 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAPT: Learning Adaptive Prefix-to-prefix Translation For Simultaneous Machine Translation
Paper and Code



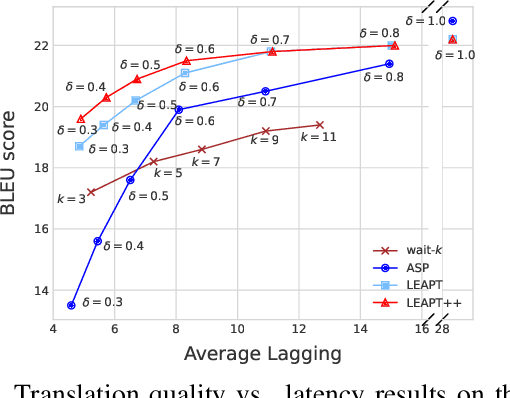
Simultaneous machine translation, which aims at a real-time translation, is useful in many live scenarios but very challenging due to the trade-off between accuracy and latency. To achieve the balance for both, the model needs to wait for appropriate streaming text (READ policy) and then generates its translation (WRITE policy). However, WRITE policies of previous work either are specific to the method itself due to the end-to-end training or suffer from the input mismatch between training and decoding for the non-end-to-end training. Therefore, it is essential to learn a generic and better WRITE policy for simultaneous machine translation. Inspired by strategies utilized by human interpreters and "wait" policies, we propose a novel adaptive prefix-to-prefix training policy called LEAPT, which allows our machine translation model to learn how to translate source sentence prefixes and make use of the future context. Experiments show that our proposed methods greatly outperform competitive baselines and achieve promising results.