 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Compile Programs to Neural Networks
Jul 21, 2024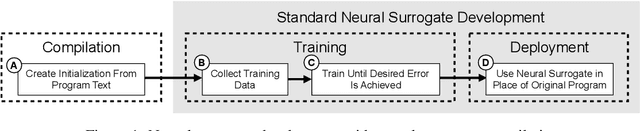

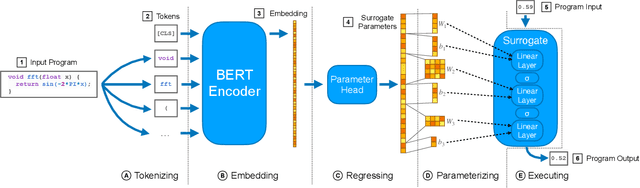
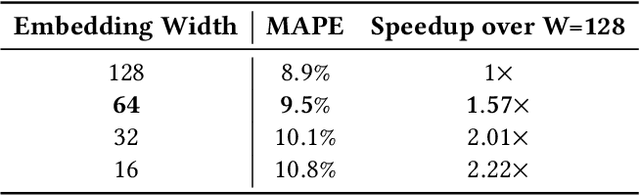
A $\textit{neural surrogate of a program}$ is a neural network that mimics the behavior of a program. Researchers have used these neural surrogates to automatically tune program inputs, adapt programs to new settings, and accelerate computations. Researchers traditionally develop neural surrogates by training on input-output examples from a single program. Alternatively, language models trained on a large dataset including many programs can consume program text, to act as a neural surrogate. Using a language model to both generate a surrogate and act as a surrogate, however, leading to a trade-off between resource consumption and accuracy. We present $\textit{neural surrogate compilation}$, a technique for producing neural surrogates directly from program text without coupling neural surrogate generation and execution. We implement neural surrogate compilers using hypernetworks trained on a dataset of C programs and find that they produce neural surrogates that are $1.9$-$9.5\times$ as data-efficient, produce visual results that are $1.0$-$1.3\times$ more similar to ground truth, and train in $4.3$-$7.3\times$ fewer epochs than neural surrogates trained from scratch.
Turaco: Complexity-Guided Data Sampling for Training Neural Surrogates of Programs
Sep 21, 2023
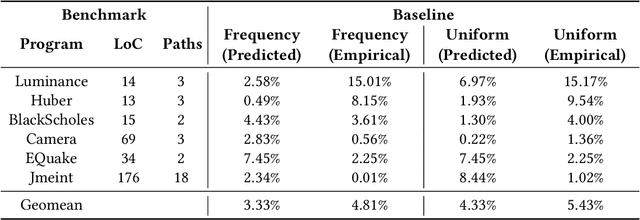
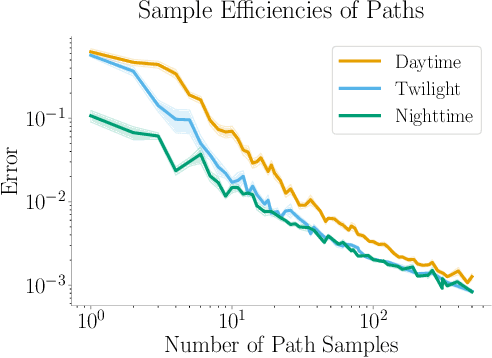
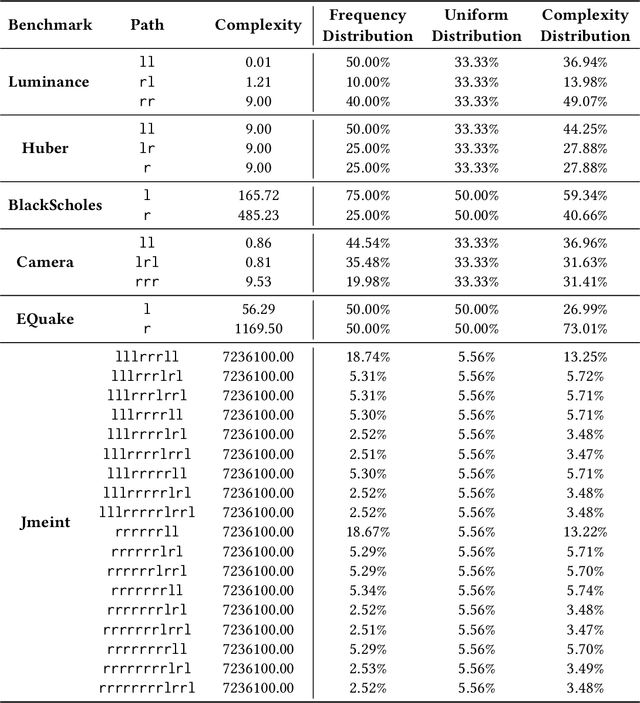
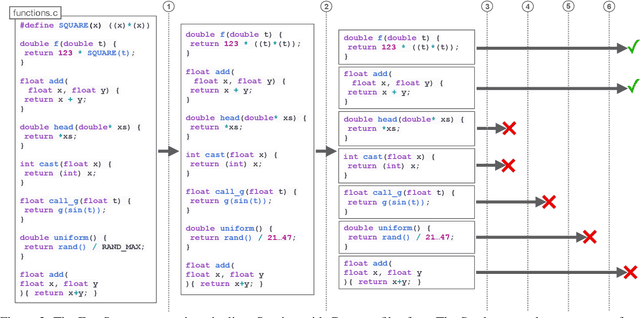
Programmers and researchers are increasingly developing surrogates of programs, models of a subset of the observable behavior of a given program, to solve a variety of software development challenges. Programmers train surrogates from measurements of the behavior of a program on a dataset of input examples. A key challenge of surrogate construction is determining what training data to use to train a surrogate of a given program. We present a methodology for sampling datasets to train neural-network-based surrogates of programs. We first characterize