 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelay: A High-Level IR for Deep Learning
Apr 17, 2019

Frameworks for writing, compiling, and optimizing deep learning (DL) models have recently enabled progress in areas like computer vision and natural language processing. Extending these frameworks to accommodate the rapidly diversifying landscape of DL models and hardware platforms presents challenging tradeoffs between expressiveness, composability, and portability. We present Relay, a new intermediate representation (IR) and compiler framework for DL models. The functional, statically-typed Relay IR unifies and generalizes existing DL IRs and can express state-of-the-art models. Relay's expressive IR required careful design of the type system, automatic differentiation, and optimizations. Relay's extensible compiler can eliminate abstraction overhead and target new hardware platforms. The design insights from Relay can be applied to existing frameworks to develop IRs that support extension without compromising on expressivity, composibility, and portability. Our evaluation demonstrates that the Relay prototype can already provide competitive performance for a broad class of models running on CPUs, GPUs, and FPGAs.
Learning to Optimize Tensor Programs
Oct 27, 2018

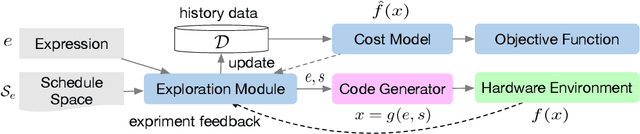

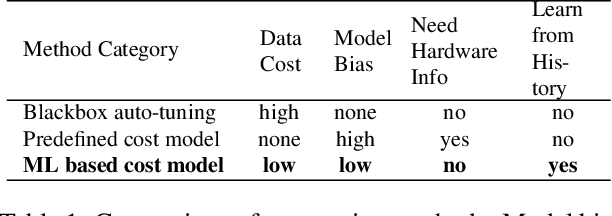
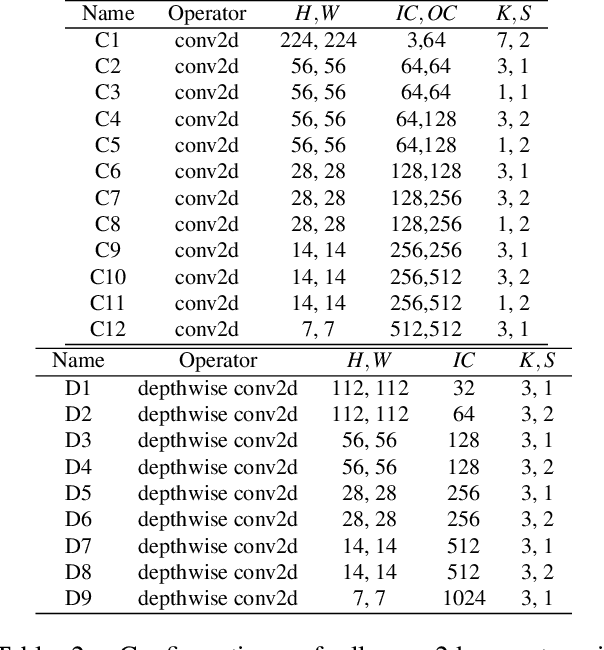
We introduce a learning-based framework to optimize tensor programs for deep learning workloads. Efficient implementations of tensor operators, such as matrix multiplication and high dimensional convolution, are key enablers of effective deep learning systems. However, existing systems rely on manually optimized libraries such as cuDNN where only a narrow range of server class GPUs are well-supported. The reliance on hardware-specific operator libraries limits the applicability of high-level graph optimizations and incurs significant engineering costs when deploying to new hardware targets. We use learning to remove this engineering burden. We learn domain-specific statistical cost models to guide the search of tensor operator implementations over billions of possible program variants. We further accelerate the search by effective model transfer across workloads. Experimental results show that our framework delivers performance competitive with state-of-the-art hand-tuned libraries for low-power CPU, mobile GPU, and server-class GPU.
