 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Agnostic Prompt Learning for Multi-Modal Camouflaged Object Detection
Apr 14, 2026Camouflaged Object Detection (COD) aims to segment objects that blend seamlessly into complex backgrounds, with growing interest in exploiting additional visual modalities to enhance robustness through complementary information. However, most existing approaches generally rely on modality-specific architectures or customized fusion strategies, which limit scalability and cross-modal generalization. To address this, we propose a novel framework that generates modality-agnostic multi-modal prompts for the Segment Anything Model (SAM), enabling parameter-efficient adaptation to arbitrary auxiliary modalities and significantly improving overall performance on COD tasks. Specifically, we model multi-modal learning through interactions between a data-driven content domain and a knowledge-driven prompt domain, distilling task-relevant cues into unified prompts for SAM decoding. We further introduce a lightweight Mask Refine Module to calibrate coarse predictions by incorporating fine-grained prompt cues, leading to more accurate camouflaged object boundaries. Extensive experiments on RGB-Depth, RGB-Thermal, and RGB-Polarization benchmarks validate the effectiveness and generalization of our modality-agnostic framework.
Uni-FinLLM: A Unified Multimodal Large Language Model with Modular Task Heads for Micro-Level Stock Prediction and Macro-Level Systemic Risk Assessment
Jan 06, 2026Financial institutions and regulators require systems that integrate heterogeneous data to assess risks from stock fluctuations to systemic vulnerabilities. Existing approaches often treat these tasks in isolation, failing to capture cross-scale dependencies. We propose Uni-FinLLM, a unified multimodal large language model that uses a shared Transformer backbone and modular task heads to jointly process financial text, numerical time series, fundamentals, and visual data. Through cross-modal attention and multi-task optimization, it learns a coherent representation for micro-, meso-, and macro-level predictions. Evaluated on stock forecasting, credit-risk assessment, and systemic-risk detection, Uni-FinLLM significantly outperforms baselines. It raises stock directional accuracy to 67.4% (from 61.7%), credit-risk accuracy to 84.1% (from 79.6%), and macro early-warning accuracy to 82.3%. Results validate that a unified multimodal LLM can jointly model asset behavior and systemic vulnerabilities, offering a scalable decision-support engine for finance.
Mixture of Contexts for Long Video Generation
Aug 28, 2025Long video generation is fundamentally a long context memory problem: models must retain and retrieve salient events across a long range without collapsing or drifting. However, scaling diffusion transformers to generate long-context videos is fundamentally limited by the quadratic cost of self-attention, which makes memory and computation intractable and difficult to optimize for long sequences. We recast long-context video generation as an internal information retrieval task and propose a simple, learnable sparse attention routing module, Mixture of Contexts (MoC), as an effective long-term memory retrieval engine. In MoC, each query dynamically selects a few informative chunks plus mandatory anchors (caption, local windows) to attend to, with causal routing that prevents loop closures. As we scale the data and gradually sparsify the routing, the model allocates compute to salient history, preserving identities, actions, and scenes over minutes of content. Efficiency follows as a byproduct of retrieval (near-linear scaling), which enables practical training and synthesis, and the emergence of memory and consistency at the scale of minutes.
