 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservation, Not Prediction: Conversation-Level Disaggregated Scheduling for Agentic Serving
Jun 01, 2026LLM-based agents resolve a user task through many turns of dependent inference and tool calls, producing a workload whose total cost is unknown when the task arrives. Existing multi-turn systems keep the turn as the scheduling unit and decide, turn by turn, whether to disaggregate prefill from decode. That decision rests on the turn's decode length, tool behavior, and KV growth, quantities that are not observable when the scheduler must act, forcing the system to predict them. We show this dependence on prediction is imposed by the scheduling unit, not the workload. Raising the scheduling unit from the turn to the conversation converts turn-level irregularity into a stable, two-phase structure: 1) a compute-bound turn-1 prefill followed by 2) a long, memory-bound tail. Thus, with the conversation as the scheduling unit, placement reduces to reading the first-turn input length and per-decoder KV occupancy, both directly observable. We instantiate this principle in ConServe, which routes the first-turn prefill to a high-throughput prefiller, transfers the KV cache exactly once, and pins the conversation to a single decoder for its entire tail, with no learned model of decode-side cost. Against a per-turn prediction baseline, ConServe reduces p95 time-to-first-effective-token (the latency of a conversation's first user-visible output) by 51.08% and improves energy efficiency by 7.51% while preserving last-turn TBT and SLOs; mapping the two phases onto heterogeneous GPU tiers adds a further 22.75% in energy efficiency.
SurfaceXR: Fusing Smartwatch IMUs and Egocentric Hand Pose for Seamless Surface Interactions
Mar 19, 2026Mid-air gestures in Extended Reality (XR) often cause fatigue and imprecision. Surface-based interactions offer improved accuracy and comfort, but current egocentric vision methods struggle due to hand tracking challenges and unreliable surface plane estimation. We introduce SurfaceXR, a sensor fusion approach combining headset-based hand tracking with smartwatch IMU data to enable robust inputs on everyday surfaces. Our insight is that these modalities are complementary: hand tracking provides 3D positional data while IMUs capture high-frequency motion. A 21-participant study validates SurfaceXR's effectiveness for touch tracking and 8-class gesture recognition, demonstrating significant improvements over single-modality approaches.
Sketch-Augmented Features Improve Learning Long-Range Dependencies in Graph Neural Networks
Nov 05, 2025Graph Neural Networks learn on graph-structured data by iteratively aggregating local neighborhood information. While this local message passing paradigm imparts a powerful inductive bias and exploits graph sparsity, it also yields three key challenges: (i) oversquashing of long-range information, (ii) oversmoothing of node representations, and (iii) limited expressive power. In this work we inject randomized global embeddings of node features, which we term \textit{Sketched Random Features}, into standard GNNs, enabling them to efficiently capture long-range dependencies. The embeddings are unique, distance-sensitive, and topology-agnostic -- properties which we analytically and empirically show alleviate the aforementioned limitations when injected into GNNs. Experimental results on real-world graph learning tasks confirm that this strategy consistently improves performance over baseline GNNs, offering both a standalone solution and a complementary enhancement to existing techniques such as graph positional encodings. Our source code is available at \href{https://github.com/ryienh/sketched-random-features}{https://github.com/ryienh/sketched-random-features}.
WatchHAR: Real-time On-device Human Activity Recognition System for Smartwatches
Sep 05, 2025

