian distribution.
LLMSteer: Improving Long-Context LLM Inference by Steering Attention on Reused Contexts
Nov 21, 2024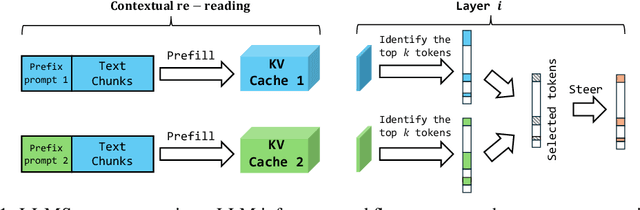
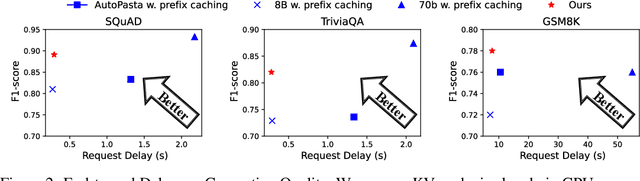
As large language models (LLMs) show impressive performance on complex tasks, they still struggle with longer contextual understanding and high computational costs. To balance efficiency and quality, we introduce LLMSteer, a fine-tuning-free framework that enhances LLMs through query-independent attention steering. Tested on popular LLMs and datasets, LLMSteer narrows the performance gap with baselines by 65.9% and reduces the runtime delay by up to 4.8x compared to recent attention steering methods.
Optimal Transmit Signal Design for Multi-Target MIMO Sensing Exploiting Prior Information
Jun 21, 2024


In this paper, we study the transmit signal optimization in a multiple-input multiple-output (MIMO) radar system for sensing the angle information of multiple targets via their reflected echo signals. We consider a challenging and practical scenario where the angles to be sensed are unknown and random, while their probability information is known a priori for exploitation. First, we establish an analytical framework to quantify the multi-target sensing performance exploiting prior distribution information, by deriving the posterior Cram\'{e}r-Rao bound (PCRB) as a lower bound of the mean-squared error (MSE) matrix in sensing multiple unknown and random angles. Then, we formulate and study the transmit sample covariance matrix optimization problem to minimize the PCRB for the sum MSE in estimating all angles. By leveraging Lagrange duality theory, we analytically prove that the optimal transmit covariance matrix has a rank-one structure, despite the multiple angles to be sensed and the continuous feasible range of each angle. Moreover, we propose a sum-of-ratios iterative algorithm which can obtain the optimal solution to the PCRB-minimization problem with low complexity. Numerical results validate our results and the superiority of our proposed design over benchmark schemes.
CacheBlend: Fast Large Language Model Serving with Cached Knowledge Fusion
May 26, 2024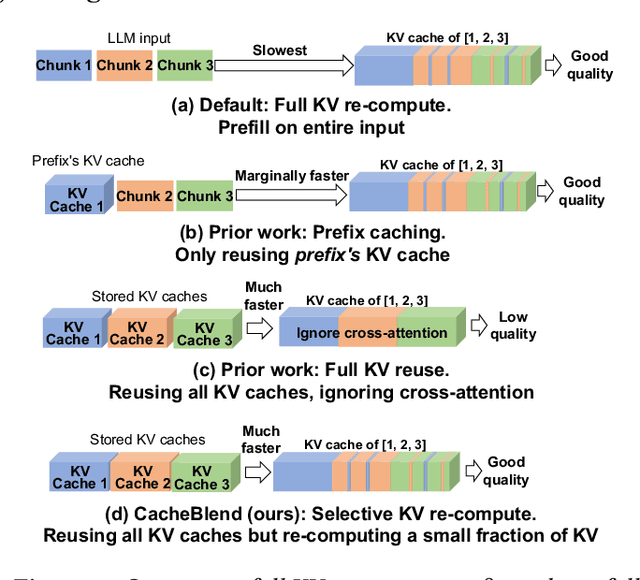
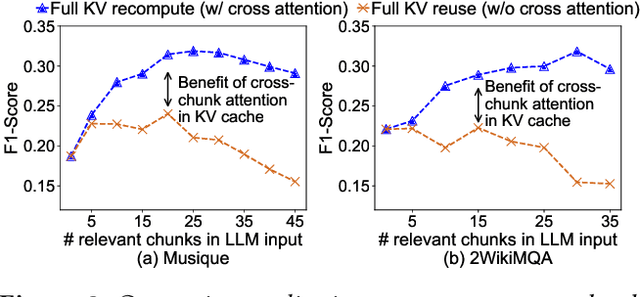
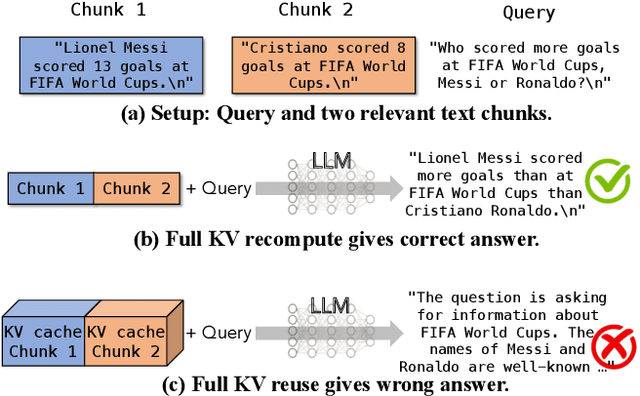
Large language models (LLMs) often incorporate multiple text chunks in their inputs to provide the necessary contexts. To speed up the prefill of the long LLM inputs, one can pre-compute the KV cache of a text and re-use the KV cache when the context is reused as the prefix of another LLM input. However, the reused text chunks are not always the input prefix, and when they are not, their precomputed KV caches cannot be directly used since they ignore the text's cross-attention with the preceding text in the LLM input. Thus, the benefits of reusing KV caches remain largely unrealized. This paper tackles just one question: when an LLM input contains multiple text chunks, how to quickly combine their precomputed KV caches in order to achieve the same generation quality as the expensive full prefill (i.e., without reusing KV cache)? We present CacheBlend, a scheme that reuses the pre-computed KV caches, regardless prefix or not, and selectively recomputes the KV values of a small subset of tokens to partially update each reused KV cache. In the meantime,the small extra delay for recomputing some tokens can be pipelined with the retrieval of KV caches within the same job,allowing CacheBlend to store KV caches in slower devices with more storage capacity while retrieving them without increasing the inference delay. By comparing CacheBlend with the state-of-the-art KV cache reusing schemes on three open-source LLMs of various sizes and four popular benchmark datasets of different tasks, we show that CacheBlend reduces time-to-first-token (TTFT) by 2.2-3.3X and increases the inference throughput by 2.8-5X, compared with full KV recompute, without compromising generation quality or incurring more storage cost.
White-box Compiler Fuzzing Empowered by Large Language Models
Oct 24, 2023



