 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provable Expressiveness Hierarchy in Hybrid Linear-Full Attention
Feb 02, 2026Transformers serve as the foundation of most modern large language models. To mitigate the quadratic complexity of standard full attention, various efficient attention mechanisms, such as linear and hybrid attention, have been developed. A fundamental gap remains: their expressive power relative to full attention lacks a rigorous theoretical characterization. In this work, we theoretically characterize the performance differences among these attention mechanisms. Our theory applies to all linear attention variants that can be formulated as a recurrence, including Mamba, DeltaNet, etc. Specifically, we establish an expressiveness hierarchy: for the sequential function composition-a multi-step reasoning task that must occur within a model's forward pass, an ($L+1$)-layer full attention network is sufficient, whereas any hybrid network interleaving $L-1$ layers of full attention with a substantially larger number ($2^{3L^2}$) of linear attention layers cannot solve it. This result demonstrates a clear separation in expressive power between the two types of attention. Our work provides the first provable separation between hybrid attention and standard full attention, offering a theoretical perspective for understanding the fundamental capabilities and limitations of different attention mechanisms.
BAPS: A Fine-Grained Low-Precision Scheme for Softmax in Attention via Block-Aware Precision reScaling
Feb 02, 2026As the performance gains from accelerating quantized matrix multiplication plateau, the softmax operation becomes the critical bottleneck in Transformer inference. This bottleneck stems from two hardware limitations: (1) limited data bandwidth between matrix and vector compute cores, and (2) the significant area cost of high-precision (FP32/16) exponentiation units (EXP2). To address these issues, we introduce a novel low-precision workflow that employs a specific 8-bit floating-point format (HiF8) and block-aware precision rescaling for softmax. Crucially, our algorithmic innovations make low-precision softmax feasible without the significant model accuracy loss that hampers direct low-precision approaches. Specifically, our design (i) halves the required data movement bandwidth by enabling matrix multiplication outputs constrained to 8-bit, and (ii) substantially reduces the EXP2 unit area by computing exponentiations in low (8-bit) precision. Extensive evaluation on language models and multi-modal models confirms the validity of our method. By alleviating the vector computation bottleneck, our work paves the way for doubling end-to-end inference throughput without increasing chip area, and offers a concrete co-design path for future low-precision hardware and software.
Mogao: An Omni Foundation Model for Interleaved Multi-Modal Generation
May 08, 2025Recent progress in unified models for image understanding and generation has been impressive, yet most approaches remain limited to single-modal generation conditioned on multiple modalities. In this paper, we present Mogao, a unified framework that advances this paradigm by enabling interleaved multi-modal generation through a causal approach. Mogao integrates a set of key technical improvements in architecture design, including a deep-fusion design, dual vision encoders, interleaved rotary position embeddings, and multi-modal classifier-free guidance, which allow it to harness the strengths of both autoregressive models for text generation and diffusion models for high-quality image synthesis. These practical improvements also make Mogao particularly effective to process interleaved sequences of text and images arbitrarily. To further unlock the potential of unified models, we introduce an efficient training strategy on a large-scale, in-house dataset specifically curated for joint text and image generation. Extensive experiments show that Mogao not only achieves state-of-the-art performance in multi-modal understanding and text-to-image generation, but also excels in producing high-quality, coherent interleaved outputs. Its emergent capabilities in zero-shot image editing and compositional generation highlight Mogao as a practical omni-modal foundation model, paving the way for future development and scaling the unified multi-modal systems.