the proportion of data to sample from each region of a program's input space (corresponding to different execution paths of the program) based on the complexity of learning a surrogate of the corresponding execution path. We next provide a program analysis to determine the complexity of different paths in a program. We evaluate these results on a range of real-world programs, demonstrating that complexity-guided sampling results in empirical improvements in accuracy.
CoMEt: x86 Cost Model Explanation Framework
Feb 14, 2023



ML-based program cost models have been shown to yield highly accurate predictions. They have the capability to replace heavily-engineered analytical program cost models in mainstream compilers, but their black-box nature discourages their adoption. In this work, we propose the first method for obtaining faithful and intuitive explanations for the throughput predictions made by ML-based cost models. We demonstrate our explanations for the state-of-the-art ML-based cost model, Ithemal. We compare the explanations for Ithemal with the explanations for a hand-crafted, accurate analytical model, uiCA. Our empirical findings show that high similarity between explanations for Ithemal and uiCA usually corresponds to high similarity between their predictions.
The Effect of Data Dimensionality on Neural Network Prunability
Dec 01, 2022



Practitioners prune neural networks for efficiency gains and generalization improvements, but few scrutinize the factors determining the prunability of a neural network the maximum fraction of weights that pruning can remove without compromising the model's test accuracy. In this work, we study the properties of input data that may contribute to the prunability of a neural network. For high dimensional input data such as images, text, and audio, the manifold hypothesis suggests that these high dimensional inputs approximately lie on or near a significantly lower dimensional manifold. Prior work demonstrates that the underlying low dimensional structure of the input data may affect the sample efficiency of learning. In this paper, we investigate whether the low dimensional structure of the input data affects the prunability of a neural network.
