 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Self-Training (ReST) for Language Modeling
Aug 21, 2023Reinforcement learning from human feedback (RLHF) can improve the quality of large language model's (LLM) outputs by aligning them with human preferences. We propose a simple algorithm for aligning LLMs with human preferences inspired by growing batch reinforcement learning (RL), which we call Reinforced Self-Training (ReST). Given an initial LLM policy, ReST produces a dataset by generating samples from the policy, which are then used to improve the LLM policy using offline RL algorithms. ReST is more efficient than typical online RLHF methods because the training dataset is produced offline, which allows data reuse. While ReST is a general approach applicable to all generative learning settings, we focus on its application to machine translation. Our results show that ReST can substantially improve translation quality, as measured by automated metrics and human evaluation on machine translation benchmarks in a compute and sample-efficient manner.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Jul 03, 2023



In this work, we introduce Semantic Pyramid AutoEncoder (SPAE) for enabling frozen LLMs to perform both understanding and generation tasks involving non-linguistic modalities such as images or videos. SPAE converts between raw pixels and interpretable lexical tokens (or words) extracted from the LLM's vocabulary. The resulting tokens capture both the semantic meaning and the fine-grained details needed for visual reconstruction, effectively translating the visual content into a language comprehensible to the LLM, and empowering it to perform a wide array of multimodal tasks. Our approach is validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks. Our method marks the first successful attempt to enable a frozen LLM to generate image content while surpassing state-of-the-art performance in image understanding tasks, under the same setting, by over 25%.
Mu$^{2}$SLAM: Multitask, Multilingual Speech and Language Models
Dec 19, 2022



We present Mu$^{2}$SLAM, a multilingual sequence-to-sequence model pre-trained jointly on unlabeled speech, unlabeled text and supervised data spanning Automatic Speech Recognition (ASR), Automatic Speech Translation (AST) and Machine Translation (MT), in over 100 languages. By leveraging a quantized representation of speech as a target, Mu$^{2}$SLAM trains the speech-text models with a sequence-to-sequence masked