 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDN-Hypo-Pipeline: An AI-Driven Workflow for Hypothesis Generation via Large Language Models and Scientific Explanations
Jun 07, 2026A scientific hypothesis is the first step in research and undergoes experimental validation, yet it also reflects a deep understanding of and reasoning about scientific phenomena. We introduce DN-Hypo-Pipeline, an AI-powered workflow based on large language models, designed to support structured scientific thinking and hypothesis generation by leveraging scientific explanations as prior knowledge. This pipeline assists researchers in deriving novel hypotheses from existing literature. Given the explanandum (i.e., the conclusion) of a research paper, it identifies underlying laws, theories, and principles, and reconstructs a new, yet-to-be-verified explanation for the observed phenomenon. We evaluated DN-Hypo-Pipeline in the field of data science modeling using three highly cited papers. Statistical inference, supported by both LLM-as-judge assessment and human expert evaluation, demonstrates that our pipeline is more effective than direct generation methods. Additionally, we validated the two highest-scoring generated hypotheses by developing corresponding novel algorithms, which outperformed the baseline models presented in the original papers. Beyond application in data science, DN-Hypo-Pipeline provides a theoretical framework that not only encompasses theory-guided data science modeling methods but also reveals a more fundamental structure of the modeling process. Moreover, this approach is essentially a generalization of theory-guided modeling, offering potential for extension to other domains and across a broader range of scientific disciplines.
Heuristic Classification of Thoughts Prompting (HCoT): Integrating Expert System Heuristics for Structured Reasoning into Large Language Models
Apr 14, 2026This paper addresses two limitations of large language models (LLMs) in solving complex problems: (1) their reasoning processes exhibit Bayesian-like stochastic generation, where each token is sampled from a context-dependent probability distribution, leading to inherently random decision trajectories rather than deterministic planning; (2) the reasoning and decision-making mechanisms are statically decoupled, meaning dynamically retrieved domain knowledge fails to dynamically adjust the underlying reasoning strategy. These dual deficiencies result in initial decisions lacking strategic anchoring and reasoning chains often failing to converge on correct solutions, as stochastic generation lacks mechanisms for trajectory correction or knowledge-guided optimization during sequential reasoning. To resolve these issues, we propose a problem-solving method integrated into the LLM's generation process to guide reasoning. This method, compatible with numerous LLMs and featuring reusable solutions, is grounded in a novel Heuristic-Classification-of-Thoughts prompting schema (HCoT). HCoT synergizes the LLM's reasoning ability with a structured problem space via a heuristic classification model that controls the reasoning process and provides reusable abstract solutions. Evaluated on two complex inductive reasoning tasks with ill-defined search spaces, HCoT outperforms existing approaches (e.g., Tree-of-Thoughts and Chain-of-Thoughts prompting) in performance. On the well-structured 24 Game task, HCoT demonstrates significantly higher token efficiency compared to the state-of-the-art Tree-of-Thoughts-Breadth-First-Search. In terms of both accuracy and token usage, HCoT achieves a Pareto frontier balance, offering a strong trade-off between performance and computational cost.
DARL: Encouraging Diverse Answers for General Reasoning without Verifiers
Jan 21, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has demonstrated promising gains in enhancing the reasoning capabilities of large language models. However, its dependence on domain-specific verifiers significantly restricts its applicability to open and general domains. Recent efforts such as RLPR have extended RLVR to general domains, enabling training on broader datasets and achieving improvements over RLVR. However, a notable limitation of these methods is their tendency to overfit to reference answers, which constrains the model's ability to generate diverse outputs. This limitation is particularly pronounced in open-ended tasks such as writing, where multiple plausible answers exist. To address this, we propose DARL, a simple yet effective reinforcement learning framework that encourages the generation of diverse answers within a controlled deviation range from the reference while preserving alignment with it. Our framework is fully compatible with existing general reinforcement learning methods and can be seamlessly integrated without additional verifiers. Extensive experiments on thirteen benchmarks demonstrate consistent improvements in reasoning performance. Notably, DARL surpasses RLPR, achieving average gains of 1.3 points on six reasoning benchmarks and 9.5 points on seven general benchmarks, highlighting its effectiveness in improving both reasoning accuracy and output diversity.
Attention as a Compass: Efficient Exploration for Process-Supervised RL in Reasoning Models
Sep 30, 2025Reinforcement Learning (RL) has shown remarkable success in enhancing the reasoning capabilities of Large Language Models (LLMs). Process-Supervised RL (PSRL) has emerged as a more effective paradigm compared to outcome-based RL. However, existing PSRL approaches suffer from limited exploration efficiency, both in terms of branching positions and sampling. In this paper, we introduce a novel PSRL framework (AttnRL), which enables efficient exploration for reasoning models. Motivated by preliminary observations that steps exhibiting high attention scores correlate with reasoning behaviors, we propose to branch from positions with high values. Furthermore, we develop an adaptive sampling strategy that accounts for problem difficulty and historical batch size, ensuring that the whole training batch maintains non-zero advantage values. To further improve sampling efficiency, we design a one-step off-policy training pipeline for PSRL. Extensive experiments on multiple challenging mathematical reasoning benchmarks demonstrate that our method consistently outperforms prior approaches in terms of performance and sampling and training efficiency.