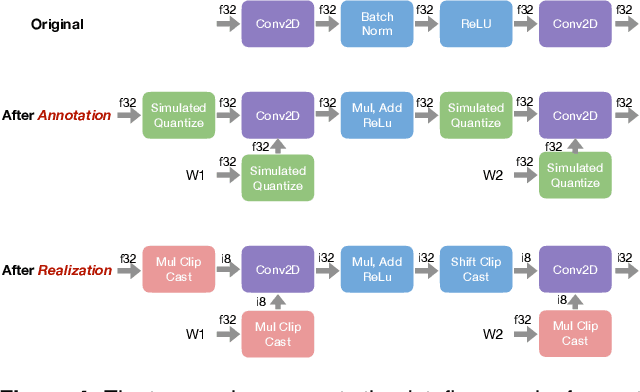
Automating Generation of Low Precision Deep Learning Operators
Oct 25, 2018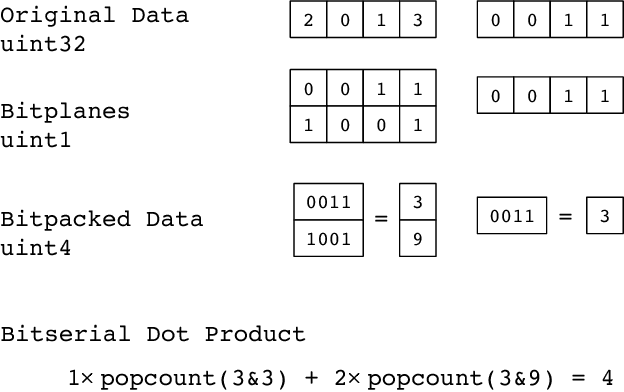
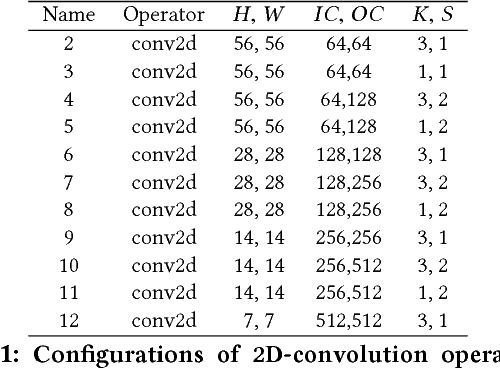
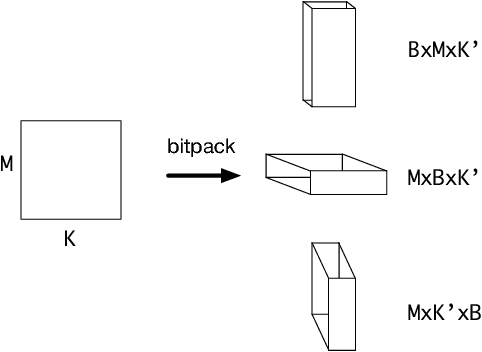
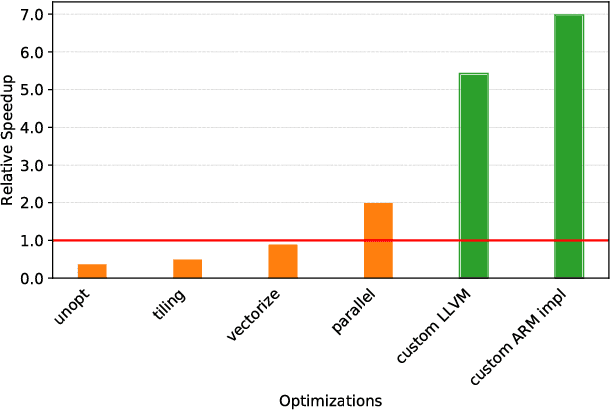
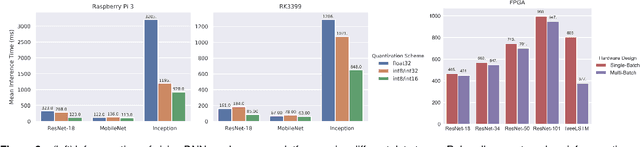
State of the art deep learning models have made steady progress in the fields of computer vision and natural language processing, at the expense of growing model sizes and computational complexity. Deploying these models on low power and mobile devices poses a challenge due to their limited compute capabilities and strict energy budgets. One solution that has generated significant research interest is deploying highly quantized models that operate on low precision inputs and weights less than eight bits, trading off accuracy for performance. These models have a significantly reduced memory footprint (up to 32x reduction) and can replace multiply-accumulates with bitwise operations during compute intensive convolution and fully connected layers. Most deep learning frameworks rely on highly engineered linear algebra libraries such as ATLAS or Intel's MKL to implement efficient deep learning operators. To date, none of the popular deep learning directly support low precision operators, partly due to a lack of optimized low precision libraries. In this paper we introduce a work flow to quickly generate high performance low precision deep learning operators for arbitrary precision that target multiple CPU architectures and include optimizations such as memory tiling and vectorization. We present an extensive case study on low power ARM Cortex-A53 CPU, and show how we can generate 1-bit, 2-bit convolutions with speedups up to 16x over an optimized 16-bit integer baseline and 2.3x better than handwritten implementations.