denoising objective similar to T5 on the decoder and a masked language modeling (MLM) objective on the encoder, for both unlabeled speech and text, while utilizing the supervised tasks to improve cross-lingual and cross-modal representation alignment within the model. On CoVoST AST, Mu$^{2}$SLAM establishes a new state-of-the-art for models trained on public datasets, improving on xx-en translation over the previous best by 1.9 BLEU points and on en-xx translation by 1.1 BLEU points. On Voxpopuli ASR, our model matches the performance of an mSLAM model fine-tuned with an RNN-T decoder, despite using a relatively weaker sequence-to-sequence architecture. On text understanding tasks, our model improves by more than 6\% over mSLAM on XNLI, getting closer to the performance of mT5 models of comparable capacity on XNLI and TydiQA, paving the way towards a single model for all speech and text understanding tasks.
Building Machine Translation Systems for the Next Thousand Languages
May 16, 2022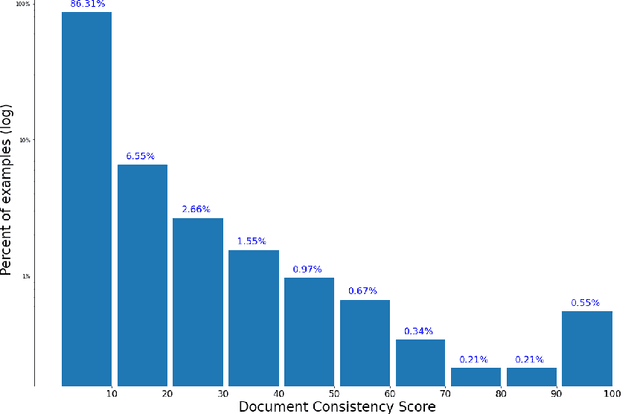
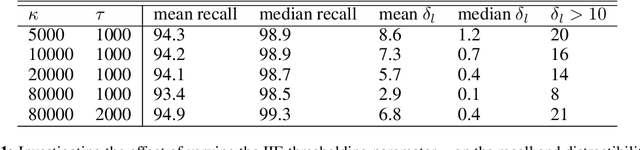

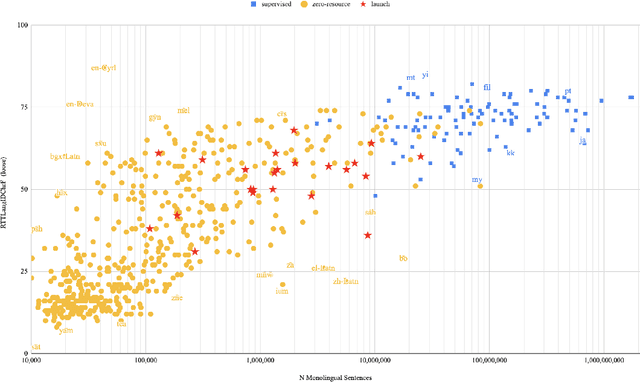
In this paper we share findings from our effort to build practical machine translation (MT) systems capable of translating across over one thousand languages. We describe results in three research domains: (i) Building clean, web-mined datasets for 1500+ languages by leveraging semi-supervised pre-training for language identification and developing data-driven filtering techniques; (ii) Developing practical MT models for under-served languages by leveraging massively multilingual models trained with supervised parallel data for over 100 high-resource languages and monolingual datasets for an additional 1000+ languages; and (iii) Studying the limitations of evaluation metrics for these languages and conducting qualitative analysis of the outputs from our MT models, highlighting several frequent error modes of these types of models. We hope that our work provides useful insights to practitioners working towards building MT systems for currently understudied languages, and highlights research directions that can complement the weaknesses of massively multilingual models in data-sparse settings.
Multilingual Mix: Example Interpolation Improves Multilingual Neural Machine Translation
Mar 15, 2022
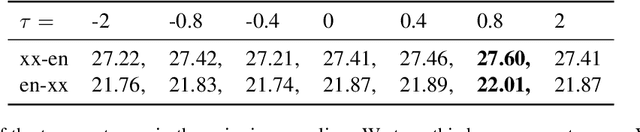

