 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Reasoning through Process Supervision with Monte Carlo Tree Search
Jan 02, 2025


Large language models (LLMs) have demonstrated their remarkable capacity across a variety of tasks. However, reasoning remains a challenge for LLMs. To improve LLMs' reasoning ability, process supervision has proven to be better than outcome supervision. In this work, we study using Monte Carlo Tree Search (MCTS) to generate process supervision data with LLMs themselves for training them. We sample reasoning steps with an LLM and assign each step a score that captures its "relative correctness," and the LLM is then trained by minimizing weighted log-likelihood of generating the reasoning steps. This generate-then-train process is repeated iteratively until convergence.Our experimental results demonstrate that the proposed methods considerably improve the performance of LLMs on two mathematical reasoning datasets. Furthermore, models trained on one dataset also exhibit improved performance on the other, showing the transferability of the enhanced reasoning ability.
Learn to Compose Syntactic and Semantic Representations Appropriately for Compositional Generalization
May 20, 2023Recent studies have shown that sequence-to-sequence (Seq2Seq) models are limited in solving the compositional generalization (CG) tasks, failing to systematically generalize to unseen compositions of seen components. There is mounting evidence that one of the reasons hindering CG is the representation of the encoder uppermost layer is entangled. In other words, the syntactic and semantic representations of sequences are twisted inappropriately. However, most previous studies mainly concentrate on enhancing semantic information at token-level, rather than composing the syntactic and semantic representations of sequences appropriately as humans do. In addition, we consider the representation entanglement problem they found is not comprehensive, and further hypothesize that source keys and values representations passing into different decoder layers are also entangled. Staring from this intuition and inspired by humans' strategies for CG, we propose COMPSITION (Compose Syntactic and Semantic Representations), an extension to Seq2Seq models to learn to compose representations of different encoder layers appropriately for generating different keys and values passing into different decoder layers through introducing a composed layer between the encoder and decoder. COMPSITION achieves competitive and even state-of-the-art results on two realistic benchmarks, which empirically demonstrates the effectiveness of our proposal.
LEAPT: Learning Adaptive Prefix-to-prefix Translation For Simultaneous Machine Translation
Mar 21, 2023


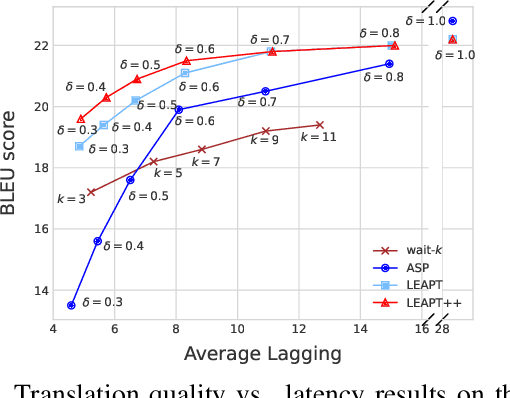
Simultaneous machine translation, which aims at a real-time translation, is useful in many live scenarios but very challenging due to the trade-off between accuracy and latency. To achieve the balance for both, the model needs to wait for appropriate streaming text (READ policy) and then generates its translation (WRITE policy). However, WRITE policies of previous work either are specific to the method itself due to the end-to-end training or suffer from the input mismatch between training and decoding for the non-end-to-end training. Therefore, it is essential to learn a generic and better WRITE policy for simultaneous machine translation. Inspired by strategies utilized by human interpreters and "wait" policies, we propose a novel adaptive prefix-to-prefix training policy called LEAPT, which allows our machine translation model to learn how to translate source sentence prefixes and make use of the future context. Experiments show that our proposed methods greatly outperform competitive baselines and achieve promising results.
Learning More Robust Features with Adversarial Training
Apr 20, 2018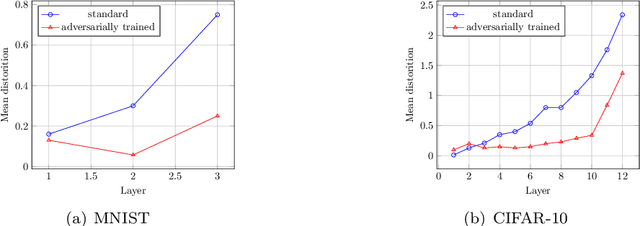
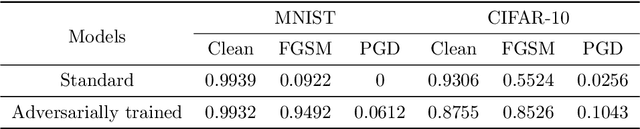
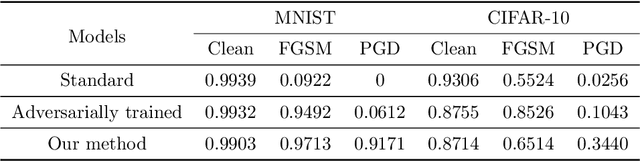
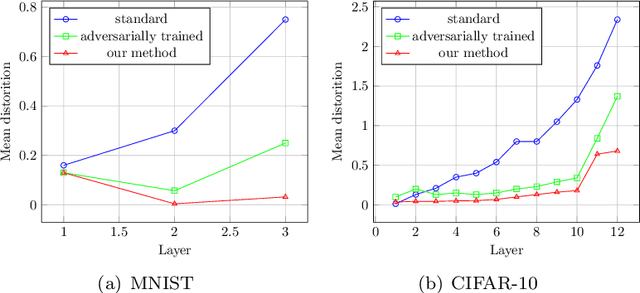
In recent years, it has been found that neural networks can be easily fooled by adversarial examples, which is a potential safety hazard in some safety-critical applications. Many researchers have proposed various method to make neural networks more robust to white-box adversarial attacks, but an effective method have not been found so far. In this short paper, we focus on the robustness of the features learned by neural networks. We show that the features learned by neural networks are not robust, and find that the robustness of the learned features is closely related to the resistance against adversarial examples of neural networks. We also find that adversarial training against fast gradients sign method (FGSM) does not make the leaned features very robust, even if it can make the trained networks very resistant to FGSM attack. Then we propose a method, which can be seen as an extension of adversarial training, to train neural networks to learn more robust features. We perform experiments on MNIST and CIFAR-10 to evaluate our method, and the experiment results show that this method greatly improves the robustness of the learned features and the resistance to adversarial attacks.