 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Tensor Rematerialization
Jun 18, 2020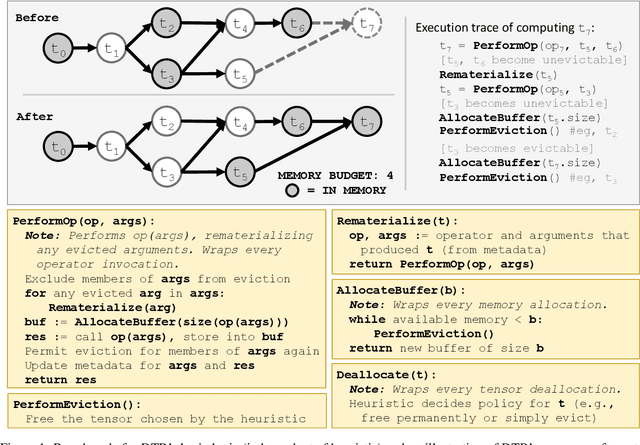

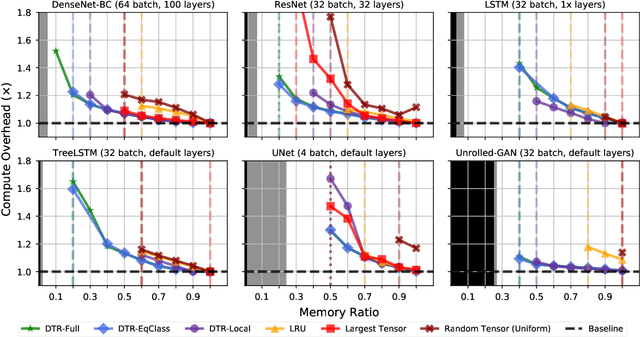
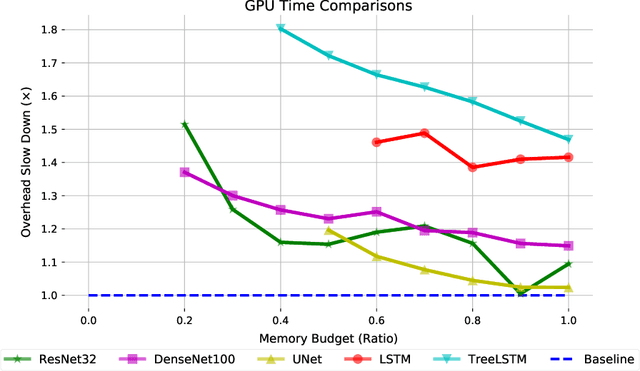
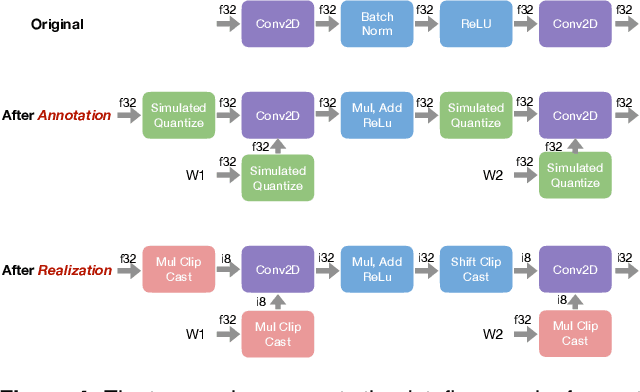
Checkpointing enables training larger models by freeing intermediate activations and recomputing them on demand. Previous checkpointing techniques are difficult to generalize to dynamic models because they statically plan recomputations offline. We present Dynamic Tensor Rematerialization (DTR), a greedy online algorithm for heuristically checkpointing arbitrary models. DTR is extensible and general: it is parameterized by an eviction policy and only collects lightweight metadata on tensors and operators. Though DTR has no advance knowledge of the model or training task, we prove it can train an $N$-layer feedforward network on an $\Omega(\sqrt{N})$ memory budget with only $\mathcal{O}(N)$ tensor operations. Moreover, we identify a general eviction heuristic and show how it allows DTR to automatically provide favorable checkpointing performance across a variety of models and memory budgets.
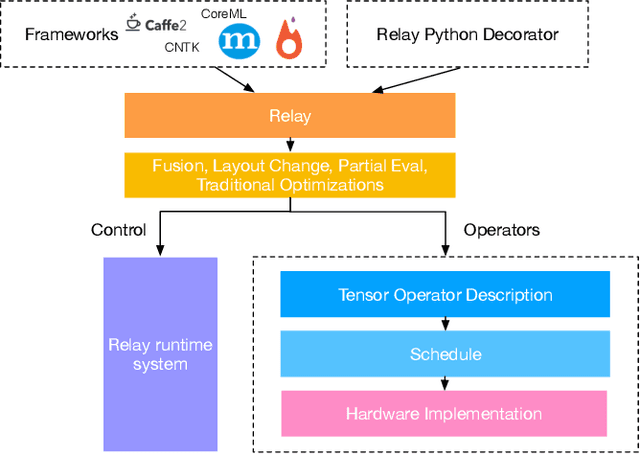
Relay: A High-Level IR for Deep Learning
Apr 17, 2019