Multilingual neural machine translation models are trained to maximize the likelihood of a mix of examples drawn from multiple language pairs. The dominant inductive bias applied to these models is a shared vocabulary and a shared set of parameters across languages; the inputs and labels corresponding to examples drawn from different language pairs might still reside in distinct sub-spaces. In this paper, we introduce multilingual crossover encoder-decoder (mXEncDec) to fuse language pairs at an instance level. Our approach interpolates instances from different language pairs into joint `crossover examples' in order to encourage sharing input and output spaces across languages. To ensure better fusion of examples in multilingual settings, we propose several techniques to improve example interpolation across dissimilar languages under heavy data imbalance. Experiments on a large-scale WMT multilingual dataset demonstrate that our approach significantly improves quality on English-to-Many, Many-to-English and zero-shot translation tasks (from +0.5 BLEU up to +5.5 BLEU points). Results on code-switching sets demonstrate the capability of our approach to improve model generalization to out-of-distribution multilingual examples. We also conduct qualitative and quantitative representation comparisons to analyze the advantages of our approach at the representation level.
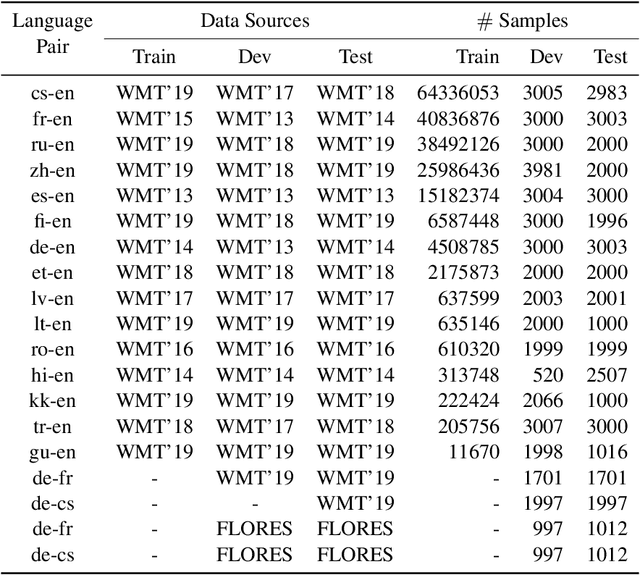
Self-supervised and Supervised Joint Training for Resource-rich Machine Translation
Jun 08, 2021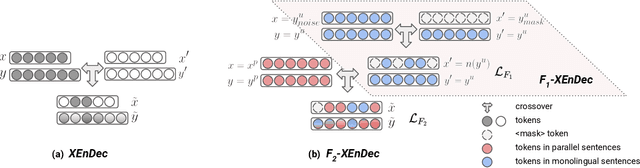

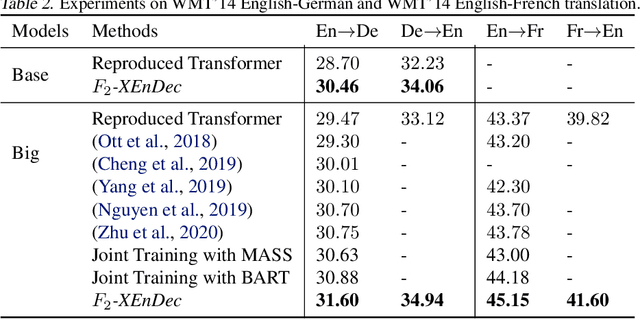
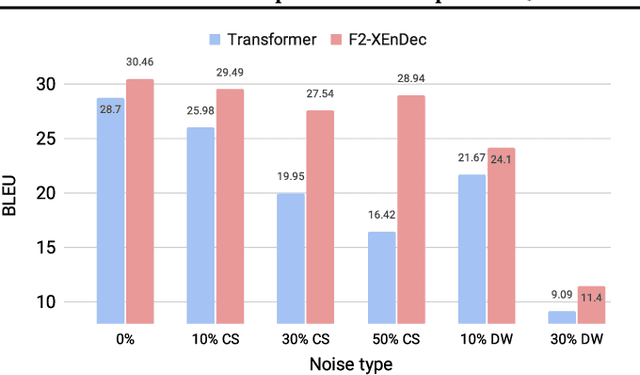
Self-supervised pre-training of text representations has been successfully applied to low-resource Neural Machine Translation (NMT). However, it usually fails to achieve notable gains on resource-rich NMT. In this paper, we propose a joint training approach, $F_2$-XEnDec, to combine self-supervised and supervised learning to optimize NMT models. To exploit complementary self-supervised signals for supervised learning, NMT models are trained on examples that are interbred from monolingual and parallel sentences through a new process called crossover encoder-decoder. Experiments on two resource-rich translation benchmarks, WMT'14 English-German and WMT'14 English-French, demonstrate that our approach achieves substantial improvements over several strong baseline methods and obtains a new state of the art of 46.19 BLEU on English-French when incorporating back translation. Results also show that our approach is capable of improving model robustness to input perturbations such as code-switching noise which frequently appears on social media.
Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation
Apr 29, 2021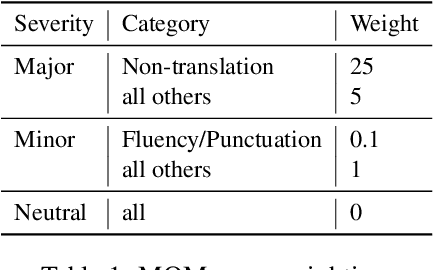
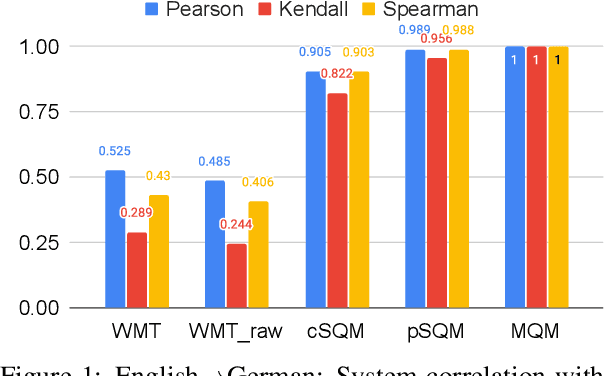
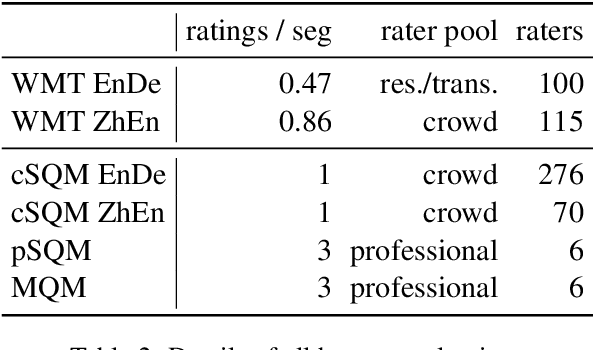
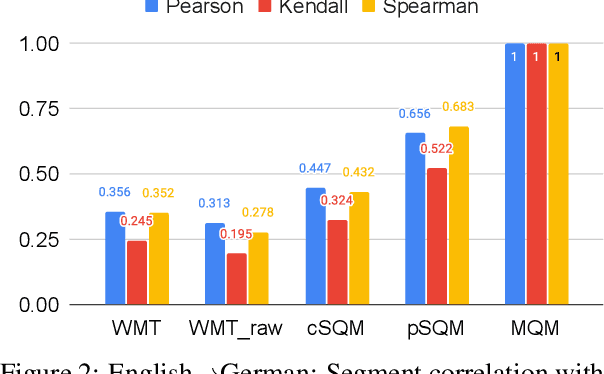
Human evaluation of modern high-quality machine translation systems is a difficult problem, and there is increasing evidence that inadequate evaluation procedures can lead to erroneous conclusions. While there has been considerable research on human evaluation, the field still lacks a commonly-accepted standard procedure. As a step toward this goal, we propose an evaluation methodology grounded in explicit error analysis, based on the Multidimensional Quality Metrics (MQM) framework. We carry out the largest MQM research study to date, scoring the outputs of top systems from the WMT 2020 shared task in two language pairs using annotations provided by professional translators with access to full document context. We analyze the resulting data extensively, finding among other results a substantially different ranking of evaluated systems from the one established by the WMT crowd workers, exhibiting a clear preference for human over machine output. Surprisingly, we also find that automatic metrics based on pre-trained embeddings can outperform human crowd workers. We make our corpus publicly available for further research.
KoBE: Knowledge-Based Machine Translation Evaluation
Sep 23, 2020
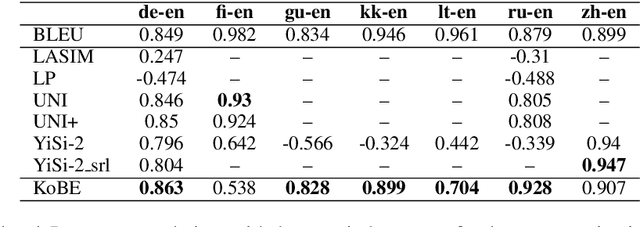
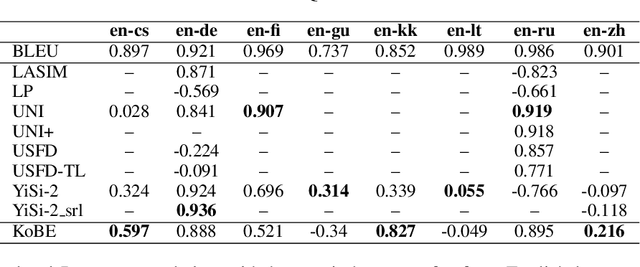
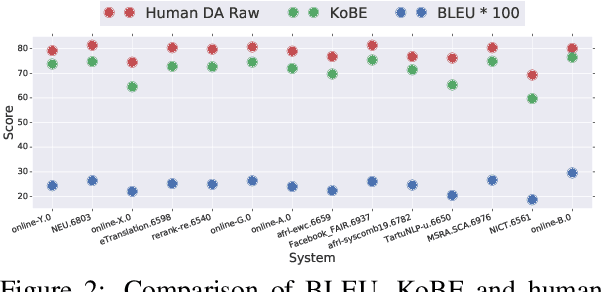
We propose a simple and effective method for machine translation evaluation which does not require reference translations. Our approach is based on (1) grounding the entity mentions found in each source sentence and candidate translation against a large-scale multilingual knowledge base, and (2) measuring the recall of the grounded entities found in the candidate vs. those found in the source. Our approach achieves the highest correlation with human judgements on 9 out of the 18 language pairs from the WMT19 benchmark for evaluation without references, which is the largest number of wins for a single evaluation method on this task. On 4 language pairs, we also achieve higher correlation with human judgements than BLEU. To foster further research, we release a dataset containing 1.8 million grounded entity mentions across 18 language pairs from the WMT19 metrics track data.
