 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTok: A Unified Video Tokenizer with Decoupled Spatial-Temporal Latents
Feb 04, 2026This work presents VTok, a unified video tokenization framework that can be used for both generation and understanding tasks. Unlike the leading vision-language systems that tokenize videos through a naive frame-sampling strategy, we propose to decouple the spatial and temporal representations of videos by retaining the spatial features of a single key frame while encoding each subsequent frame into a single residual token, achieving compact yet expressive video tokenization. Our experiments suggest that VTok effectively reduces the complexity of video representation from the product of frame count and per-frame token count to their sum, while the residual tokens sufficiently capture viewpoint and motion changes relative to the key frame. Extensive evaluations demonstrate the efficacy and efficiency of VTok: it achieves notably higher performance on a range of video understanding and text-to-video generation benchmarks compared with baselines using naive tokenization, all with shorter token sequences per video (e.g., 3.4% higher accuracy on our TV-Align benchmark and 1.9% higher VBench score). Remarkably, VTok produces more coherent motion and stronger guidance following in text-to-video generation, owing to its more consistent temporal encoding. We hope VTok can serve as a standardized video tokenization paradigm for future research in video understanding and generation.
VINCIE: Unlocking In-context Image Editing from Video
Jun 12, 2025In-context image editing aims to modify images based on a contextual sequence comprising text and previously generated images. Existing methods typically depend on task-specific pipelines and expert models (e.g., segmentation and inpainting) to curate training data. In this work, we explore whether an in-context image editing model can be learned directly from videos. We introduce a scalable approach to annotate videos as interleaved multimodal sequences. To effectively learn from this data, we design a block-causal diffusion transformer trained on three proxy tasks: next-image prediction, current segmentation prediction, and next-segmentation prediction. Additionally, we propose a novel multi-turn image editing benchmark to advance research in this area. Extensive experiments demonstrate that our model exhibits strong in-context image editing capabilities and achieves state-of-the-art results on two multi-turn image editing benchmarks. Despite being trained exclusively on videos, our model also shows promising abilities in multi-concept composition, story generation, and chain-of-editing applications.
SeedEdit 3.0: Fast and High-Quality Generative Image Editing
Jun 06, 2025We introduce SeedEdit 3.0, in companion with our T2I model Seedream 3.0, which significantly improves over our previous SeedEdit versions in both aspects of edit instruction following and image content (e.g., ID/IP) preservation on real image inputs. Additional to model upgrading with T2I, in this report, we present several key improvements. First, we develop an enhanced data curation pipeline with a meta-info paradigm and meta-info embedding strategy that help mix images from multiple data sources. This allows us to scale editing data effectively, and meta information is helpfult to connect VLM with diffusion model more closely. Second, we introduce a joint learning pipeline for computing a diffusion loss and reward losses. Finally, we evaluate SeedEdit 3.0 on our testing benchmarks, for real/synthetic image editing, where it achieves a best trade-off between multiple aspects, yielding a high usability rate of 56.1%, compared to SeedEdit 1.6 (38.4%), GPT4o (37.1%) and Gemini 2.0 (30.3%).
Seedream 3.0 Technical Report
Apr 16, 2025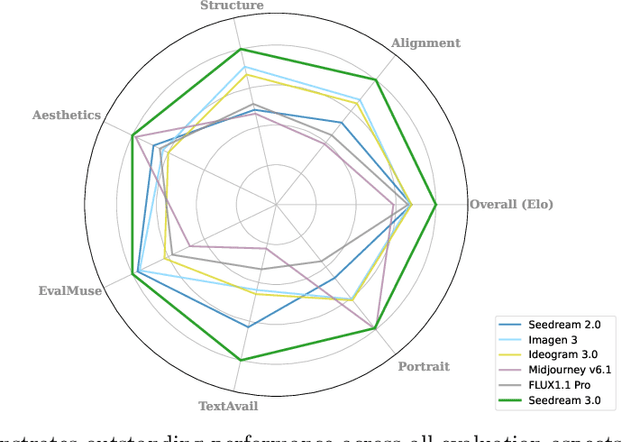


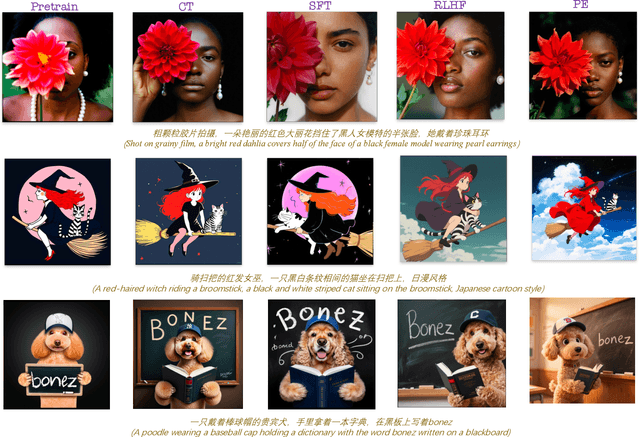
We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
X-Dyna: Expressive Dynamic Human Image Animation
Jan 20, 2025We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.
