 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing and Taming Resolution in Convolutional Neural Networks
Oct 28, 2021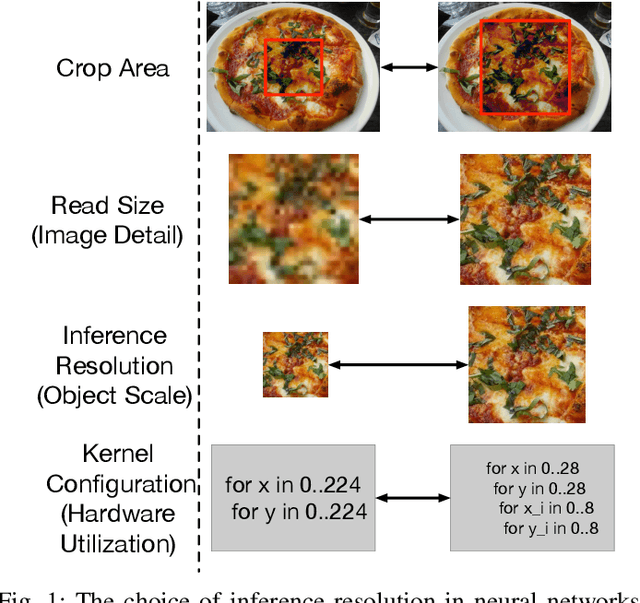

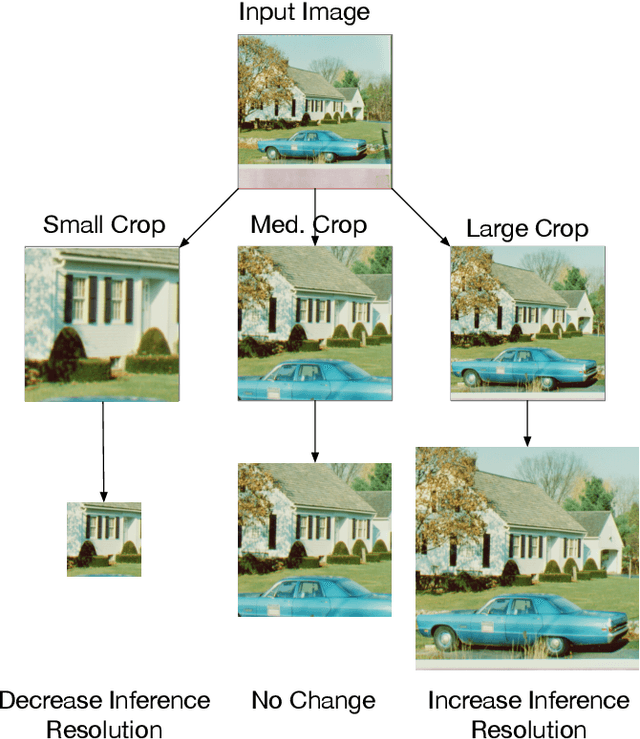
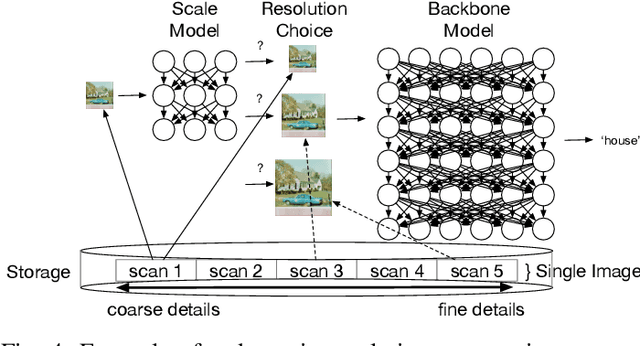
Image resolution has a significant effect on the accuracy and computational, storage, and bandwidth costs of computer vision model inference. These costs are exacerbated when scaling out models to large inference serving systems and make image resolution an attractive target for optimization. However, the choice of resolution inherently introduces additional tightly coupled choices, such as image crop size, image detail, and compute kernel implementation that impact computational, storage, and bandwidth costs. Further complicating this setting, the optimal choices from the perspective of these metrics are highly dependent on the dataset and problem scenario. We characterize this tradeoff space, quantitatively studying the accuracy and efficiency tradeoff via systematic and automated tuning of image resolution, image quality and convolutional neural network operators. With the insights from this study, we propose a dynamic resolution mechanism that removes the need to statically choose a resolution ahead of time.
Do CNNs Encode Data Augmentations?