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
Oct 05, 2018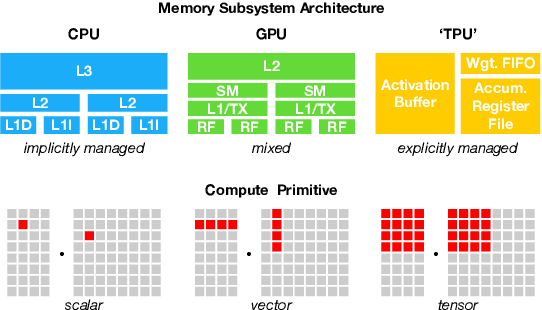
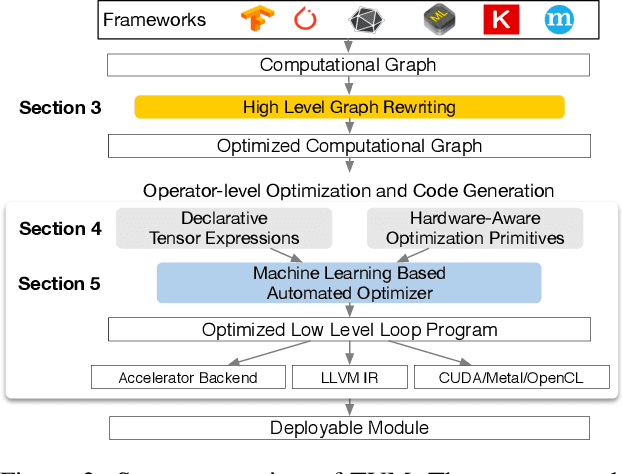
There is an increasing need to bring machine learning to a wide diversity of hardware devices. Current frameworks rely on vendor-specific operator libraries and optimize for a narrow range of server-class GPUs. Deploying workloads to new platforms -- such as mobile phones, embedded devices, and accelerators (e.g., FPGAs, ASICs) -- requires significant manual effort. We propose TVM, a compiler that exposes graph-level and operator-level optimizations to provide performance portability to deep learning workloads across diverse hardware back-ends. TVM solves optimization challenges specific to deep learning, such as high-level operator fusion, mapping to arbitrary hardware primitives, and memory latency hiding. It also automates optimization of low-level programs to hardware characteristics by employing a novel, learning-based cost modeling method for rapid exploration of code optimizations. Experimental results show that TVM delivers performance across hardware back-ends that are competitive with state-of-the-art, hand-tuned libraries for low-power CPU, mobile GPU, and server-class GPUs. We also demonstrate TVM's ability to target new accelerator back-ends, such as the FPGA-based generic deep learning accelerator. The system is open sourced and in production use inside several major companies.