Seedream 3.0 Technical Report
Apr 16, 2025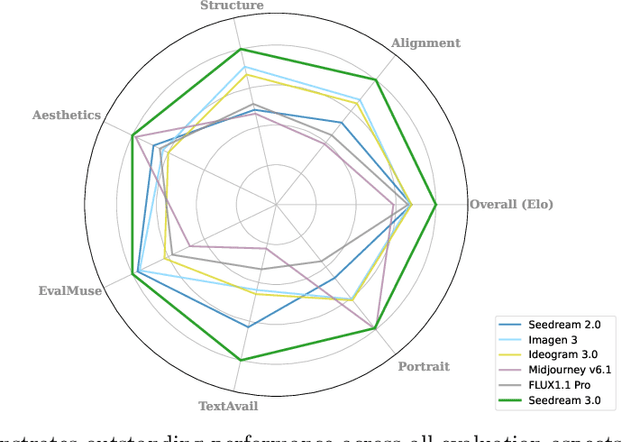


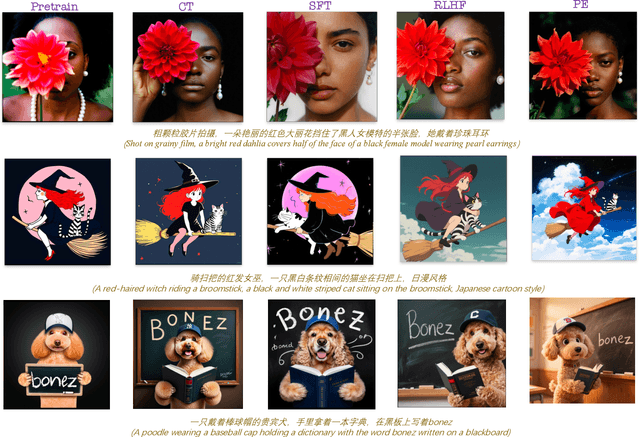
We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
KwaiYiiMath: Technical Report
Oct 19, 2023



Recent advancements in large language models (LLMs) have demonstrated remarkable abilities in handling a variety of natural language processing (NLP) downstream tasks, even on mathematical tasks requiring multi-step reasoning. In this report, we introduce the KwaiYiiMath which enhances the mathematical reasoning abilities of KwaiYiiBase1, by applying Supervised Fine-Tuning (SFT) and Reinforced Learning from Human Feedback (RLHF), including on both English and Chinese mathematical tasks. Meanwhile, we also constructed a small-scale Chinese primary school mathematics test set (named KMath), consisting of 188 examples to evaluate the correctness of the problem-solving process generated by the models. Empirical studies demonstrate that KwaiYiiMath can achieve state-of-the-art (SOTA) performance on GSM8k, CMath, and KMath compared with the similar size models, respectively.
USDC: Unified Static and Dynamic Compression for Visual Transformer
Oct 17, 2023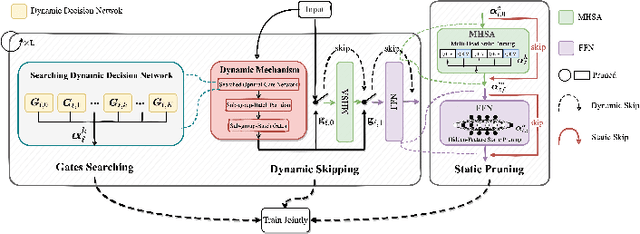
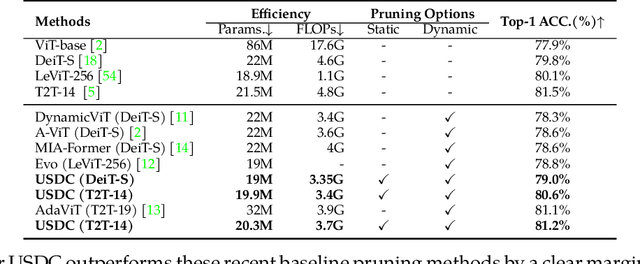
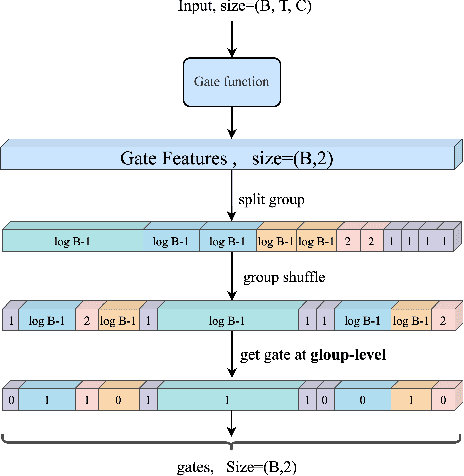
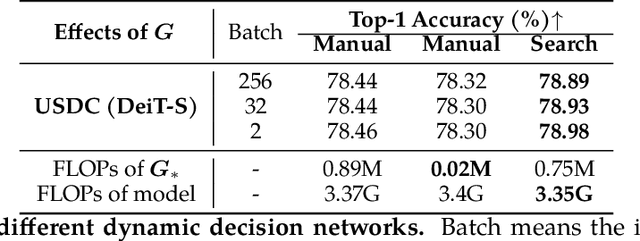
Visual Transformers have achieved great success in almost all vision tasks, such as classification, detection, and so on. However, the model complexity and the inference speed of the visual transformers hinder their deployments in industrial products. Various model compression techniques focus on directly compressing the visual transformers into a smaller one while maintaining the model performance, however, the performance drops dramatically when the compression ratio is large. Furthermore, several dynamic network techniques have also been applied to dynamically compress the visual transformers to obtain input-adaptive efficient sub-structures during the inference stage, which can achieve a better trade-off between the compression ratio and the model performance. The upper bound of memory of dynamic models is not reduced in the practical deployment since the whole original visual transformer model and the additional control gating modules should be loaded onto devices together for inference. To alleviate two disadvantages of two categories of methods, we propose to unify the static compression and dynamic compression techniques jointly to obtain an input-adaptive compressed model, which can further better balance the total compression ratios and the model performances. Moreover, in practical deployment, the batch sizes of the training and inference stage are usually different, which will cause the model inference performance to be worse than the model training performance, which is not touched by all previous dynamic network papers. We propose a sub-group gates augmentation technique to solve this performance drop problem. Extensive experiments demonstrate the superiority of our method on various baseline visual transformers such as DeiT, T2T-ViT, and so on.