Feb 29, 2020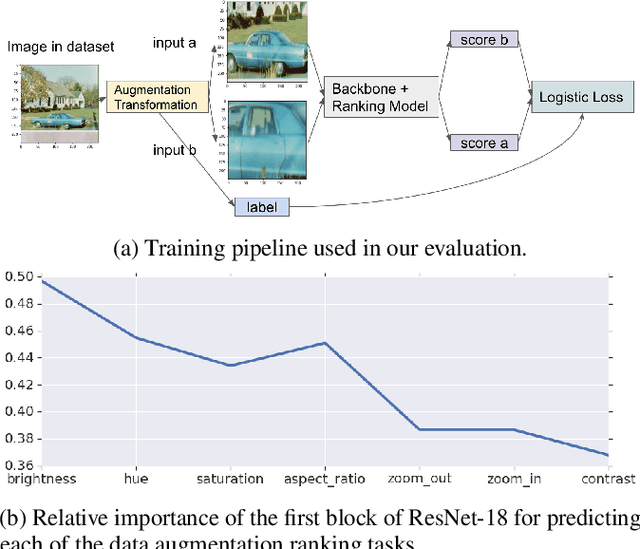
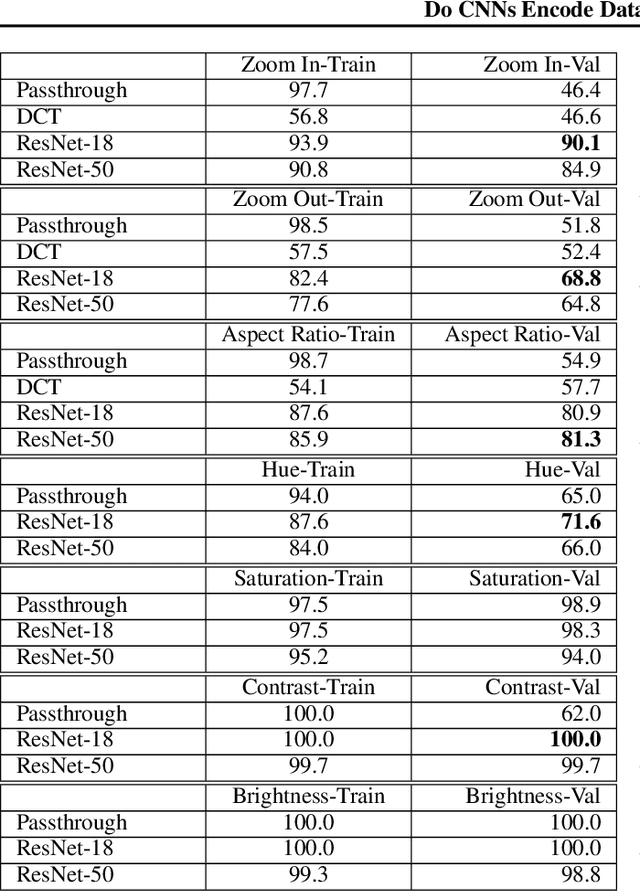

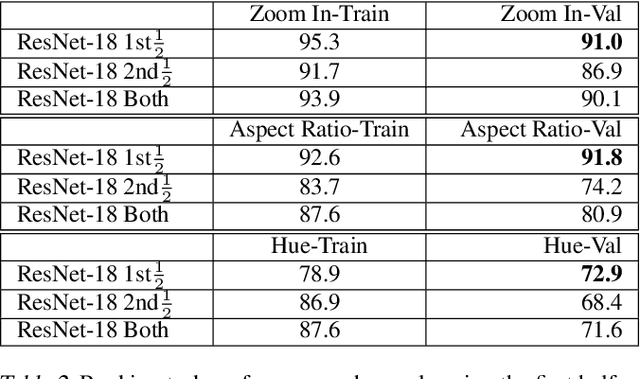
Data augmentations are an important ingredient in the recipe for training robust neural networks, especially in computer vision. A fundamental question is whether neural network features explicitly encode data augmentation transformations. To answer this question, we introduce a systematic approach to investigate which layers of neural networks are the most predictive of augmentation transformations. Our approach uses layer features in pre-trained vision models with minimal additional processing to predict common properties transformed by augmentation (scale, aspect ratio, hue, saturation, contrast, brightness). Surprisingly, neural network features not only predict data augmentation transformations, but they predict many transformations with high accuracy. After validating that neural networks encode features corresponding to augmentation transformations, we show that these features are primarily encoded in the early layers of modern CNNs.
Learning to Optimize Tensor Programs
Oct 27, 2018

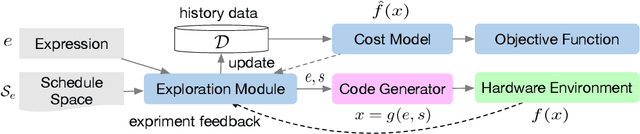

We introduce a learning-based framework to optimize tensor programs for deep learning workloads. Efficient implementations of tensor operators, such as matrix multiplication and high dimensional convolution, are key enablers of effective deep learning systems. However, existing systems rely on manually optimized libraries such as cuDNN where only a narrow range of server class GPUs are well-supported. The reliance on hardware-specific operator libraries limits the applicability of high-level graph optimizations and incurs significant engineering costs when deploying to new hardware targets. We use learning to remove this engineering burden. We learn domain-specific statistical cost models to guide the search of tensor operator implementations over billions of possible program variants. We further accelerate the search by effective model transfer across workloads. Experimental results show that our framework delivers performance competitive with state-of-the-art hand-tuned libraries for low-power CPU, mobile GPU, and server-class GPU.