Compiler correctness is crucial, as miscompilation falsifying the program behaviors can lead to serious consequences. In the literature, fuzzing has been extensively studied to uncover compiler defects. However, compiler fuzzing remains challenging: Existing arts focus on black- and grey-box fuzzing, which generates tests without sufficient understanding of internal compiler behaviors. As such, they often fail to construct programs to exercise conditions of intricate optimizations. Meanwhile, traditional white-box techniques are computationally inapplicable to the giant codebase of compilers. Recent advances demonstrate that Large Language Models (LLMs) excel in code generation/understanding tasks and have achieved state-of-the-art performance in black-box fuzzing. Nonetheless, prompting LLMs with compiler source-code information remains a missing piece of research in compiler testing. To this end, we propose WhiteFox, the first white-box compiler fuzzer using LLMs with source-code information to test compiler optimization. WhiteFox adopts a dual-model framework: (i) an analysis LLM examines the low-level optimization source code and produces requirements on the high-level test programs that can trigger the optimization; (ii) a generation LLM produces test programs based on the summarized requirements. Additionally, optimization-triggering tests are used as feedback to further enhance the test generation on the fly. Our evaluation on four popular compilers shows that WhiteFox can generate high-quality tests to exercise deep optimizations requiring intricate conditions, practicing up to 80 more optimizations than state-of-the-art fuzzers. To date, WhiteFox has found in total 96 bugs, with 80 confirmed as previously unknown and 51 already fixed. Beyond compiler testing, WhiteFox can also be adapted for white-box fuzzing of other complex, real-world software systems in general.
CacheGen: Fast Context Loading for Language Model Applications
Oct 11, 2023