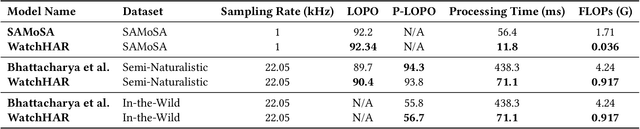

Despite advances in practical and multimodal fine-grained Human Activity Recognition (HAR), a system that runs entirely on smartwatches in unconstrained environments remains elusive. We present WatchHAR, an audio and inertial-based HAR system that operates fully on smartwatches, addressing privacy and latency issues associated with external data processing. By optimizing each component of the pipeline, WatchHAR achieves compounding performance gains. We introduce a novel architecture that unifies sensor data preprocessing and inference into an end-to-end trainable module, achieving 5x faster processing while maintaining over 90% accuracy across more than 25 activity classes. WatchHAR outperforms state-of-the-art models for event detection and activity classification while running directly on the smartwatch, achieving 9.3 ms processing time for activity event detection and 11.8 ms for multimodal activity classification. This research advances on-device activity recognition, realizing smartwatches' potential as standalone, privacy-aware, and minimally-invasive continuous activity tracking devices.
SwiftSpec: Ultra-Low Latency LLM Decoding by Scaling Asynchronous Speculative Decoding
Jun 12, 2025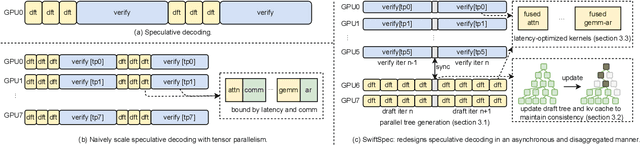


Low-latency decoding for large language models (LLMs) is crucial for applications like chatbots and code assistants, yet generating long outputs remains slow in single-query settings. Prior work on speculative decoding (which combines a small draft model with a larger target model) and tensor parallelism has each accelerated decoding. However, conventional approaches fail to apply both simultaneously due to imbalanced compute requirements (between draft and target models), KV-cache inconsistencies, and communication overheads under small-batch tensor-parallelism. This paper introduces SwiftSpec, a system that targets ultra-low latency for LLM decoding. SwiftSpec redesigns the speculative decoding pipeline in an asynchronous and disaggregated manner, so that each component can be scaled flexibly and remove draft overhead from the critical path. To realize this design, SwiftSpec proposes parallel tree generation, tree-aware KV cache management, and fused, latency-optimized kernels to overcome the challenges listed above. Across 5 model families and 6 datasets, SwiftSpec achieves an average of 1.75x speedup over state-of-the-art speculative decoding systems and, as a highlight, serves Llama3-70B at 348 tokens/s on 8 Nvidia Hopper GPUs, making it the fastest known system for low-latency LLM serving at this scale.
MobilePoser: Real-Time Full-Body Pose Estimation and 3D Human Translation from IMUs in Mobile Consumer Devices
Apr 16, 2025



There has been a continued trend towards minimizing instrumentation for full-body motion capture, going from specialized rooms and equipment, to arrays of worn sensors and recently sparse inertial pose capture methods. However, as these techniques migrate towards lower-fidelity IMUs on ubiquitous commodity devices, like phones, watches, and earbuds, challenges arise including compromised online performance, temporal consistency, and loss of global translation due to sensor noise and drift. Addressing these challenges, we introduce MobilePoser, a real-time system for full-body pose and global translation estimation using any available subset of IMUs already present in these consumer devices. MobilePoser employs a multi-stage deep neural network for kinematic pose estimation followed by a physics-based motion optimizer, achieving state-of-the-art accuracy while remaining lightweight. We conclude with a series of demonstrative applications to illustrate the unique potential of MobilePoser across a variety of fields, such as health and wellness, gaming, and indoor navigation to name a few.
Quality Measures for Dynamic Graph Generative Models
Mar 03, 2025Deep generative models have recently achieved significant success in modeling graph data, including dynamic graphs, where topology and features evolve over time. However, unlike in vision and natural language domains, evaluating generative models for dynamic graphs is challenging due to the difficulty of visualizing their output, making quantitative metrics essential. In this work, we develop a new quality metric for evaluating generative models of dynamic graphs. Current metrics for dynamic graphs typically involve discretizing the continuous-evolution of graphs into static snapshots and then applying conventional graph similarity measures. This approach has several limitations: (a) it models temporally related events as i.i.d. samples, failing to capture the non-uniform evolution of dynamic graphs; (b) it lacks a unified measure that is sensitive to both features and topology; (c) it fails to provide a scalar metric, requiring multiple metrics without clear superiority; and (d) it requires explicitly instantiating each static snapshot, leading to impractical runtime demands that hinder evaluation at scale. We propose a novel metric based on the \textit{Johnson-Lindenstrauss} lemma, applying random projections directly to dynamic graph data. This results in an expressive, scalar, and application-agnostic measure of dynamic graph similarity that overcomes the limitations of traditional methods. We also provide a comprehensive empirical evaluation of metrics for continuous-time dynamic graphs, demonstrating the effectiveness of our approach compared to existing methods. Our implementation is available at https://github.com/ryienh/jl-metric.
A Deep Probabilistic Framework for Continuous Time Dynamic Graph Generation
Dec 20, 2024