Cello: Efficient Computer Systems Optimization with Predictive Early Termination and Censored Regression
Apr 11, 2022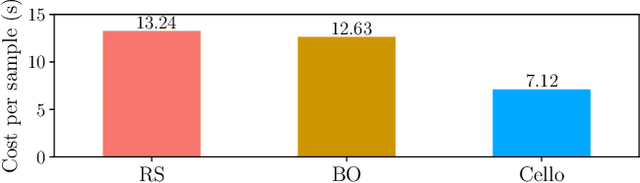
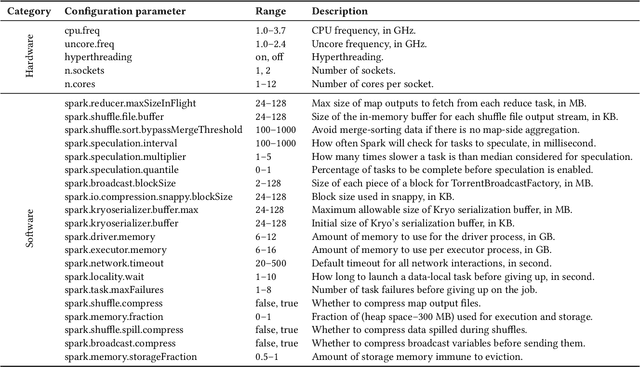
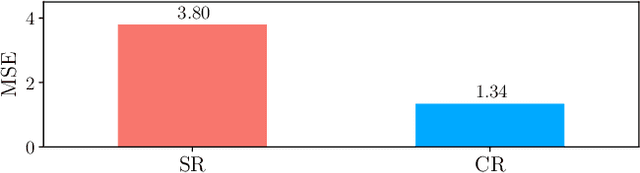
Sample-efficient machine learning (SEML) has been widely applied to find optimal latency and power tradeoffs for configurable computer systems. Instead of randomly sampling from the configuration space, SEML reduces the search cost by dramatically reducing the number of configurations that must be sampled to optimize system goals (e.g., low latency or energy). Nevertheless, SEML only reduces one component of cost -- the total number of samples collected -- but does not decrease the cost of collecting each sample. Critically, not all samples are equal; some take much longer to collect because they correspond to slow system configurations. This paper present Cello, a computer systems optimization framework that reduces sample collection costs -- especially those that come from the slowest configurations. The key insight is to predict ahead of time whether samples will have poor system behavior (e.g., long latency or high energy) and terminate these samples early before their measured system behavior surpasses the termination threshold, which we call it predictive early termination. To predict the future system behavior accurately before it manifests as high runtime or energy, Cello uses censored regression to produces accurate predictions for running samples. We evaluate Cello by optimizing latency and energy for Apache Spark workloads. We give Cello a fixed amount of time to search a combined space of hardware and software configuration parameters. Our evaluation shows that compared to the state-of-the-art SEML approach in computer systems optimization, Cello improves latency by 1.19X for minimizing latency under a power constraint, and improves energy by 1.18X for minimizing energy under a latency constraint.
Programming with Neural Surrogates of Programs
Dec 12, 2021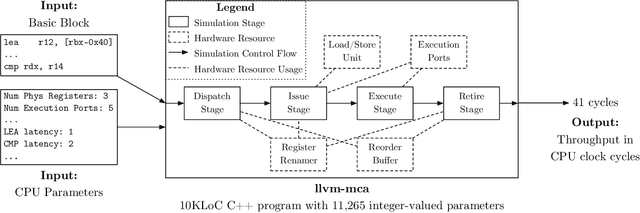
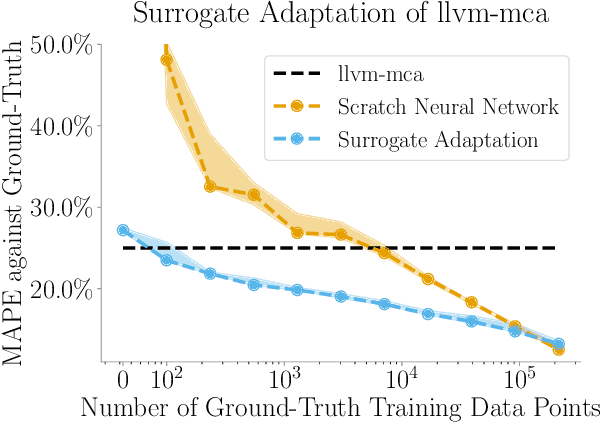

Surrogates, models that mimic the behavior of programs, form the basis of a variety of development workflows. We study three surrogate-based design patterns, evaluating each in case studies on a large-scale CPU simulator. With surrogate compilation, programmers develop a surrogate that mimics the behavior of a program to deploy to end-users in place of the original program. Surrogate compilation accelerates the CPU simulator under study by $1.6\times$. With surrogate adaptation, programmers develop a surrogate of a program then retrain that surrogate on a different task. Surrogate adaptation decreases the simulator's error by up to $50\%$. With surrogate optimization, programmers develop a surrogate of a program, optimize input parameters of the surrogate, then plug the optimized input parameters back into the original program. Surrogate optimization finds simulation parameters that decrease the simulator's error by $5\%$ compared to the error induced by expert-set parameters. In this paper we formalize this taxonomy of surrogate-based design patterns. We further describe the programming methodology common to all three design patterns. Our work builds a foundation for the emerging class of workflows based on programming with surrogates of programs.