Captain Cinema: Towards Short Movie Generation
Jul 24, 2025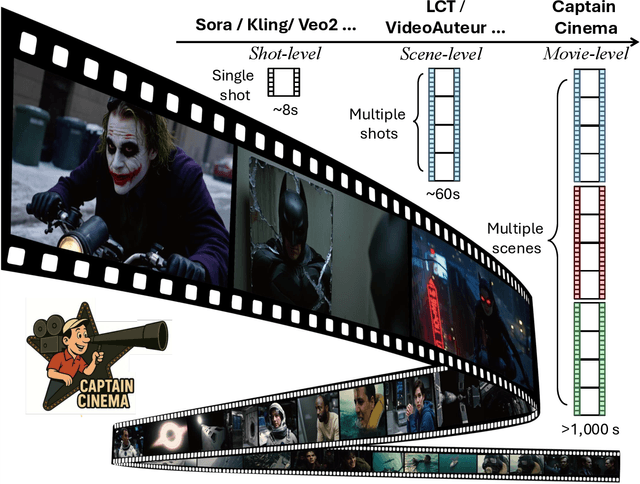
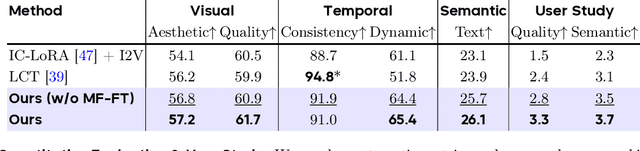

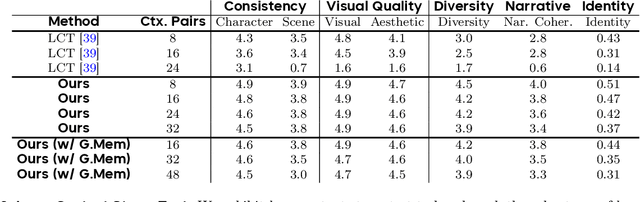
We present Captain Cinema, a generation framework for short movie generation. Given a detailed textual description of a movie storyline, our approach firstly generates a sequence of keyframes that outline the entire narrative, which ensures long-range coherence in both the storyline and visual appearance (e.g., scenes and characters). We refer to this step as top-down keyframe planning. These keyframes then serve as conditioning signals for a video synthesis model, which supports long context learning, to produce the spatio-temporal dynamics between them. This step is referred to as bottom-up video synthesis. To support stable and efficient generation of multi-scene long narrative cinematic works, we introduce an interleaved training strategy for Multimodal Diffusion Transformers (MM-DiT), specifically adapted for long-context video data. Our model is trained on a specially curated cinematic dataset consisting of interleaved data pairs. Our experiments demonstrate that Captain Cinema performs favorably in the automated creation of visually coherent and narrative consistent short movies in high quality and efficiency. Project page: https://thecinema.ai
Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations
Jun 23, 2025
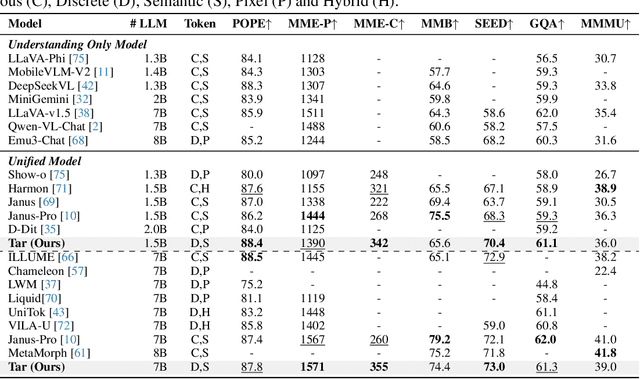
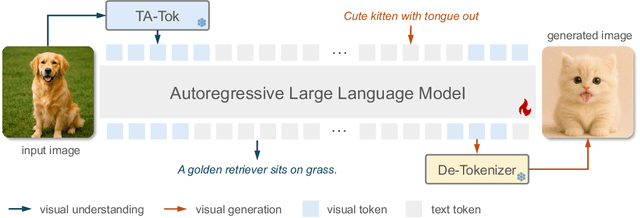
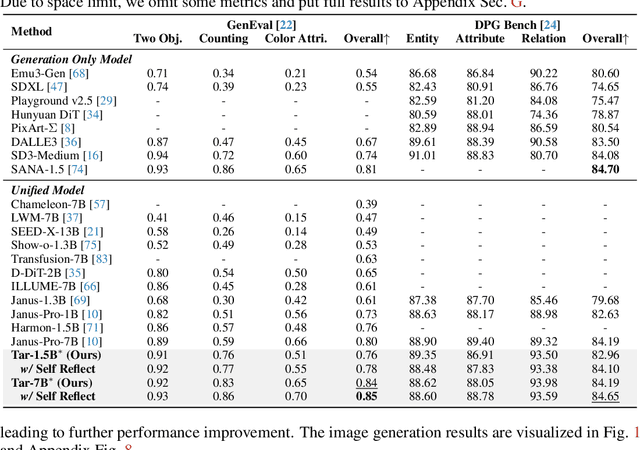
This paper presents a multimodal framework that attempts to unify visual understanding and generation within a shared discrete semantic representation. At its core is the Text-Aligned Tokenizer (TA-Tok), which converts images into discrete tokens using a text-aligned codebook projected from a large language model's (LLM) vocabulary. By integrating vision and text into a unified space with an expanded vocabulary, our multimodal LLM, Tar, enables cross-modal input and output through a shared interface, without the need for modality-specific designs. Additionally, we propose scale-adaptive encoding and decoding to balance efficiency and visual detail, along with a generative de-tokenizer to produce high-fidelity visual outputs. To address diverse decoding needs, we utilize two complementary de-tokenizers: a fast autoregressive model and a diffusion-based model. To