Recent advancements in graph representation learning have shifted attention towards dynamic graphs, which exhibit evolving topologies and features over time. The increased use of such graphs creates a paramount need for generative models suitable for applications such as data augmentation, obfuscation, and anomaly detection. However, there are few generative techniques that handle continuously changing temporal graph data; existing work largely relies on augmenting static graphs with additional temporal information to model dynamic interactions between nodes. In this work, we propose a fundamentally different approach: We instead directly model interactions as a joint probability of an edge forming between two nodes at a given time. This allows us to autoregressively generate new synthetic dynamic graphs in a largely assumption free, scalable, and inductive manner. We formalize this approach as DG-Gen, a generative framework for continuous time dynamic graphs, and demonstrate its effectiveness over five datasets. Our experiments demonstrate that DG-Gen not only generates higher fidelity graphs compared to traditional methods but also significantly advances link prediction tasks.
CacheGen: Fast Context Loading for Language Model Applications
Oct 11, 2023



As large language models (LLMs) take on more complex tasks, their inputs incorporate longer contexts to respond to questions that require domain knowledge or user-specific conversational histories. Yet, using long contexts poses a challenge for responsive LLM systems, as nothing can be generated until all the contexts are fetched to and processed by the LLM. Existing systems optimize only the computation delay in context processing (e.g., by caching intermediate key-value features of the text context) but often cause longer network delays in context fetching (e.g., key-value features consume orders of magnitude larger bandwidth than the text context). This paper presents CacheGen to minimize the delays in fetching and processing contexts for LLMs. CacheGen reduces the bandwidth needed for transmitting long contexts' key-value (KV) features through a novel encoder that compresses KV features into more compact bitstream representations. The encoder combines adaptive quantization with a tailored arithmetic coder, taking advantage of the KV features' distributional properties, such as locality across tokens. Furthermore, CacheGen minimizes the total delay in fetching and processing a context by using a controller that determines when to load the context as compressed KV features or raw text and picks the appropriate compression level if loaded as KV features. We test CacheGen on three models of various sizes and three datasets of different context lengths. Compared to recent methods that handle long contexts, CacheGen reduces bandwidth usage by 3.7-4.3x and the total delay in fetching and processing contexts by 2.7-3x while maintaining similar LLM performance on various tasks as loading the text contexts.
Automatic and Efficient Customization of Neural Networks for ML Applications
Oct 07, 2023



ML APIs have greatly relieved application developers of the burden to design and train their own neural network models -- classifying objects in an image can now be as simple as one line of Python code to call an API. However, these APIs offer the same pre-trained models regardless of how their output is used by different applications. This can be suboptimal as not all ML inference errors can cause application failures, and the distinction between inference errors that can or cannot cause failures varies greatly across applications. To tackle this problem, we first study 77 real-world applications, which collectively use six ML APIs from two providers, to reveal common patterns of how ML API output affects applications' decision processes. Inspired by the findings, we propose ChameleonAPI, an optimization framework for ML APIs, which takes effect without changing the application source code. ChameleonAPI provides application developers with a parser that automatically analyzes the application to produce an abstract of its decision process, which is then used to devise an application-specific loss function that only penalizes API output errors critical to the application. ChameleonAPI uses the loss function to efficiently train a neural network model customized for each application and deploys it to serve API invocations from the respective application via existing interface. Compared to a baseline that selects the best-of-all commercial ML API, we show that ChameleonAPI reduces incorrect application decisions by 43%.