 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning More Robust Features with Adversarial Training
Paper and Code
Apr 20, 2018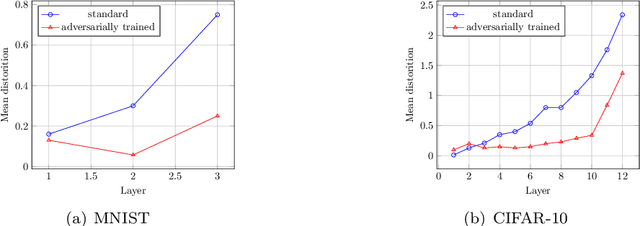
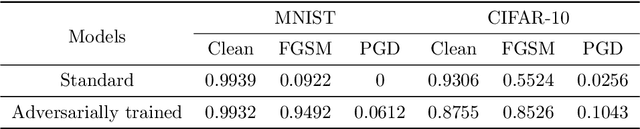
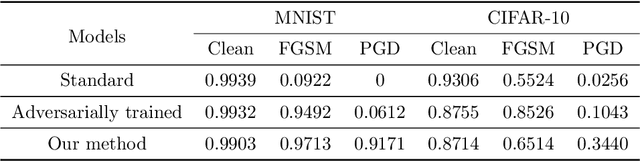
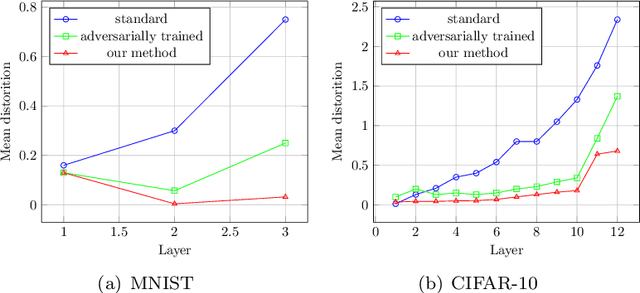
In recent years, it has been found that neural networks can be easily fooled by adversarial examples, which is a potential safety hazard in some safety-critical applications. Many researchers have proposed various method to make neural networks more robust to white-box adversarial attacks, but an effective method have not been found so far. In this short paper, we focus on the robustness of the features learned by neural networks. We show that the features learned by neural networks are not robust, and find that the robustness of the learned features is closely related to the resistance against adversarial examples of neural networks. We also find that adversarial training against fast gradients sign method (FGSM) does not make the leaned features very robust, even if it can make the trained networks very resistant to FGSM attack. Then we propose a method, which can be seen as an extension of adversarial training, to train neural networks to learn more robust features. We perform experiments on MNIST and CIFAR-10 to evaluate our method, and the experiment results show that this method greatly improves the robustness of the learned features and the resistance to adversarial attacks.