 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAF: Holistic Compilation for Deep Learning Model Training
Mar 08, 2023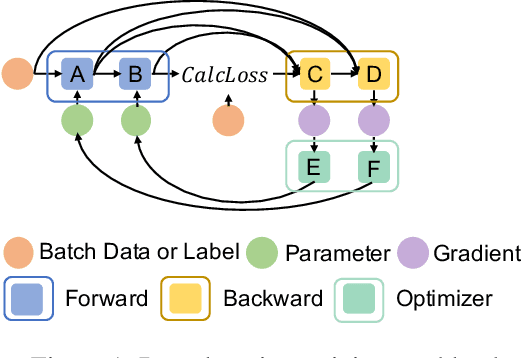
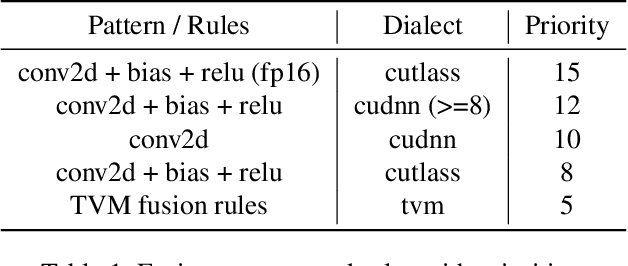

As deep learning is pervasive in modern applications, many deep learning frameworks are presented for deep learning practitioners to develop and train DNN models rapidly. Meanwhile, as training large deep learning models becomes a trend in recent years, the training throughput and memory footprint are getting crucial. Accordingly, optimizing training workloads with compiler optimizations is inevitable and getting more and more attentions. However, existing deep learning compilers (DLCs) mainly target inference and do not incorporate holistic optimizations, such as automatic differentiation and automatic mixed precision, in training workloads. In this paper, we present RAF, a deep learning compiler for training. Unlike existing DLCs, RAF accepts a forward model and in-house generates a training graph. Accordingly, RAF is able to systematically consolidate graph optimizations for performance, memory and distributed training. In addition, to catch up to the state-of-the-art performance with hand-crafted kernel libraries as well as tensor compilers, RAF proposes an operator dialect mechanism to seamlessly integrate all possible kernel implementations. We demonstrate that by in-house training graph generation and operator dialect mechanism, we are able to perform holistic optimizations and achieve either better training throughput or larger batch size against PyTorch (eager and torchscript mode), XLA, and DeepSpeed for popular transformer models on GPUs.
Nimble: Efficiently Compiling Dynamic Neural Networks for Model Inference
Jun 04, 2020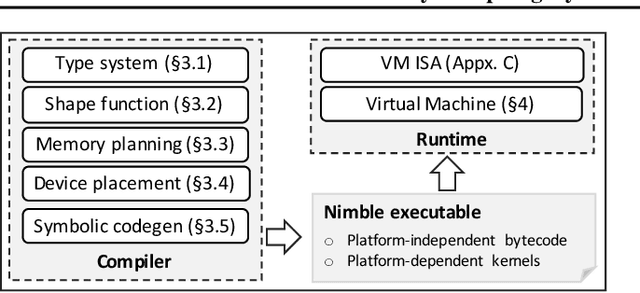
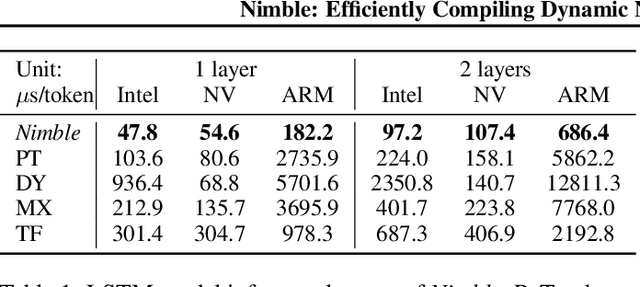
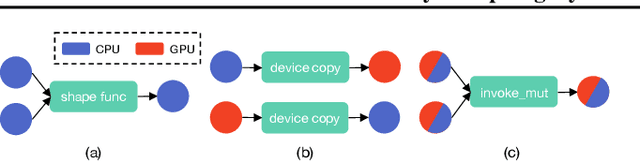

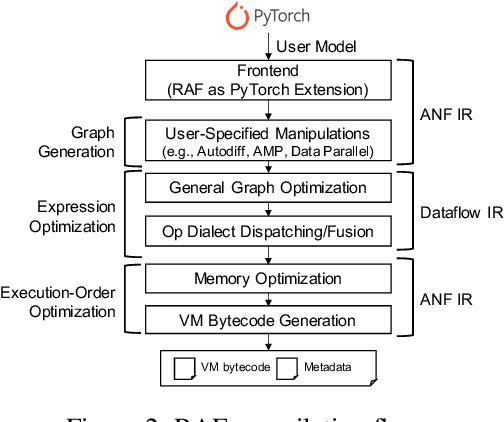
Modern deep neural networks increasingly make use of features such as dynamic control flow, data structures and dynamic tensor shapes. Existing deep learning systems focus on optimizing and executing static neural networks which assume a pre-determined model architecture and input data shapes--assumptions which are violated by dynamic neural networks. Therefore, executing