 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutellix: An Efficient Serving Engine for LLM Agents as General Programs
Feb 19, 2025Large language model (LLM) applications are evolving beyond simple chatbots into dynamic, general-purpose agentic programs, which scale LLM calls and output tokens to help AI agents reason, explore, and solve complex tasks. However, existing LLM serving systems ignore dependencies between programs and calls, missing significant opportunities for optimization. Our analysis reveals that programs submitted to LLM serving engines experience long cumulative wait times, primarily due to head-of-line blocking at both the individual LLM request and the program. To address this, we introduce Autellix, an LLM serving system that treats programs as first-class citizens to minimize their end-to-end latencies. Autellix intercepts LLM calls submitted by programs, enriching schedulers with program-level context. We propose two scheduling algorithms-for single-threaded and distributed programs-that preempt and prioritize LLM calls based on their programs' previously completed calls. Our evaluation demonstrates that across diverse LLMs and agentic workloads, Autellix improves throughput of programs by 4-15x at the same latency compared to state-of-the-art systems, such as vLLM.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Stylus: Automatic Adapter Selection for Diffusion Models
Apr 29, 2024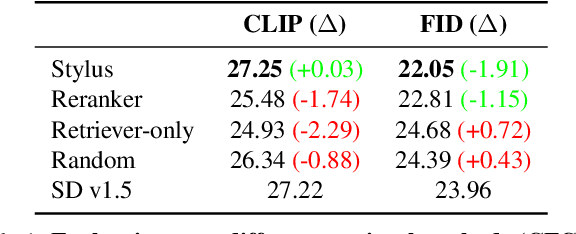
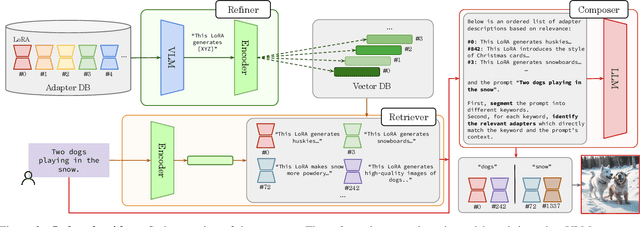

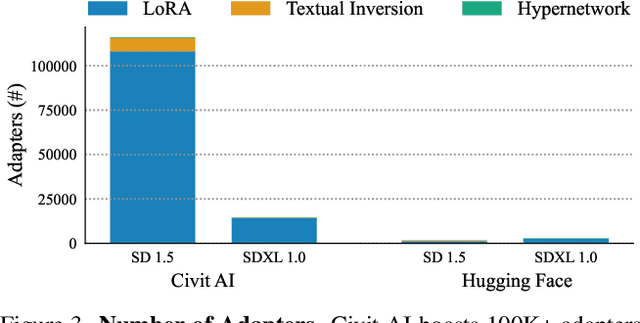
Beyond scaling base models with more data or parameters, fine-tuned adapters provide an alternative way to generate high fidelity, custom images at reduced costs. As such, adapters have been widely adopted by open-source communities, accumulating a database of over 100K adapters-most of which are highly customized with insufficient descriptions. This paper explores the problem of matching the prompt to a set of relevant adapters, built on recent work that highlight the performance gains of composing adapters. We introduce Stylus, which efficiently selects and automatically composes task-specific adapters based on a prompt's keywords. Stylus outlines a three-stage approach that first summarizes adapters with improved descriptions and embeddings, retrieves relevant adapters, and then further assembles adapters based on prompts' keywords by checking how well they fit the prompt. To evaluate Stylus, we developed StylusDocs, a curated dataset featuring 75K adapters with pre-computed adapter embeddings. In our evaluation on popular Stable Diffusion checkpoints, Stylus achieves greater CLIP-FID Pareto efficiency and is twice as preferred, with humans and multimodal models as evaluators, over the base model. See stylus-diffusion.github.io for more.
Controlled Decoding from Language Models
Oct 25, 2023



We propose controlled decoding (CD), a novel off-policy reinforcement learning method to control the autoregressive generation from language models towards high reward outcomes. CD solves an off-policy reinforcement learning problem through a value function for the reward, which we call a prefix scorer. The prefix scorer is used at inference time to steer the generation towards higher reward outcomes. We show that the prefix scorer may be trained on (possibly) off-policy data to predict the expected reward when decoding is continued from a partially decoded response. We empirically demonstrate that CD is effective as a control mechanism on Reddit conversations corpus. We also show that the modularity of the design of CD makes it possible to control for multiple rewards, effectively solving a multi-objective reinforcement learning problem with no additional complexity. Finally, we show that CD can be applied in a novel blockwise fashion at inference-time, again without the need for any training-time changes, essentially bridging the gap between the popular best-of-$K$ strategy and token-level reinforcement learning. This makes CD a promising approach for alignment of language models.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Jul 03, 2023



In this work, we introduce Semantic Pyramid AutoEncoder (SPAE) for enabling frozen LLMs to perform both understanding and generation tasks involving non-linguistic modalities such as images or videos. SPAE converts between raw pixels and interpretable lexical tokens (or words) extracted from the LLM's vocabulary. The resulting tokens capture both the semantic meaning and the fine-grained details needed for visual reconstruction, effectively translating the visual content into a language comprehensible to the LLM, and empowering it to perform a wide array of multimodal tasks. Our approach is validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks. Our method marks the first successful attempt to enable a frozen LLM to generate image content while surpassing state-of-the-art performance in image understanding tasks, under the same setting, by over 25%.
Brainformers: Trading Simplicity for Efficiency
May 29, 2023