Dual Diffusion for Unified Image Generation and Understanding
Dec 31, 2024Diffusion models have gained tremendous success in text-to-image generation, yet still lag behind with visual understanding tasks, an area dominated by autoregressive vision-language models. We propose a large-scale and fully end-to-end diffusion model for multi-modal understanding and generation that significantly improves on existing diffusion-based multimodal models, and is the first of its kind to support the full suite of vision-language modeling capabilities. Inspired by the multimodal diffusion transformer (MM-DiT) and recent advances in discrete diffusion language modeling, we leverage a cross-modal maximum likelihood estimation framework that simultaneously trains the conditional likelihoods of both images and text jointly under a single loss function, which is back-propagated through both branches of the diffusion transformer. The resulting model is highly flexible and capable of a wide range of tasks including image generation, captioning, and visual question answering. Our model attained competitive performance compared to recent unified image understanding and generation models, demonstrating the potential of multimodal diffusion modeling as a promising alternative to autoregressive next-token prediction models.
MVLight: Relightable Text-to-3D Generation via Light-conditioned Multi-View Diffusion
Nov 18, 2024Recent advancements in text-to-3D generation, building on the success of high-performance text-to-image generative models, have made it possible to create imaginative and richly textured 3D objects from textual descriptions. However, a key challenge remains in effectively decoupling light-independent and lighting-dependent components to enhance the quality of generated 3D models and their relighting performance. In this paper, we present MVLight, a novel light-conditioned multi-view diffusion model that explicitly integrates lighting conditions directly into the generation process. This enables the model to synthesize high-quality images that faithfully reflect the specified lighting environment across multiple camera views. By leveraging this capability to Score Distillation Sampling (SDS), we can effectively synthesize 3D models with improved geometric precision and relighting capabilities. We validate the effectiveness of MVLight through extensive experiments and a user study.
SeedEdit: Align Image Re-Generation to Image Editing
Nov 11, 2024We introduce SeedEdit, a diffusion model that is able to revise a given image with any text prompt. In our perspective, the key to such a task is to obtain an optimal balance between maintaining the original image, i.e. image reconstruction, and generating a new image, i.e. image re-generation. To this end, we start from a weak generator (text-to-image model) that creates diverse pairs between such two directions and gradually align it into a strong image editor that well balances between the two tasks. SeedEdit can achieve more diverse and stable editing capability over prior image editing methods, enabling sequential revision over images generated by diffusion models.
Multi-view Image Prompted Multi-view Diffusion for Improved 3D Generation
Apr 26, 2024Using image as prompts for 3D generation demonstrate particularly strong performances compared to using text prompts alone, for images provide a more intuitive guidance for the 3D generation process. In this work, we delve into the potential of using multiple image prompts, instead of a single image prompt, for 3D generation. Specifically, we build on ImageDream, a novel image-prompt multi-view diffusion model, to support multi-view images as the input prompt. Our method, dubbed MultiImageDream, reveals that transitioning from a single-image prompt to multiple-image prompts enhances the performance of multi-view and 3D object generation according to various quantitative evaluation metrics and qualitative assessments. This advancement is achieved without the necessity of fine-tuning the pre-trained ImageDream multi-view diffusion model.