dynamic models with deep learning systems is currently both inflexible and sub-optimal, if not impossible. Optimizing dynamic neural networks is more challenging than static neural networks; optimizations must consider all possible execution paths and tensor shapes. This paper proposes Nimble, a high-performance and flexible system to optimize, compile, and execute dynamic neural networks on multiple platforms. Nimble handles model dynamism by introducing a dynamic type system, a set of dynamism-oriented optimizations, and a light-weight virtual machine runtime. Our evaluation demonstrates that Nimble outperforms state-of-the-art deep learning frameworks and runtime systems for dynamic neural networks by up to 20x on hardware platforms including Intel CPUs, ARM CPUs, and Nvidia GPUs.
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
Oct 05, 2018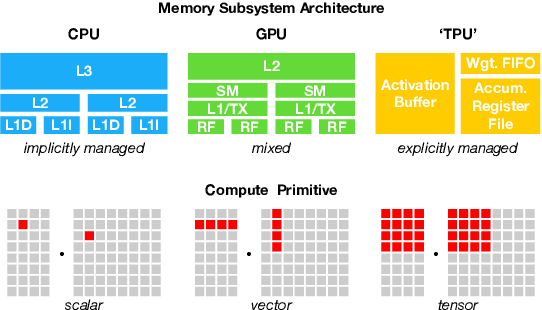
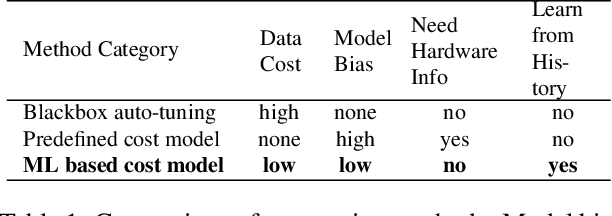
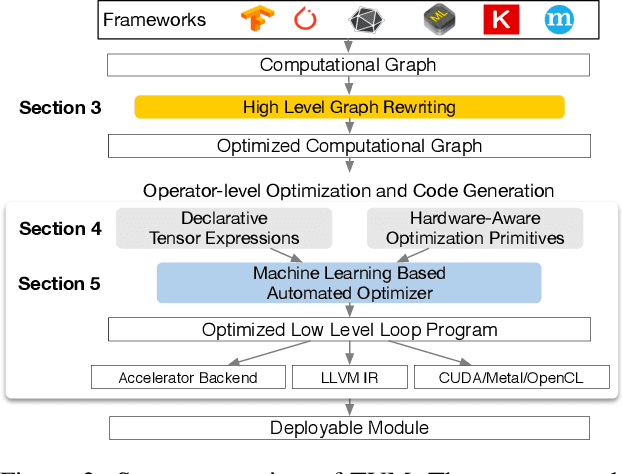
There is an increasing need to bring machine learning to a wide diversity of hardware devices. Current frameworks rely on vendor-specific operator libraries and optimize for a narrow range of server-class GPUs. Deploying workloads to new platforms -- such as mobile phones, embedded devices, and accelerators (e.g., FPGAs, ASICs) -- requires significant manual effort. We propose TVM, a compiler that exposes graph-level and operator-level optimizations to provide performance portability to deep learning workloads across diverse hardware back-ends. TVM solves optimization challenges specific to deep learning, such as high-level operator fusion, mapping to arbitrary hardware primitives, and memory latency hiding. It also automates optimization of low-level programs to hardware characteristics by employing a novel, learning-based cost modeling method for rapid exploration of code optimizations. Experimental results show that TVM delivers performance across hardware back-ends that are competitive with state-of-the-art, hand-tuned libraries for low-power CPU, mobile GPU, and server-class GPUs. We also demonstrate TVM's ability to target new accelerator back-ends, such as the FPGA-based generic deep learning accelerator. The system is open sourced and in production use inside several major companies.