Transformers are central to recent successes in natural language processing and computer vision. Transformers have a mostly uniform backbone where layers alternate between feed-forward and self-attention in order to build a deep network. Here we investigate this design choice and find that more complex blocks that have different permutations of layer primitives can be more efficient. Using this insight, we develop a complex block, named Brainformer, that consists of a diverse sets of layers such as sparsely gated feed-forward layers, dense feed-forward layers, attention layers, and various forms of layer normalization and activation functions. Brainformer consistently outperforms the state-of-the-art dense and sparse Transformers, in terms of both quality and efficiency. A Brainformer model with 8 billion activated parameters per token demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart. In downstream task evaluation, Brainformer also demonstrates a 3% higher SuperGLUE score with fine-tuning compared to GLaM with a similar number of activated parameters. Finally, Brainformer largely outperforms a Primer dense model derived with NAS with similar computation per token on fewshot evaluations.
Lifelong Language Pretraining with Distribution-Specialized Experts
May 20, 2023
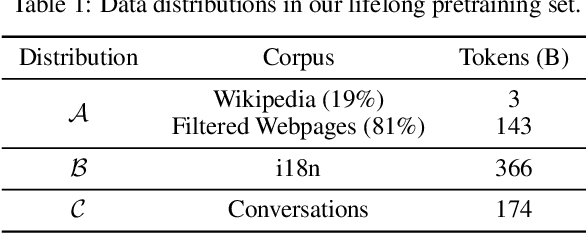

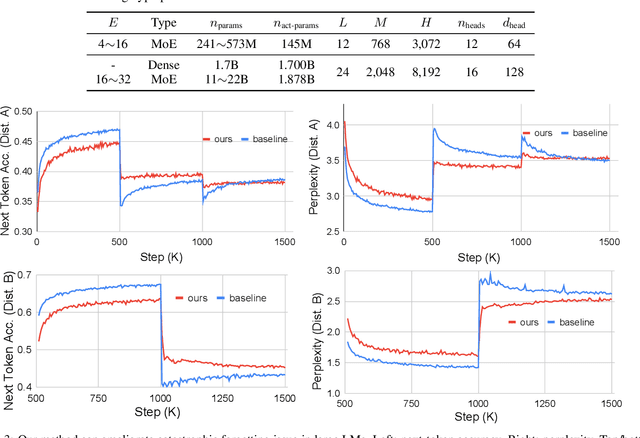
Pretraining on a large-scale corpus has become a standard method to build general language models (LMs). Adapting a model to new data distributions targeting different downstream tasks poses significant challenges. Naive fine-tuning may incur catastrophic forgetting when the over-parameterized LMs overfit the new data but fail to preserve the pretrained features. Lifelong learning (LLL) aims to enable information systems to learn from a continuous data stream across time. However, most prior work modifies the training recipe assuming a static fixed network architecture. We find that additional model capacity and proper regularization are key elements to achieving strong LLL performance. Thus, we propose Lifelong-MoE, an extensible MoE (Mixture-of-Experts) architecture that dynamically adds model capacity via adding experts with regularized pretraining. Our results show that by only introducing a limited number of extra experts while keeping the computation cost constant, our model can steadily adapt to data distribution shifts while preserving the previous knowledge. Compared to existing lifelong learning approaches, Lifelong-MoE achieves better few-shot performance on 19 downstream NLP tasks.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving
Feb 22, 2023Model parallelism is conventionally viewed as a method to scale a single large deep learning model beyond the memory limits of a single device. In this paper, we demonstrate that model parallelism can be additionally used for the statistical multiplexing of multiple devices when serving multiple models, even when a single model can fit into a single device. Our work reveals a fundamental trade-off between the overhead introduced by model parallelism and the opportunity to exploit statistical multiplexing to reduce serving latency in the presence of bursty workloads. We explore the new trade-off space and present a novel serving system, AlpaServe, that determines an efficient strategy for placing and parallelizing collections of large deep learning models across a distributed cluster. Evaluation results on production workloads show that AlpaServe can process requests at up to 10x higher rates or 6x more burstiness while staying within latency constraints for more than 99% of requests.
Massively Multilingual Shallow Fusion with Large Language Models
Feb 17, 2023While large language models (LLM) have made impressive progress in natural language processing, it remains unclear how to utilize them in improving automatic speech recognition (ASR). In this work, we propose to train a single multilingual language model (LM) for shallow fusion in multiple languages. We push the limits of the multilingual LM to cover up to 84 languages by scaling up using a mixture-of-experts LLM, i.e., generalist language model (GLaM). When the number of experts increases, GLaM dynamically selects only two at each decoding step to keep the inference computation roughly constant. We then apply GLaM to a multilingual shallow fusion task based on a state-of-the-art end-to-end model. Compared to a dense LM of similar computation during inference, GLaM reduces the WER of an English long-tail test set by 4.4% relative. In a multilingual shallow fusion task, GLaM improves 41 out of 50 languages with an average relative WER reduction of 3.85%, and a maximum reduction of 10%. Compared to the baseline model, GLaM achieves an average WER reduction of 5.53% over 43 languages.