VTA: An Open Hardware-Software Stack for Deep Learning
Jul 11, 2018
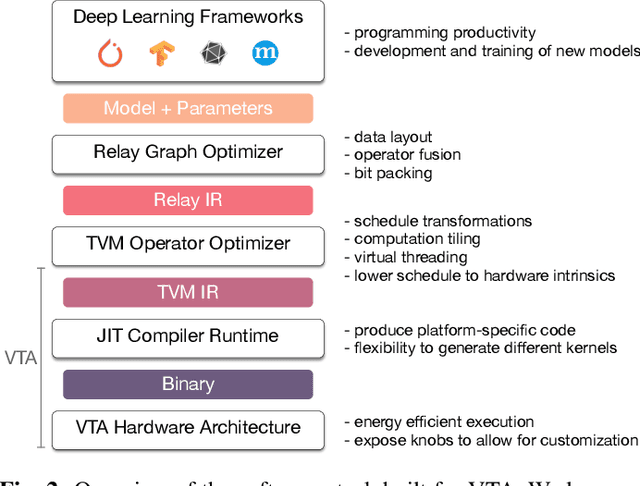

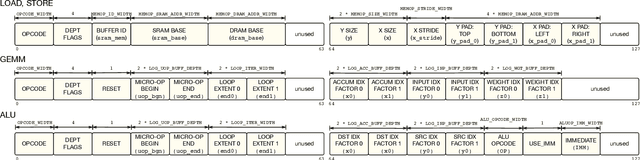
Hardware acceleration is an enabler for ubiquitous and efficient deep learning. With hardware accelerators being introduced in datacenter and edge devices, it is time to acknowledge that hardware specialization is central to the deep learning system stack. This technical report presents the Versatile Tensor Accelerator (VTA), an open, generic, and customizable deep learning accelerator design. VTA is a programmable accelerator that exposes a RISC-like programming abstraction to describe operations at the tensor level. We designed VTA to expose the most salient and common characteristics of mainstream deep learning accelerators, such as tensor operations, DMA load/stores, and explicit compute/memory arbitration. VTA is more than a standalone accelerator design: it's an end-to-end solution that includes drivers, a JIT runtime, and an optimizing compiler stack based on TVM. The current release of VTA includes a behavioral hardware simulator, as well as the infrastructure to deploy VTA on low-cost FPGA development boards for fast prototyping. By extending the TVM stack with a customizable, and open source deep learning hardware accelerator design, we are exposing a transparent end-to-end deep learning stack from the high-level deep learning framework, down to the actual hardware design and implementation. This forms a truly end-to-end, from software-to-hardware open source stack for deep learning systems.
MATIC: Learning Around Errors for Efficient Low-Voltage Neural Network Accelerators
Mar 23, 2018
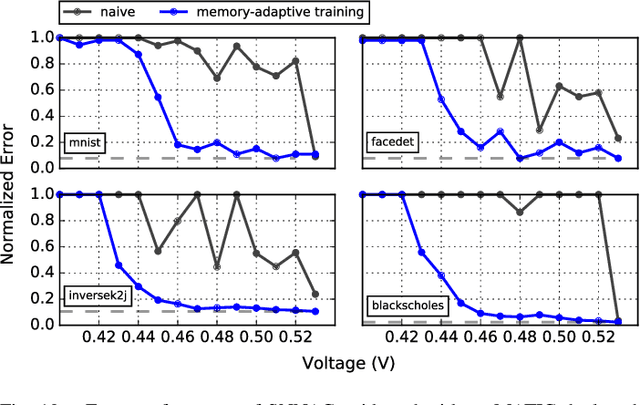
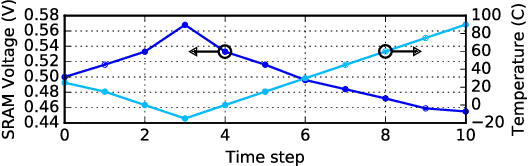
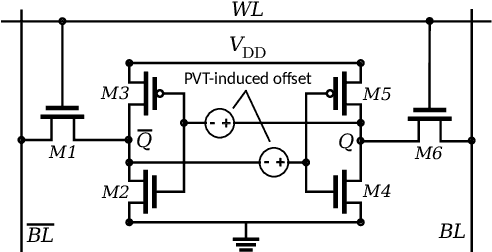
As a result of the increasing demand for deep neural network (DNN)-based services, efforts to develop dedicated hardware accelerators for DNNs are growing rapidly. However,while accelerators with high performance and efficiency on convolutional deep neural networks (Conv-DNNs) have been developed, less progress has been made with regards to fully-connected DNNs (FC-DNNs). In this paper, we propose MATIC (Memory Adaptive Training with In-situ Canaries), a methodology that enables aggressive voltage scaling of accelerator weight memories to improve the energy-efficiency of DNN accelerators. To enable accurate operation with voltage overscaling, MATIC combines the characteristics of destructive SRAM reads with the error resilience of neural networks in a memory-adaptive training process. Furthermore, PVT-related voltage margins are eliminated using bit-cells from synaptic weights as in-situ canaries to track runtime environmental variation. Demonstrated on a low-power DNN accelerator that we fabricate in 65 nm CMOS, MATIC enables up to 60-80 mV of voltage overscaling (3.3x total energy reduction versus the nominal voltage), or 18.6x application error reduction.