ASP: Automatic Selection of Proxy dataset for efficient AutoML
Oct 17, 2023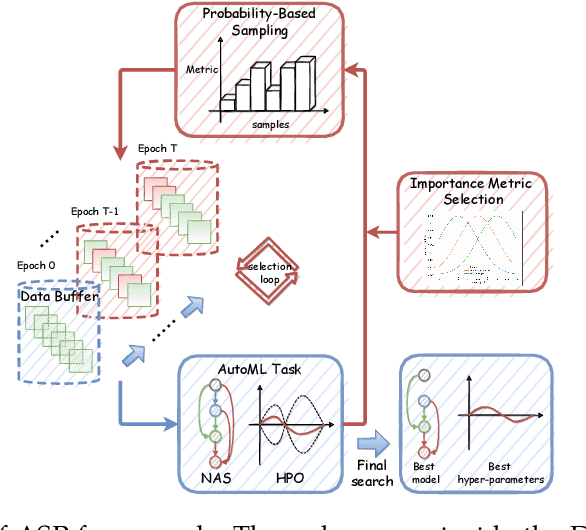
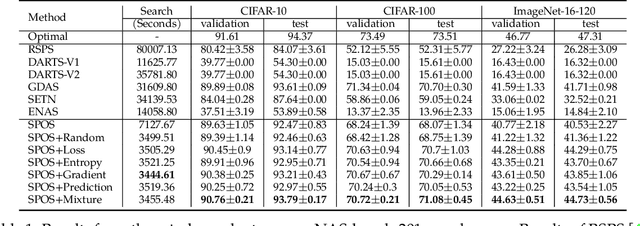
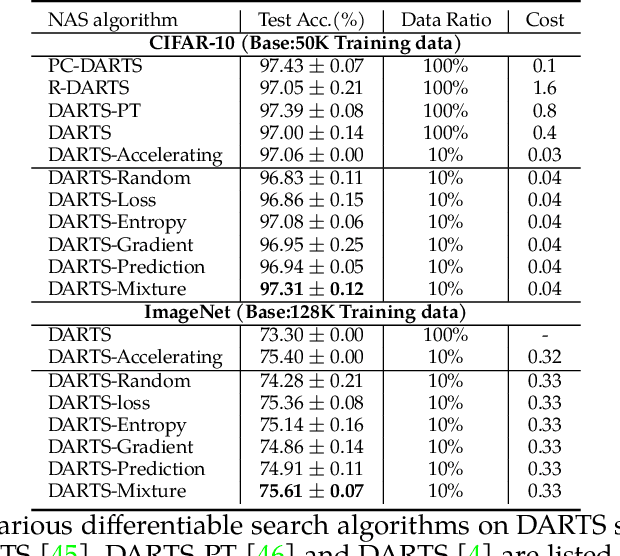
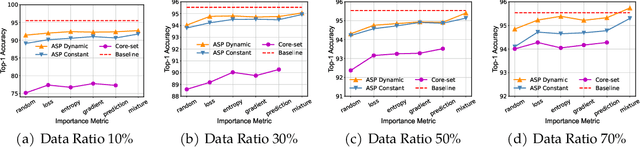
Deep neural networks have gained great success due to the increasing amounts of data, and diverse effective neural network designs. However, it also brings a heavy computing burden as the amount of training data is proportional to the training time. In addition, a well-behaved model requires repeated trials of different structure designs and hyper-parameters, which may take a large amount of time even with state-of-the-art (SOTA) hyper-parameter optimization (HPO) algorithms and neural architecture search (NAS) algorithms. In this paper, we propose an Automatic Selection of Proxy dataset framework (ASP) aimed to dynamically find the informative proxy subsets of training data at each epoch, reducing the training data size as well as saving the AutoML processing time. We verify the effectiveness and generalization of ASP on CIFAR10, CIFAR100, ImageNet16-120, and ImageNet-1k, across various public model benchmarks. The experiment results show that ASP can obtain better results than other data selection methods at all selection ratios. ASP can also enable much more efficient AutoML processing with a speedup of 2x-20x while obtaining better architectures and better hyper-parameters compared to utilizing the entire dataset.
Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
Sep 29, 2023
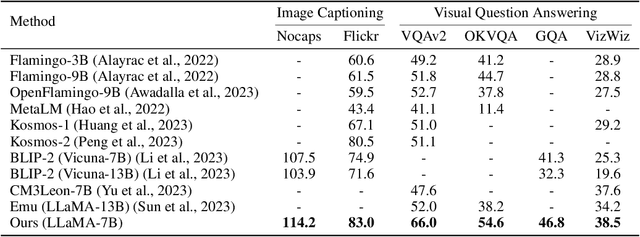

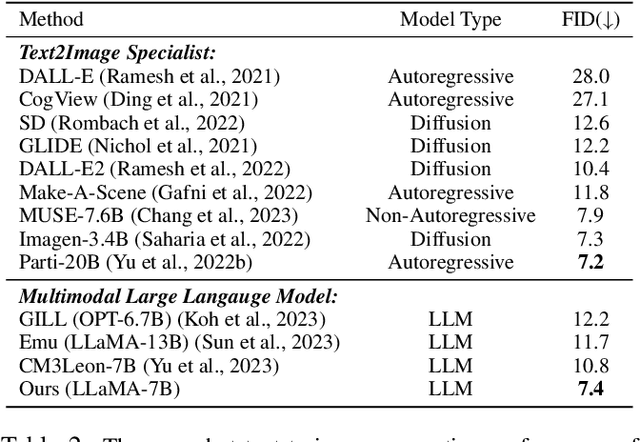
Recently, the remarkable advance of the Large Language Model (LLM) has inspired researchers to transfer its extraordinary reasoning capability to both vision and language data. However, the prevailing approaches primarily regard the visual input as a prompt and focus exclusively on optimizing the text generation process conditioned upon vision content by a frozen LLM. Such an inequitable treatment of vision and language heavily constrains the model's potential. In this paper, we break through this limitation by representing both vision and language in a unified form. Specifically, we introduce a well-designed visual tokenizer to translate the non-linguistic image into a sequence of discrete tokens like a foreign language that LLM can read. The resulting visual tokens encompass high-level semantics worthy of a word and also support dynamic sequence length varying from the image. Coped with this tokenizer, the presented foundation model called LaVIT can handle both image and text indiscriminately under the same generative learning paradigm. This unification empowers LaVIT to serve as an impressive generalist interface to understand and generate multi-modal content simultaneously. Extensive experiments further showcase that it outperforms the existing models by a large margin on massive vision-language tasks. Our code and models will be available at https://github.com/jy0205/LaVIT.
LPFS: Learnable Polarizing Feature Selection for Click-Through Rate Prediction
Jun 01, 2022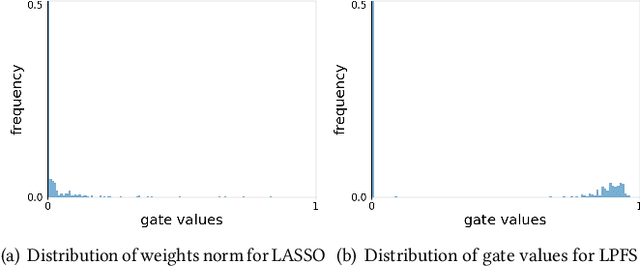
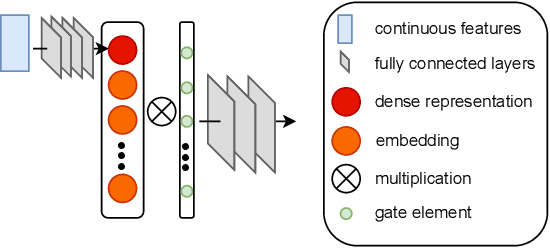

In industry, feature selection is a standard but necessary step to search for an optimal set of informative feature fields for efficient and effective training of deep Click-Through Rate (CTR) models. Most previous works measure the importance of feature fields by using their corresponding continuous weights from the model, then remove the feature fields with small weight values. However, removing many features that correspond to small but not exact zero weights will inevitably hurt model performance and not be friendly to hot-start model training. There is also no theoretical guarantee that the magnitude of weights can represent the importance, thus possibly leading to sub-optimal results if using these methods. To tackle this problem, we propose a novel Learnable Polarizing Feature Selection (LPFS) method using a smoothed-$\ell^0$ function in literature. Furthermore, we extend LPFS to LPFS++ by our newly designed smoothed-$\ell^0$-liked function to select a more informative subset of features. LPFS and LPFS++ can be used as gates inserted at the input of the deep network to control the active and inactive state of each feature. When training is finished, some gates are exact zero, while others are around one, which is particularly favored by the practical hot-start training in the industry, due to no damage to the model performance before and after removing the features corresponding to exact-zero gates. Experiments show that our methods outperform others by a clear margin, and have achieved great A/B test results in KuaiShou Technology.
