 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing State Between Prompts and Programs
Dec 16, 2025The rise of large language models (LLMs) has introduced a new type of programming: natural language programming. By writing prompts that direct LLMs to perform natural language processing, code generation, reasoning, etc., users are writing code in natural language -- natural language code -- for the LLM to execute. An emerging area of research enables interoperability between natural language code and formal languages such as Python. We present a novel programming abstraction, shared program state, that removes the manual work required to enable interoperability between natural language code and program state. With shared program state, programmers can write natural code that directly writes program variables, computes with program objects, and implements control flow in the program. We present a schema for specifying natural function interfaces that extend programming systems to support natural code and leverage this schema to specify shared program state as a natural function interface. We implement shared program state in the Nightjar programming system. Nightjar enables programmers to write Python programs that contain natural code that shares the Python program state. We show that Nightjar programs achieve comparable or higher task accuracy than manually written implementations (+4-19%), while decreasing the lines of code by 39.6% on average. The tradeoff to using Nightjar is that it may incur runtime overhead (0.4-4.3x runtime of manual implementations).
Learning to Compile Programs to Neural Networks
Jul 21, 2024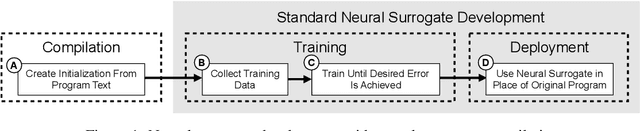

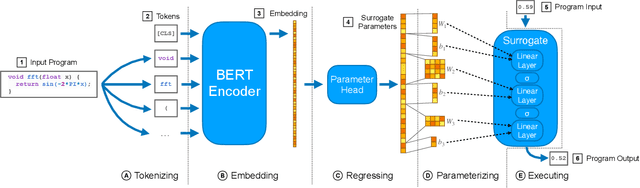
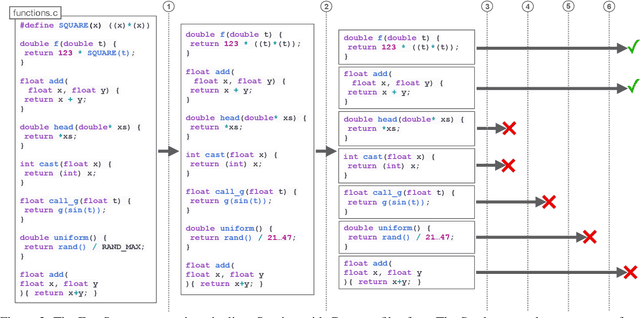
A $\textit{neural surrogate of a program}$ is a neural network that mimics the behavior of a program. Researchers have used these neural surrogates to automatically tune program inputs, adapt programs to new settings, and accelerate computations. Researchers traditionally develop neural surrogates by training on input-output examples from a single program. Alternatively, language models trained on a large dataset including many programs can consume program text, to act as a neural surrogate. Using a language model to both generate a surrogate and act as a surrogate, however, leading to a trade-off between resource consumption and accuracy. We present $\textit{neural surrogate compilation}$, a technique for producing neural surrogates directly from program text without coupling neural surrogate generation and execution. We implement neural surrogate compilers using hypernetworks trained on a dataset of C programs and find that they produce neural surrogates that are $1.9$-$9.5\times$ as data-efficient, produce visual results that are $1.0$-$1.3\times$ more similar to ground truth, and train in $4.3$-$7.3\times$ fewer epochs than neural surrogates trained from scratch.
Relay: A High-Level IR for Deep Learning
Apr 17, 2019

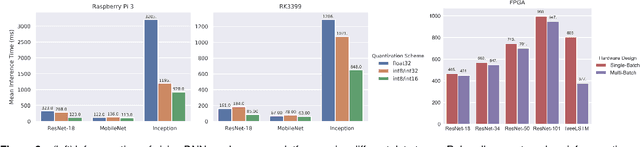
Frameworks for writing, compiling, and optimizing deep learning (DL) models have recently enabled progress in areas like computer vision and natural language processing. Extending these frameworks to accommodate the rapidly diversifying landscape of DL models and hardware platforms presents challenging tradeoffs between expressiveness, composability, and portability. We present Relay, a new intermediate representation (IR) and compiler framework for DL models. The functional, statically-typed Relay IR unifies and generalizes existing DL IRs and can express state-of-the-art models. Relay's expressive IR required careful design of the type system, automatic differentiation, and optimizations. Relay's extensible compiler can eliminate abstraction overhead and target new hardware platforms. The design insights from Relay can be applied to existing frameworks to develop IRs that support extension without compromising on expressivity, composibility, and portability. Our evaluation demonstrates that the Relay prototype can already provide competitive performance for a broad class of models running on CPUs, GPUs, and FPGAs.
Relay: A New IR for Machine Learning Frameworks
Sep 26, 2018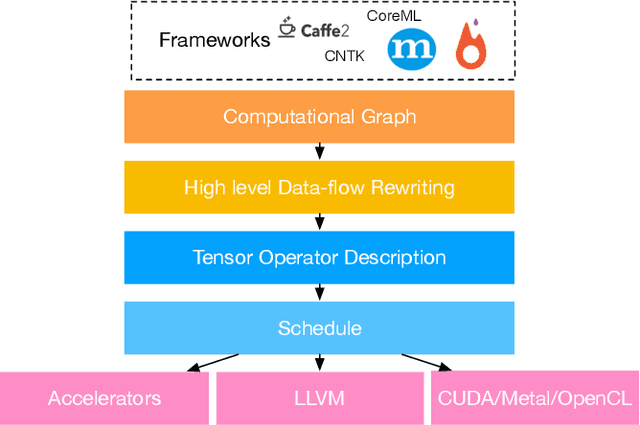
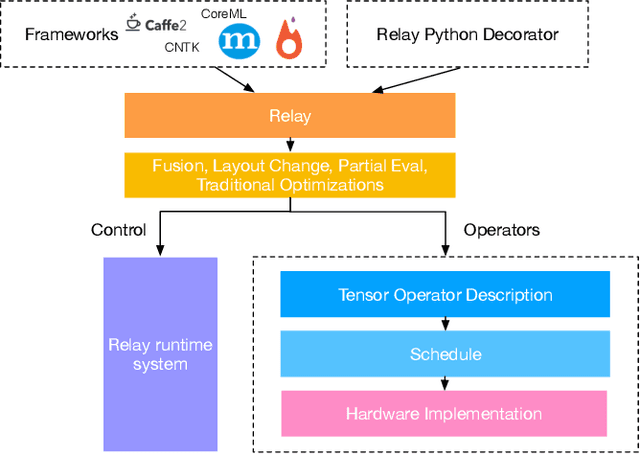


Machine learning powers diverse services in industry including search, translation, recommendation systems, and security. The scale and importance of these models require that they be efficient, expressive, and portable across an array of heterogeneous hardware devices. These constraints are often at odds; in order to better accommodate them we propose a new high-level intermediate representation (IR) called Relay. Relay is being designed as a purely-functional, statically-typed language with the goal of balancing efficient compilation, expressiveness, and portability. We discuss the goals of Relay and highlight its important design constraints. Our prototype is part of the open source NNVM compiler framework, which powers Amazon's deep learning framework MxNet.