An Attention-Based Denoising Framework for Personality Detection in Social Media Texts
Nov 16, 2023In social media networks, users produce a large amount of text content anytime, providing researchers with a valuable approach to digging for personality-related information. Personality detection based on user-generated texts is a universal method that can be used to build user portraits. The presence of noise in social media texts hinders personality detection. However, previous studies have not fully addressed this challenge. Inspired by the scanning reading technique, we propose an attention-based information extraction mechanism (AIEM) for long texts, which is applied to quickly locate valuable pieces of information, and focus more attention on the deep semantics of key pieces. Then, we provide a novel attention-based denoising framework (ADF) for personality detection tasks and achieve state-of-the-art performance on two commonly used datasets. Notably, we obtain an average accuracy improvement of 10.2% on the gold standard Twitter-Myers-Briggs Type Indicator (Twitter-MBTI) dataset. We made our code publicly available on GitHub. We shed light on how AIEM works to magnify personality-related signals.
Ask One More Time: Self-Agreement Improves Reasoning of Language Models in All Scenarios
Nov 14, 2023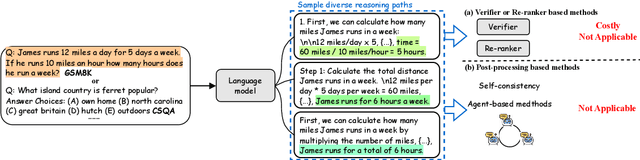



Although chain-of-thought (CoT) prompting combined with language models has achieved encouraging results on complex reasoning tasks, the naive greedy decoding used in CoT prompting usually causes the repetitiveness and local optimality. To address this shortcoming, ensemble-optimization tries to obtain multiple reasoning paths to get the final answer assembly. However, current ensemble-optimization methods either simply employ rule-based post-processing such as \textit{self-consistency}, or train an additional model based on several task-related human annotations to select the best one among multiple reasoning paths, yet fail to generalize to realistic settings where the type of input questions is unknown or the answer format of reasoning paths is unknown. To avoid their limitations, we propose \textbf{self-agreement}, a generalizable ensemble-optimization method applying in almost all scenarios where the type of input questions and the answer format of reasoning paths may be known or unknown. Self-agreement firstly samples from language model's decoder to generate a \textit{diverse} set of reasoning paths, and subsequently prompts the language model \textit{one more time} to determine the optimal answer by selecting the most \textit{agreed} answer among the sampled reasoning paths. Self-agreement simultaneously achieves remarkable performance on six public reasoning benchmarks and superior generalization capabilities.
Skywork: A More Open Bilingual Foundation Model
Oct 30, 2023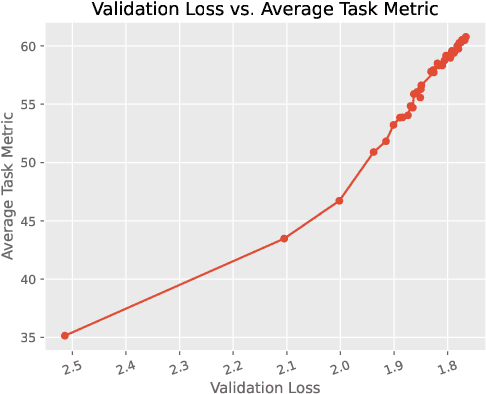
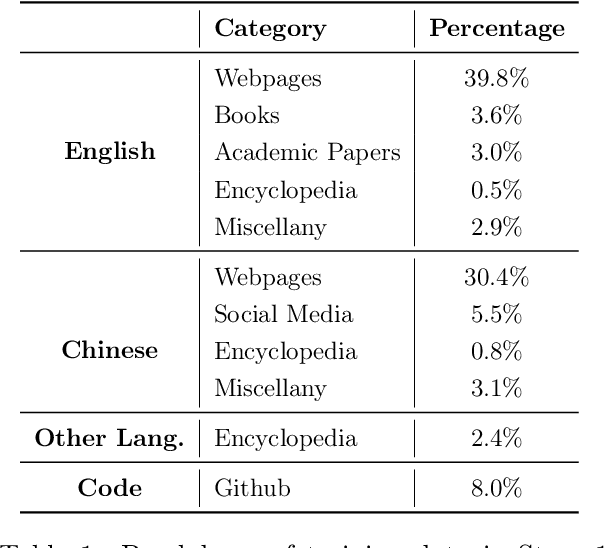
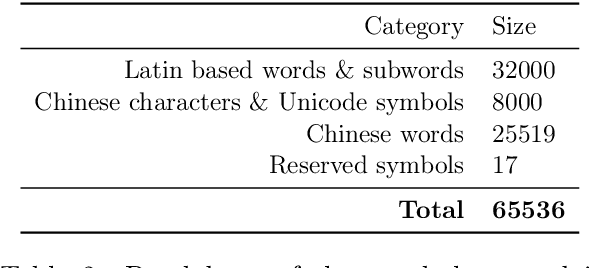
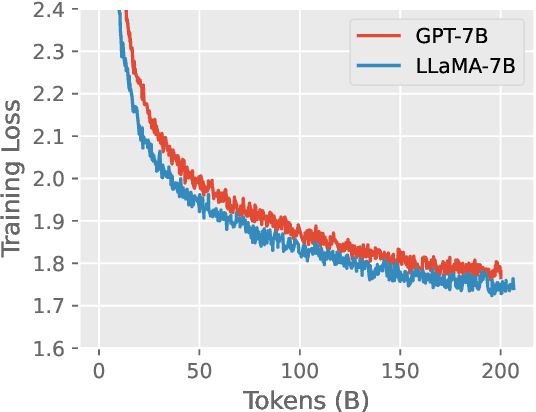
In this technical report, we present Skywork-13B, a family of large language models (LLMs) trained on a corpus of over 3.2 trillion tokens drawn from both English and Chinese texts. This bilingual foundation model is the most extensively trained and openly published LLMs of comparable size to date. We introduce a two-stage training methodology using a segmented corpus, targeting general purpose training and then domain-specific enhancement training, respectively. We show that our model not only excels on popular benchmarks, but also achieves \emph{state of the art} performance in Chinese language modeling on diverse domains. Furthermore, we propose a novel