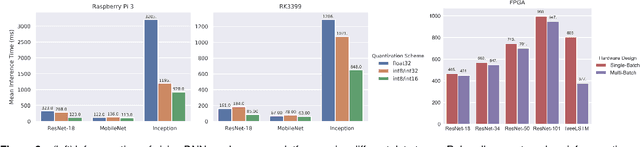
Frameworks for writing, compiling, and optimizing deep learning (DL) models have recently enabled progress in areas like computer vision and natural language processing. Extending these frameworks to accommodate the rapidly diversifying landscape of DL models and hardware platforms presents challenging tradeoffs between expressiveness, composability, and portability. We present Relay, a new intermediate representation (IR) and compiler framework for DL models. The functional, statically-typed Relay IR unifies and generalizes existing DL IRs and can express state-of-the-art models. Relay's expressive IR required careful design of the type system, automatic differentiation, and optimizations. Relay's extensible compiler can eliminate abstraction overhead and target new hardware platforms. The design insights from Relay can be applied to existing frameworks to develop IRs that support extension without compromising on expressivity, composibility, and portability. Our evaluation demonstrates that the Relay prototype can already provide competitive performance for a broad class of models running on CPUs, GPUs, and FPGAs.
Relay: A New IR for Machine Learning Frameworks
Sep 26, 2018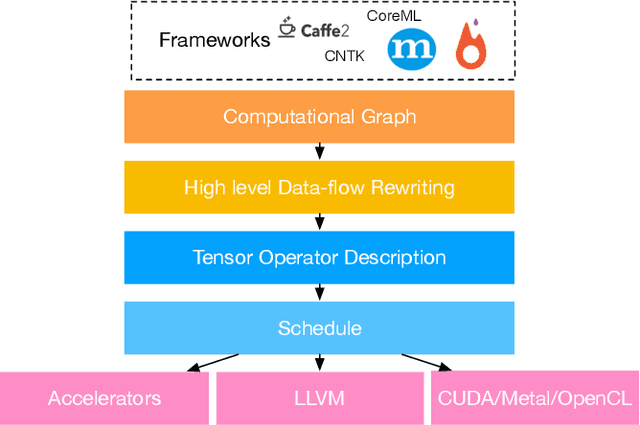


Machine learning powers diverse services in industry including search, translation, recommendation systems, and security. The scale and importance of these models require that they be efficient, expressive, and portable across an array of heterogeneous hardware devices. These constraints are often at odds; in order to better accommodate them we propose a new high-level intermediate representation (IR) called Relay. Relay is being designed as a purely-functional, statically-typed language with the goal of balancing efficient compilation, expressiveness, and portability. We discuss the goals of Relay and highlight its important design constraints. Our prototype is part of the open source NNVM compiler framework, which powers Amazon's deep learning framework MxNet.