 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk One More Time: Self-Agreement Improves Reasoning of Language Models in All Scenarios
Nov 14, 2023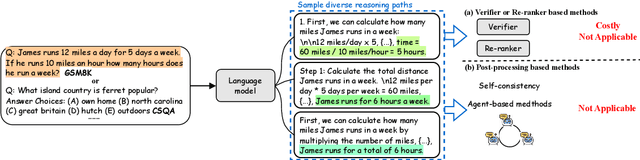



Although chain-of-thought (CoT) prompting combined with language models has achieved encouraging results on complex reasoning tasks, the naive greedy decoding used in CoT prompting usually causes the repetitiveness and local optimality. To address this shortcoming, ensemble-optimization tries to obtain multiple reasoning paths to get the final answer assembly. However, current ensemble-optimization methods either simply employ rule-based post-processing such as \textit{self-consistency}, or train an additional model based on several task-related human annotations to select the best one among multiple reasoning paths, yet fail to generalize to realistic settings where the type of input questions is unknown or the answer format of reasoning paths is unknown. To avoid their limitations, we propose \textbf{self-agreement}, a generalizable ensemble-optimization method applying in almost all scenarios where the type of input questions and the answer format of reasoning paths may be known or unknown. Self-agreement firstly samples from language model's decoder to generate a \textit{diverse} set of reasoning paths, and subsequently prompts the language model \textit{one more time} to determine the optimal answer by selecting the most \textit{agreed} answer among the sampled reasoning paths. Self-agreement simultaneously achieves remarkable performance on six public reasoning benchmarks and superior generalization capabilities.
KwaiYiiMath: Technical Report
Oct 19, 2023



Recent advancements in large language models (LLMs) have demonstrated remarkable abilities in handling a variety of natural language processing (NLP) downstream tasks, even on mathematical tasks requiring multi-step reasoning. In this report, we introduce the KwaiYiiMath which enhances the mathematical reasoning abilities of KwaiYiiBase1, by applying Supervised Fine-Tuning (SFT) and Reinforced Learning from Human Feedback (RLHF), including on both English and Chinese mathematical tasks. Meanwhile, we also constructed a small-scale Chinese primary school mathematics test set (named KMath), consisting of 188 examples to evaluate the correctness of the problem-solving process generated by the models. Empirical studies demonstrate that KwaiYiiMath can achieve state-of-the-art (SOTA) performance on GSM8k, CMath, and KMath compared with the similar size models, respectively.