leakage detection method, demonstrating that test data contamination is a pressing issue warranting further investigation by the LLM community. To spur future research, we release Skywork-13B along with checkpoints obtained during intermediate stages of the training process. We are also releasing part of our SkyPile corpus, a collection of over 150 billion tokens of web text, which is the largest high quality open Chinese pre-training corpus to date. We hope Skywork-13B and our open corpus will serve as a valuable open-source resource to democratize access to high-quality LLMs.
SkyMath: Technical Report
Oct 26, 2023Large language models (LLMs) have shown great potential to solve varieties of natural language processing (NLP) tasks, including mathematical reasoning. In this work, we present SkyMath, a large language model for mathematics with 13 billion parameters. By applying self-compare fine-tuning, we have enhanced mathematical reasoning abilities of Skywork-13B-Base remarkably. On GSM8K, SkyMath outperforms all known open-source models of similar size and has established a new SOTA performance.
KwaiYiiMath: Technical Report
Oct 19, 2023



Recent advancements in large language models (LLMs) have demonstrated remarkable abilities in handling a variety of natural language processing (NLP) downstream tasks, even on mathematical tasks requiring multi-step reasoning. In this report, we introduce the KwaiYiiMath which enhances the mathematical reasoning abilities of KwaiYiiBase1, by applying Supervised Fine-Tuning (SFT) and Reinforced Learning from Human Feedback (RLHF), including on both English and Chinese mathematical tasks. Meanwhile, we also constructed a small-scale Chinese primary school mathematics test set (named KMath), consisting of 188 examples to evaluate the correctness of the problem-solving process generated by the models. Empirical studies demonstrate that KwaiYiiMath can achieve state-of-the-art (SOTA) performance on GSM8k, CMath, and KMath compared with the similar size models, respectively.
Layer-wise Representation Fusion for Compositional Generalization
Jul 20, 2023



Despite successes across a broad range of applications, sequence-to-sequence models' construct of solutions are argued to be less compositional than human-like generalization. There is mounting evidence that one of the reasons hindering compositional generalization is representations of the encoder and decoder uppermost layer are entangled. In other words, the syntactic and semantic representations of sequences are twisted inappropriately. However, most previous studies mainly concentrate on enhancing token-level semantic information to alleviate the representations entanglement problem, rather than composing and using the syntactic and semantic representations of sequences appropriately as humans do. In addition, we explain why the entanglement problem exists from the perspective of recent studies about training deeper Transformer, mainly owing to the ``shallow'' residual connections and its simple, one-step operations, which fails to fuse previous layers' information effectively. Starting from this finding and inspired by humans' strategies, we propose \textsc{FuSion} (\textbf{Fu}sing \textbf{S}yntactic and Semant\textbf{i}c Representati\textbf{on}s), an extension to sequence-to-sequence models to learn to fuse previous layers' information back into the encoding and decoding process appropriately through introducing a \emph{fuse-attention module} at each encoder and decoder layer. \textsc{FuSion} achieves competitive and even \textbf{state-of-the-art} results on two realistic benchmarks, which empirically demonstrates the effectiveness of our proposal.