As large language models (LLMs) take on more complex tasks, their inputs incorporate longer contexts to respond to questions that require domain knowledge or user-specific conversational histories. Yet, using long contexts poses a challenge for responsive LLM systems, as nothing can be generated until all the contexts are fetched to and processed by the LLM. Existing systems optimize only the computation delay in context processing (e.g., by caching intermediate key-value features of the text context) but often cause longer network delays in context fetching (e.g., key-value features consume orders of magnitude larger bandwidth than the text context). This paper presents CacheGen to minimize the delays in fetching and processing contexts for LLMs. CacheGen reduces the bandwidth needed for transmitting long contexts' key-value (KV) features through a novel encoder that compresses KV features into more compact bitstream representations. The encoder combines adaptive quantization with a tailored arithmetic coder, taking advantage of the KV features' distributional properties, such as locality across tokens. Furthermore, CacheGen minimizes the total delay in fetching and processing a context by using a controller that determines when to load the context as compressed KV features or raw text and picks the appropriate compression level if loaded as KV features. We test CacheGen on three models of various sizes and three datasets of different context lengths. Compared to recent methods that handle long contexts, CacheGen reduces bandwidth usage by 3.7-4.3x and the total delay in fetching and processing contexts by 2.7-3x while maintaining similar LLM performance on various tasks as loading the text contexts.
A pruning method based on the dissimilarity of angle among channels and filters
Oct 29, 2022



Convolutional Neural Network (CNN) is more and more widely used in various fileds, and its computation and memory-demand are also increasing significantly. In order to make it applicable to limited conditions such as embedded application, network compression comes out. Among them, researchers pay more attention to network pruning. In this paper, we encode the convolution network to obtain the similarity of different encoding nodes, and evaluate the connectivity-power among convolutional kernels on the basis of the similarity. Then impose different level of penalty according to different connectivity-power. Meanwhile, we propose Channel Pruning base on the Dissimilarity of Angle (DACP). Firstly, we train a sparse model by GL penalty, and impose an angle dissimilarity constraint on the channels and filters of convolutional network to obtain a more sparse structure. Eventually, the effectiveness of our method is demonstrated in the section of experiment. On CIFAR-10, we reduce 66.86% FLOPs on VGG-16 with 93.31% accuracy after pruning, where FLOPs represents the number of floating-point operations per second of the model. Moreover, on ResNet-32, we reduce FLOPs by 58.46%, which makes the accuracy after pruning reach 91.76%.
Neural Network Panning: Screening the Optimal Sparse Network Before Training
Sep 27, 2022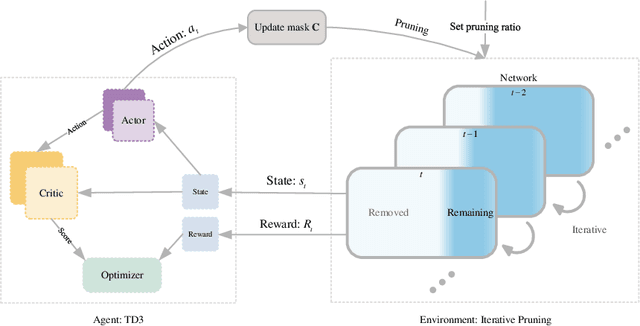

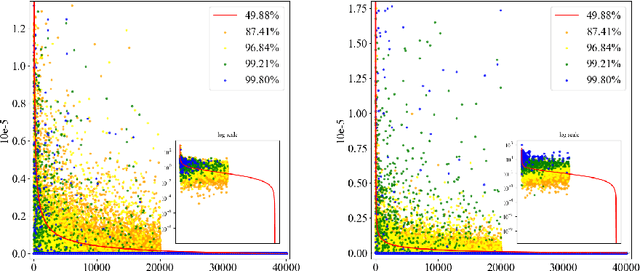

Pruning on neural networks before training not only compresses the original models, but also accelerates the network training phase, which has substantial application value. The current work focuses on fine-grained pruning, which uses metrics to calculate weight scores for weight screening, and extends from the initial single-order pruning to iterative pruning. Through these works, we argue that network pruning can be summarized as an expressive force transfer process of weights, where the reserved weights will take on the expressive force from the removed ones for the purpose of maintaining the performance of original networks. In order to achieve optimal expressive force scheduling, we propose a pruning scheme before training called Neural Network Panning which guides expressive force transfer through multi-index and multi-process steps, and designs a kind of panning agent based on reinforcement learning to automate processes. Experimental results show that Panning performs better than various available pruning before training methods.