Introducing ReQuEST: an Open Platform for Reproducible and Quality-Efficient Systems-ML Tournaments
Jan 19, 2018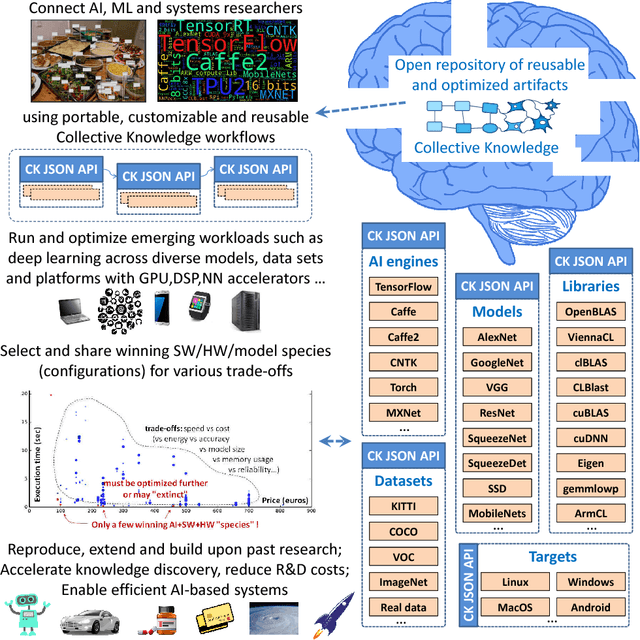
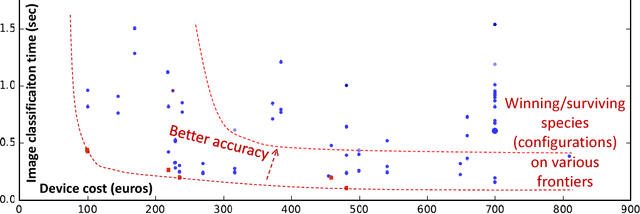
Co-designing efficient machine learning based systems across the whole hardware/software stack to trade off speed, accuracy, energy and costs is becoming extremely complex and time consuming. Researchers often struggle to evaluate and compare different published works across rapidly evolving software frameworks, heterogeneous hardware platforms, compilers, libraries, algorithms, data sets, models, and environments. We present our community effort to develop an open co-design tournament platform with an online public scoreboard. It will gradually incorporate best research practices while providing a common way for multidisciplinary researchers to optimize and compare the quality vs. efficiency Pareto optimality of various workloads on diverse and complete hardware/software systems. We want to leverage the open-source Collective Knowledge framework and the ACM artifact evaluation methodology to validate and share the complete machine learning system implementations in a standardized, portable, and reproducible fashion. We plan to hold regular multi-objective optimization and co-design tournaments for emerging workloads such as deep learning, starting with ASPLOS'18 (ACM conference on Architectural Support for Programming Languages and Operating Systems - the premier forum for multidisciplinary systems research spanning computer architecture and hardware, programming languages and compilers, operating systems and networking) to build a public repository of the most efficient machine learning algorithms and systems which can be easily customized, reused and built upon.