Adversarial Contrastive Self-Supervised Learning
Feb 26, 2022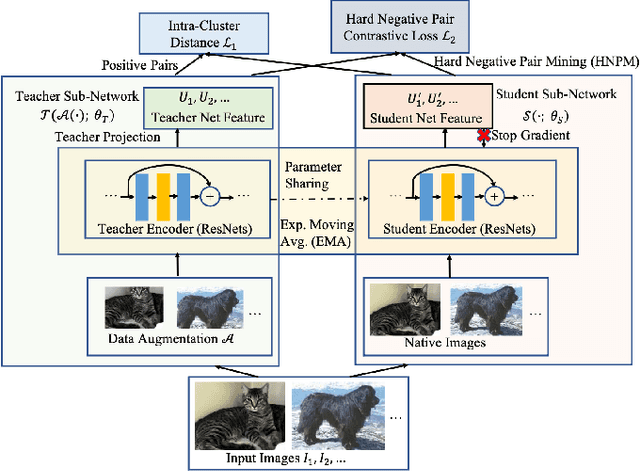
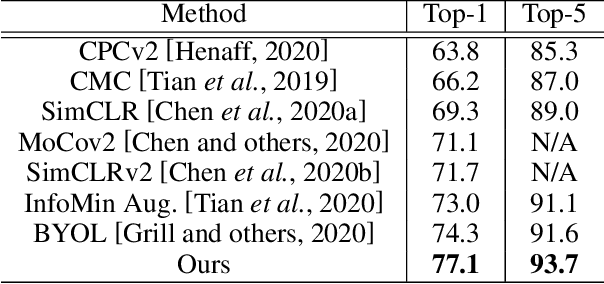
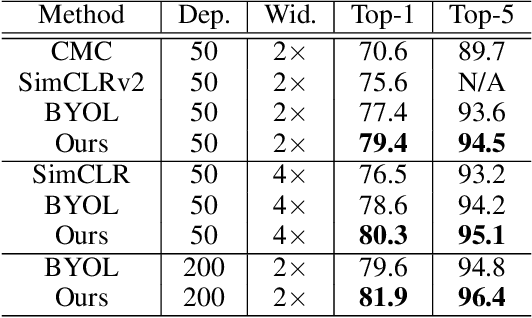
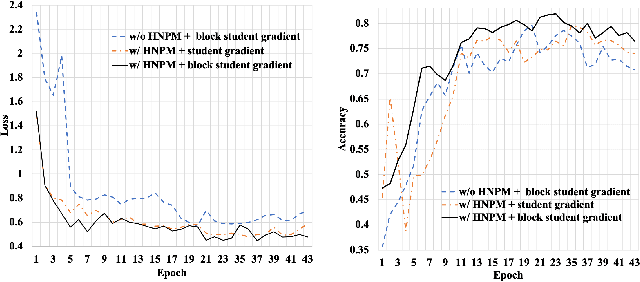
Recently, learning from vast unlabeled data, especially self-supervised learning, has been emerging and attracted widespread attention. Self-supervised learning followed by the supervised fine-tuning on a few labeled examples can significantly improve label efficiency and outperform standard supervised training using fully annotated data. In this work, we present a novel self-supervised deep learning paradigm based on online hard negative pair mining. Specifically, we design a student-teacher network to generate multi-view of the data for self-supervised learning and integrate hard negative pair mining into the training. Then we derive a new triplet-like loss considering both positive sample pairs and mined hard negative sample pairs. Extensive experiments demonstrate the effectiveness of the proposed method and its components on ILSVRC-2012.