enhance modality fusion, we investigate advanced pre-training tasks, demonstrating improvements in both visual understanding and generation. Experiments across benchmarks show that Tar matches or surpasses existing multimodal LLM methods, achieving faster convergence and greater training efficiency. Code, models, and data are available at https://tar.csuhan.com
VINCIE: Unlocking In-context Image Editing from Video
Jun 12, 2025In-context image editing aims to modify images based on a contextual sequence comprising text and previously generated images. Existing methods typically depend on task-specific pipelines and expert models (e.g., segmentation and inpainting) to curate training data. In this work, we explore whether an in-context image editing model can be learned directly from videos. We introduce a scalable approach to annotate videos as interleaved multimodal sequences. To effectively learn from this data, we design a block-causal diffusion transformer trained on three proxy tasks: next-image prediction, current segmentation prediction, and next-segmentation prediction. Additionally, we propose a novel multi-turn image editing benchmark to advance research in this area. Extensive experiments demonstrate that our model exhibits strong in-context image editing capabilities and achieves state-of-the-art results on two multi-turn image editing benchmarks. Despite being trained exclusively on videos, our model also shows promising abilities in multi-concept composition, story generation, and chain-of-editing applications.
Autoregressive Adversarial Post-Training for Real-Time Interactive Video Generation
Jun 11, 2025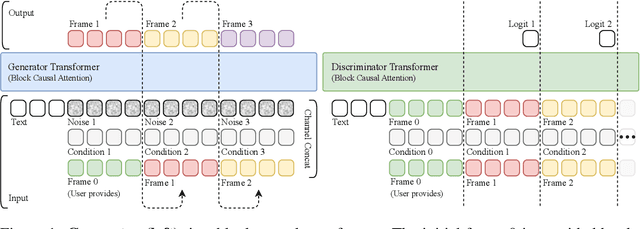
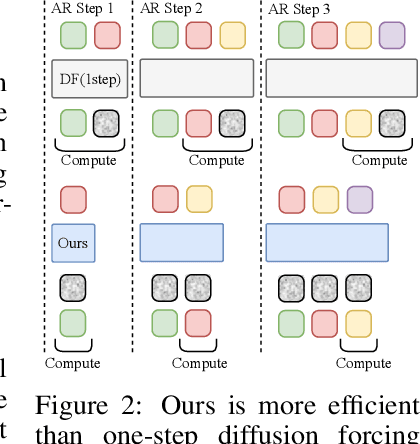
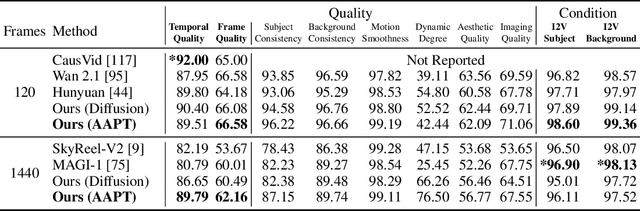

Existing large-scale video generation models are computationally intensive, preventing adoption in real-time and interactive applications. In this work, we propose autoregressive adversarial post-training (AAPT) to transform a pre-trained latent video diffusion model into a real-time, interactive video generator. Our model autoregressively generates a latent frame at a time using a single neural function evaluation (1NFE). The model can stream the result to the user in real time and receive interactive responses as controls to generate the next latent frame. Unlike existing approaches, our method explores adversarial training as an effective