DiffTune: Optimizing CPU Simulator Parameters with Learned Differentiable Surrogates
Oct 08, 2020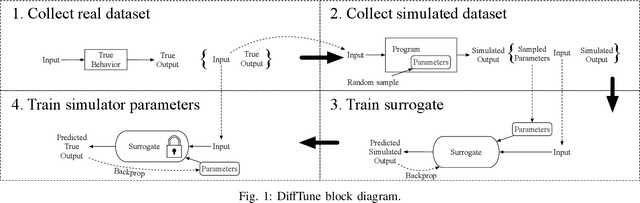
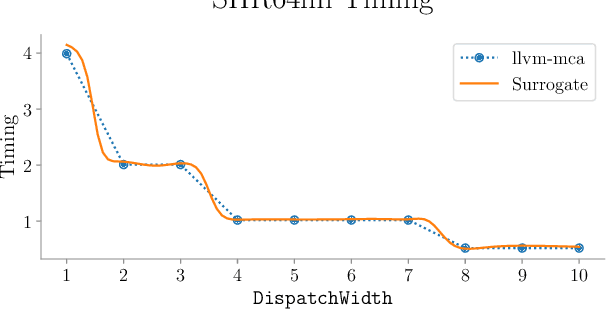
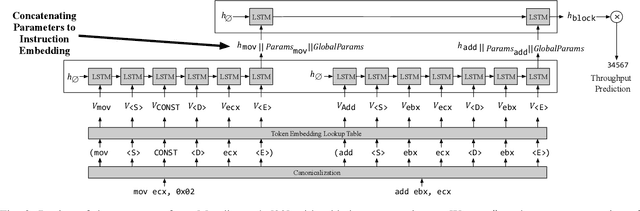
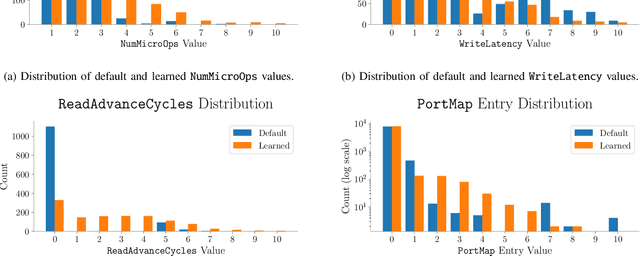
CPU simulators are useful tools for modeling CPU execution behavior. However, they suffer from inaccuracies due to the cost and complexity of setting their fine-grained parameters, such as the latencies of individual instructions. This complexity arises from the expertise required to design benchmarks and measurement frameworks that can precisely measure the values of parameters at such fine granularity. In some cases, these parameters do not necessarily have a physical realization and are therefore fundamentally approximate, or even unmeasurable. In this paper we present DiffTune, a system for learning the parameters of x86 basic block CPU simulators from coarse-grained end-to-end measurements. Given a simulator, DiffTune learns its parameters by first replacing the original simulator with a differentiable surrogate, another function that approximates the original function; by making the surrogate differentiable, DiffTune is then able to apply gradient-based optimization techniques even when the original function is non-differentiable, such as is the case with CPU simulators. With this differentiable surrogate, DiffTune then applies gradient-based optimization to produce values of the simulator's parameters that minimize the simulator's error on a dataset of ground truth end-to-end performance measurements. Finally, the learned parameters are plugged back into the original simulator. DiffTune is able to automatically learn the entire set of microarchitecture-specific parameters within the Intel x86 simulation model of llvm-mca, a basic block CPU simulator based on LLVM's instruction scheduling model. DiffTune's learned parameters lead llvm-mca to an average error that not only matches but lowers that of its original, expert-provided parameter values.