AdvAug: Robust Adversarial Augmentation for Neural Machine Translation
Jul 03, 2020

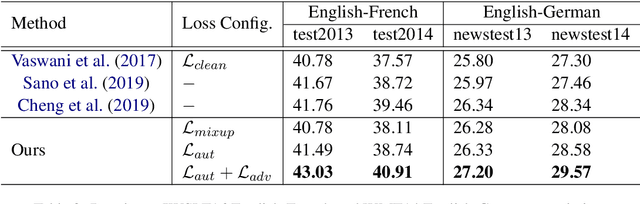
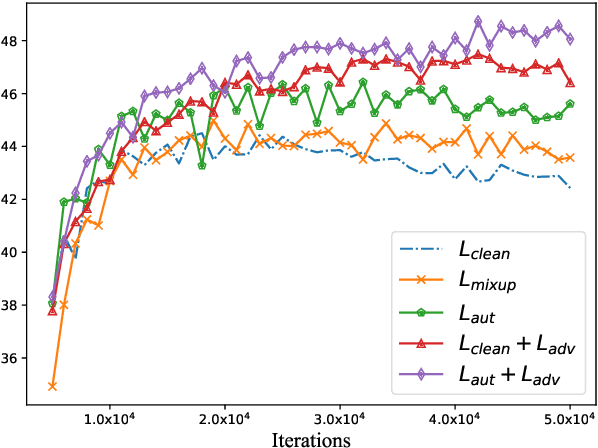
In this paper, we propose a new adversarial augmentation method for Neural Machine Translation (NMT). The main idea is to minimize the vicinal risk over virtual sentences sampled from two vicinity distributions, of which the crucial one is a novel vicinity distribution for adversarial sentences that describes a smooth interpolated embedding space centered around observed training sentence pairs. We then discuss our approach, AdvAug, to train NMT models using the embeddings of virtual sentences in sequence-to-sequence learning. Experiments on Chinese-English, English-French, and English-German translation benchmarks show that AdvAug achieves significant improvements over the Transformer (up to 4.9 BLEU points), and substantially outperforms other data augmentation techniques (e.g. back-translation) without using extra corpora.
Re-translation versus Streaming for Simultaneous Translation
Apr 14, 2020
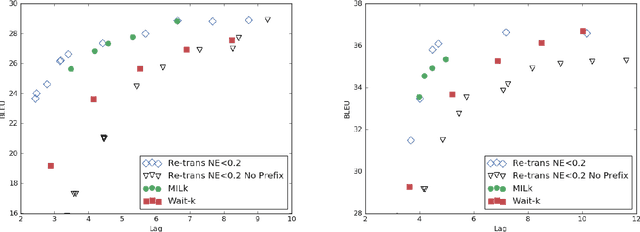

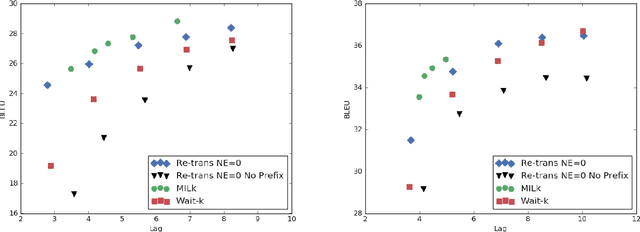
There has been great progress in improving streaming machine translation, a simultaneous paradigm where the system appends to a growing hypothesis as more source content becomes available. We study a related problem in which revisions to the hypothesis beyond strictly appending words are permitted. This is suitable for applications such as live captioning an audio feed. In this setting, we compare custom streaming approaches to re-translation, a straightforward strategy where each new source token triggers a distinct translation from scratch. We find re-translation to be as good or better than state-of-the-art streaming systems, even when operating under constraints that allow very few revisions. We attribute much of this success to a previously proposed data-augmentation technique that adds prefix-pairs to the training data, which alongside wait-k inference forms a strong baseline for streaming translation. We also highlight re-translation's ability to wrap arbitrarily powerful MT systems with an experiment showing large improvements from an upgrade to its base model.