paradigm for autoregressive generation. This not only allows us to design an architecture that is more efficient for one-step generation while fully utilizing the KV cache, but also enables training the model in a student-forcing manner that proves to be effective in reducing error accumulation during long video generation. Our experiments demonstrate that our 8B model achieves real-time, 24fps, streaming video generation at 736x416 resolution on a single H100, or 1280x720 on 8xH100 up to a minute long (1440 frames). Visit our research website at https://seaweed-apt.com/2
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025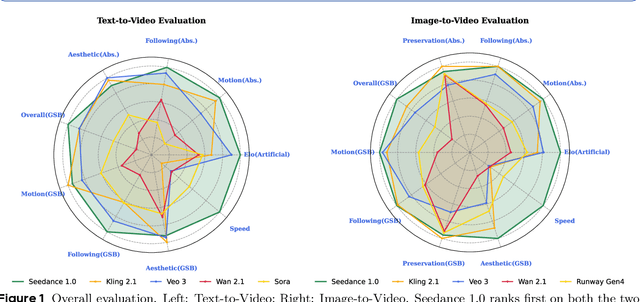
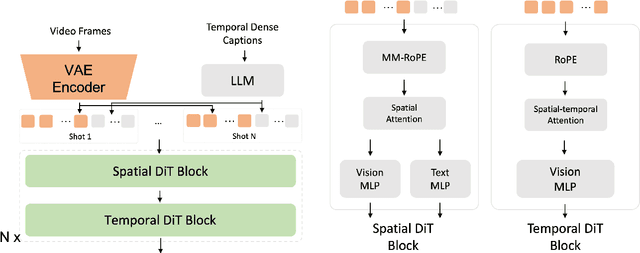
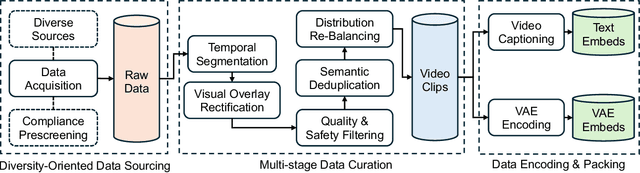
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
Jun 05, 2025



Recent advances in diffusion-based video restoration (VR) demonstrate significant improvement in visual quality, yet yield a prohibitive computational cost during inference. While several distillation-based approaches have exhibited the potential of one-step image restoration, extending existing approaches to VR remains challenging and underexplored, particularly when dealing with high-resolution video in real-world settings. In this work, we propose a one-step diffusion-based VR model, termed as SeedVR2, which performs adversarial VR training against real data. To handle the challenging high-resolution VR within a single step, we introduce several enhancements to both model architecture and training procedures. Specifically, an adaptive window attention mechanism is proposed, where the window size is dynamically adjusted to fit the output resolutions, avoiding window inconsistency observed under high-resolution VR using window attention with a predefined window size. To stabilize and improve the adversarial post-training towards VR, we further verify the effectiveness of a series of losses, including a proposed feature matching loss without significantly sacrificing training efficiency. Extensive experiments show that SeedVR2 can achieve comparable or even better performance compared with existing VR approaches in a single step.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
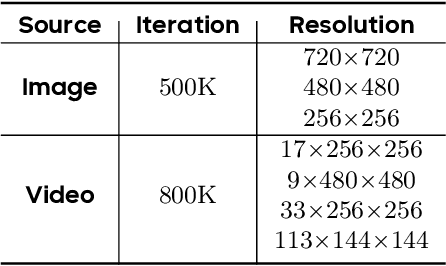
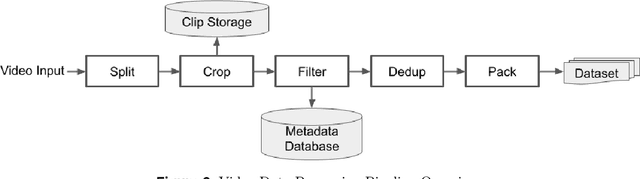

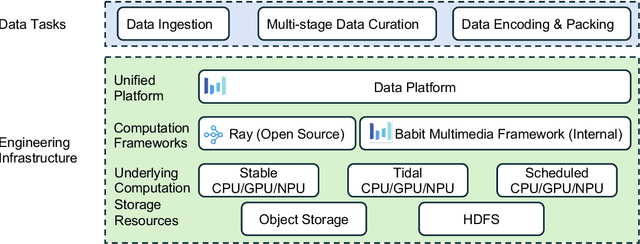
This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/