TIRAMISU: A Polyhedral Compiler for Dense and Sparse Deep Learning
May 07, 2020
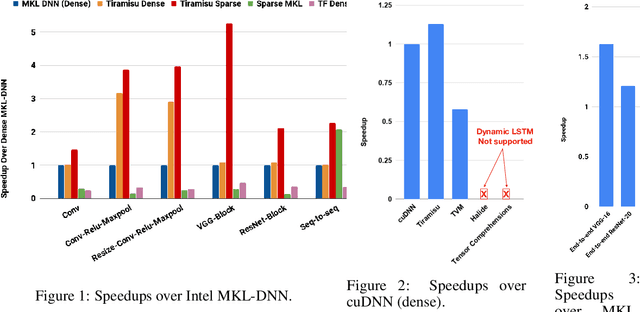
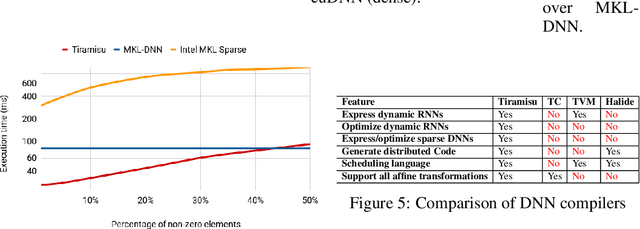
In this paper, we demonstrate a compiler that can optimize sparse and recurrent neural networks, both of which are currently outside of the scope of existing neural network compilers (sparse neural networks here stand for networks that can be accelerated with sparse tensor algebra techniques). Our demonstration includes a mapping of sparse and recurrent neural networks to the polyhedral model along with an implementation of our approach in TIRAMISU, our state-of-the-art polyhedral compiler. We evaluate our approach on a set of deep learning benchmarks and compare our results with hand-optimized industrial libraries. Our results show that our approach at least matches Intel MKL-DNN and in some cases outperforms it by 5x (on multicore-CPUs).
Comparing Rewinding and Fine-tuning in Neural Network Pruning
Mar 05, 2020
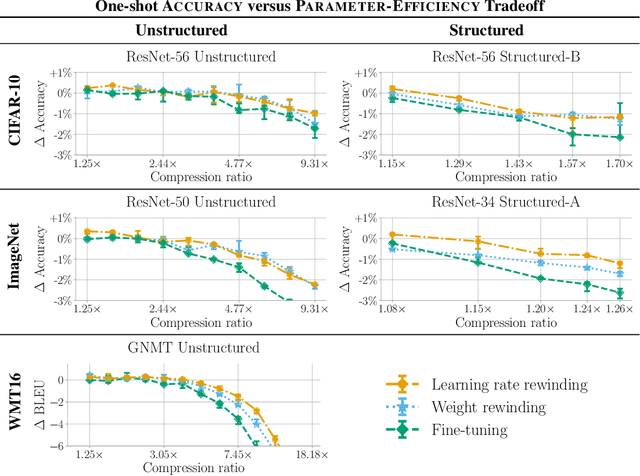
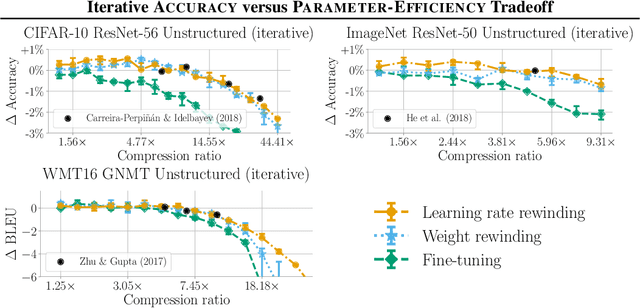

Many neural network pruning algorithms proceed in three steps: train the network to completion, remove unwanted structure to compress the network, and retrain the remaining structure to recover lost accuracy. The standard retraining technique, fine-tuning, trains the unpruned weights from their final trained values using a small fixed learning rate. In this paper, we compare fine-tuning to alternative retraining techniques. Weight rewinding (as proposed by Frankle et al., (2019)), rewinds unpruned weights to their values from earlier in training and retrains them from there using the original training schedule. Learning rate rewinding (which we propose) trains the unpruned weights from their final values using the same learning rate schedule as weight rewinding. Both rewinding techniques outperform fine-tuning, forming the basis of a network-agnostic pruning algorithm that matches the accuracy and compression ratios of several more network-specific state-of-the-art techniques.
Abstractions for AI-Based User Interfaces and Systems
Sep 14, 2017Novel user interfaces based on artificial intelligence, such as natural-language agents, present new categories of engineering challenges. These systems need to cope with uncertainty and ambiguity, interface with machine learning algorithms, and compose information from multiple users to make decisions. We propose to treat these challenges as language-design problems. We describe three programming language abstractions for three core problems in intelligent system design. First, hypothetical worlds support nondeterministic search over spaces of alternative actions. Second, a feature type system abstracts the interaction between applications and learning algorithms. Finally, constructs for collaborative execution extend hypothetical worlds across multiple machines while controlling access to private data. We envision these features as first steps toward a complete language for implementing AI-based interfaces and applications.