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
Oct 05, 2018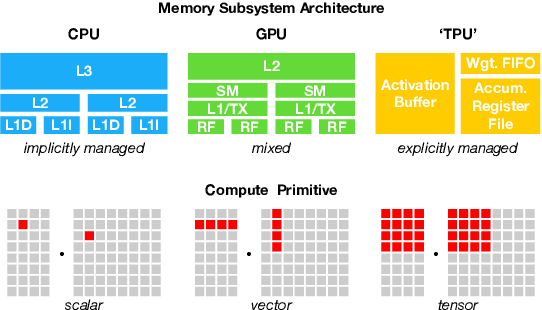
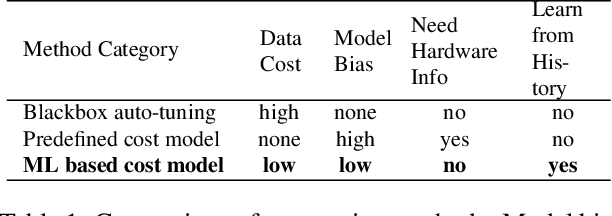
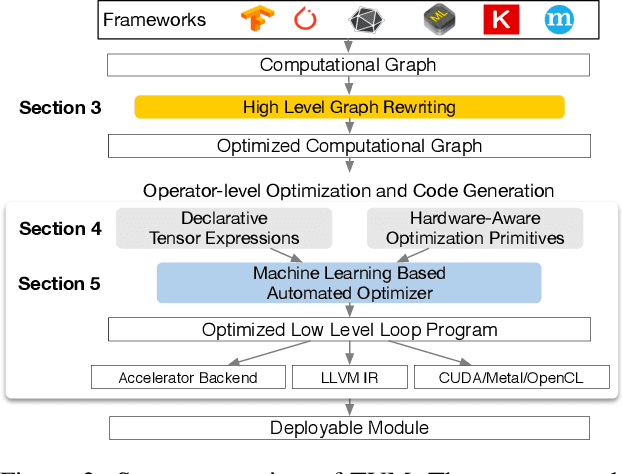
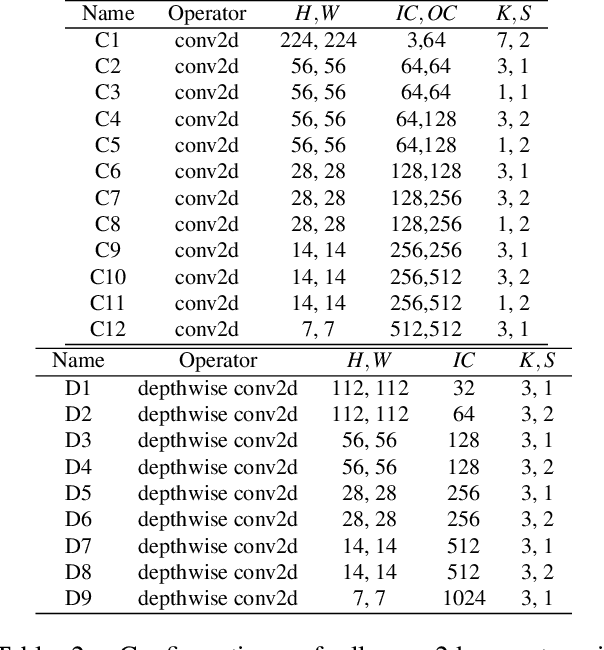
There is an increasing need to bring machine learning to a wide diversity of hardware devices. Current frameworks rely on vendor-specific operator libraries and optimize for a narrow range of server-class GPUs. Deploying workloads to new platforms -- such as mobile phones, embedded devices, and accelerators (e.g., FPGAs, ASICs) -- requires significant manual effort. We propose TVM, a compiler that exposes graph-level and operator-level optimizations to provide performance portability to deep learning workloads across diverse hardware back-ends. TVM solves optimization challenges specific to deep learning, such as high-level operator fusion, mapping to arbitrary hardware primitives, and memory latency hiding. It also automates optimization of low-level programs to hardware characteristics by employing a novel, learning-based cost modeling method for rapid exploration of code optimizations. Experimental results show that TVM delivers performance across hardware back-ends that are competitive with state-of-the-art, hand-tuned libraries for low-power CPU, mobile GPU, and server-class GPUs. We also demonstrate TVM's ability to target new accelerator back-ends, such as the FPGA-based generic deep learning accelerator. The system is open sourced and in production use inside several major companies.