Fast Video Classification via Adaptive Cascading of Deep Models
Jul 02, 2017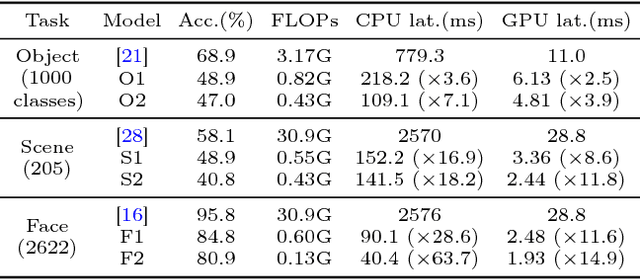

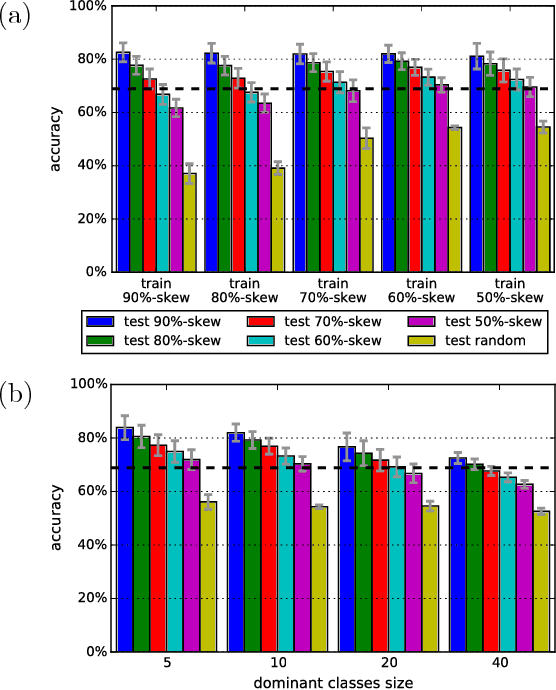
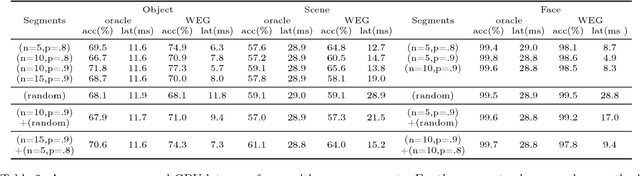
Recent advances have enabled "oracle" classifiers that can classify across many classes and input distributions with high accuracy without retraining. However, these classifiers are relatively heavyweight, so that applying them to classify video is costly. We show that day-to-day video exhibits highly skewed class distributions over the short term, and that these distributions can be classified by much simpler models. We formulate the problem of detecting the short-term skews online and exploiting models based on it as a new sequential decision making problem dubbed the Online Bandit Problem, and present a new algorithm to solve it. When applied to recognizing faces in TV shows and movies, we realize end-to-end classification speedups of 2.4-7.8x/2.6-11.2x (on GPU/CPU) relative to a state-of-the-art convolutional neural network, at competitive accuracy.
Visualizing NLP annotations for Crowdsourcing
Aug 25, 2015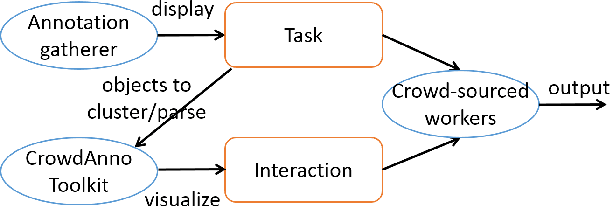



Visualizing NLP annotation is useful for the collection of training data for the statistical NLP approaches. Existing toolkits either provide limited visual aid, or introduce comprehensive operators to realize sophisticated linguistic rules. Workers must be well trained to use them. Their audience thus can hardly be scaled to large amounts of non-expert crowdsourced workers. In this paper, we present CROWDANNO, a visualization toolkit to allow crowd-sourced workers to annotate two general categories of NLP problems: clustering and parsing. Workers can finish the tasks with simplified operators in an interactive interface, and fix errors conveniently. User studies show our toolkit is very friendly to NLP non-experts, and allow them to produce high quality labels for several sophisticated problems. We release our source code and toolkit to spur future research.