 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-Range Gaussians: Non-Grid-Aligned Generative 3D Gaussian Reconstruction
Apr 06, 2026We present Free-Range Gaussians, a multi-view reconstruction method that predicts non-pixel, non-voxel-aligned 3D Gaussians from as few as four images. This is done through flow matching over Gaussian parameters. Our generative formulation of reconstruction allows the model to be supervised with non-grid-aligned 3D data, and enables it to synthesize plausible content in unobserved regions. Thus, it improves on prior methods that produce highly redundant grid-aligned Gaussians, and suffer from holes or blurry conditional means in unobserved regions. To handle the number of Gaussians needed for high-quality results, we introduce a hierarchical patching scheme to group spatially related Gaussians into joint transformer tokens, halving the sequence length while preserving structure. We further propose a timestep-weighted rendering loss during training, and photometric gradient guidance and classifier-free guidance at inference to improve fidelity. Experiments on Objaverse and Google Scanned Objects show consistent improvements over pixel and voxel-aligned methods while using significantly fewer Gaussians, with large gains when input views leave parts of the object unobserved.
A Self-Rotating Tri-Rotor UAV for Field of View Expansion and Autonomous Flight
Mar 30, 2026Unmanned Aerial Vehicles (UAVs) perception relies on onboard sensors like cameras and LiDAR, which are limited by the narrow field of view (FoV). We present Self-Perception INertial Navigation Enabled Rotorcraft (SPINNER), a self-rotating tri-rotor UAV for the FoV expansion and autonomous flight. Without adding extra sensors or energy consumption, SPINNER significantly expands the FoV of onboard camera and LiDAR sensors through continuous spin motion, thereby enhancing environmental perception efficiency. SPINNER achieves full 3-dimensional position and roll--pitch attitude control using only three brushless motors, while adjusting the rotation speed via anti-torque plates design. To address the strong coupling, severe nonlinearity, and complex disturbances induced by spinning flight, we develop a disturbance compensation control framework that combines nonlinear model predictive control (MPC) with incremental nonlinear dynamic inversion. Experimental results demonstrate that SPINNER maintains robust flight under wind disturbances up to 4.8 \,m/s and achieves high-precision trajectory tracking at a maximum speed of 2.0\,m/s. Moreover, tests in parking garages and forests show that the rotational perception mechanism substantially improves FoV coverage and enhances perception capability of SPINNER.
A Long-Short Flow-Map Perspective for Drifting Models
Feb 24, 2026This paper provides a reinterpretation of the Drifting Model~\cite{deng2026generative} through a semigroup-consistent long-short flow-map factorization. We show that a global transport process can be decomposed into a long-horizon flow map followed by a short-time terminal flow map admitting a closed-form optimal velocity representation, and that taking the terminal interval length to zero recovers exactly the drifting field together with a conservative impulse term required for flow-map consistency. Based on this perspective, we propose a new likelihood learning formulation that aligns the long-short flow-map decomposition with density evolution under transport. We validate the framework through both theoretical analysis and empirical evaluations on benchmark tests, and further provide a theoretical interpretation of the feature-space optimization while highlighting several open problems for future study.
SurfPhase: 3D Interfacial Dynamics in Two-Phase Flows from Sparse Videos
Feb 11, 2026Interfacial dynamics in two-phase flows govern momentum, heat, and mass transfer, yet remain difficult to measure experimentally. Classical techniques face intrinsic limitations near moving interfaces, while existing neural rendering methods target single-phase flows with diffuse boundaries and cannot handle sharp, deformable liquid-vapor interfaces. We propose SurfPhase, a novel model for reconstructing 3D interfacial dynamics from sparse camera views. Our approach integrates dynamic Gaussian surfels with a signed distance function formulation for geometric consistency, and leverages a video diffusion model to synthesize novel-view videos to refine reconstruction from sparse observations. We evaluate on a new dataset of high-speed pool boiling videos, demonstrating high-quality view synthesis and velocity estimation from only two camera views. Project website: https://yuegao.me/SurfPhase.
Trajectory Consistency for One-Step Generation on Euler Mean Flows
Jan 31, 2026We propose \emph{Euler Mean Flows (EMF)}, a flow-based generative framework for one-step and few-step generation that enforces long-range trajectory consistency with minimal sampling cost. The key idea of EMF is to replace the trajectory consistency constraint, which is difficult to supervise and optimize over long time scales, with a principled linear surrogate that enables direct data supervision for long-horizon flow-map compositions. We derive this approximation from the semigroup formulation of flow-based models and show that, under mild regularity assumptions, it faithfully approximates the original consistency objective while being substantially easier to optimize. This formulation leads to a unified, JVP-free training framework that supports both $u$-prediction and $x_1$-prediction variants, avoiding explicit Jacobian computations and significantly reducing memory and computational overhead. Experiments on image synthesis, particle-based geometry generation, and functional generation demonstrate improved optimization stability and sample quality under fixed sampling budgets, together with approximately $50\%$ reductions in training time and memory consumption compared to existing one-step methods for image generation.
Functional Mean Flow in Hilbert Space
Nov 17, 2025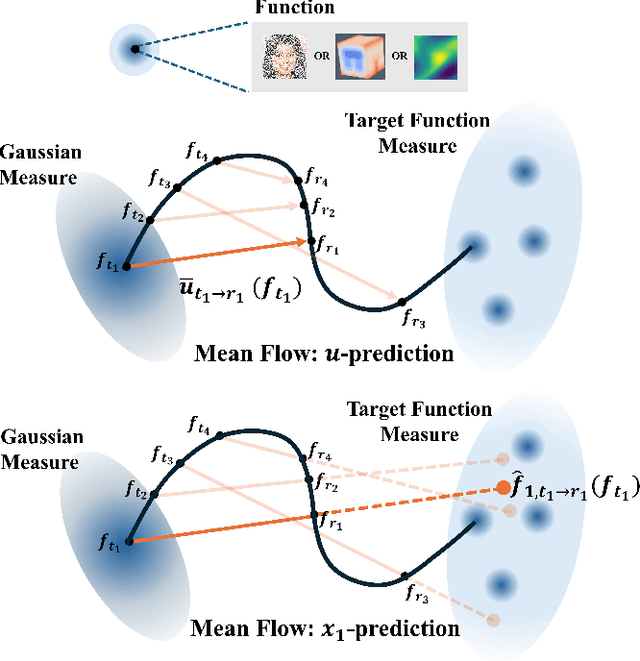
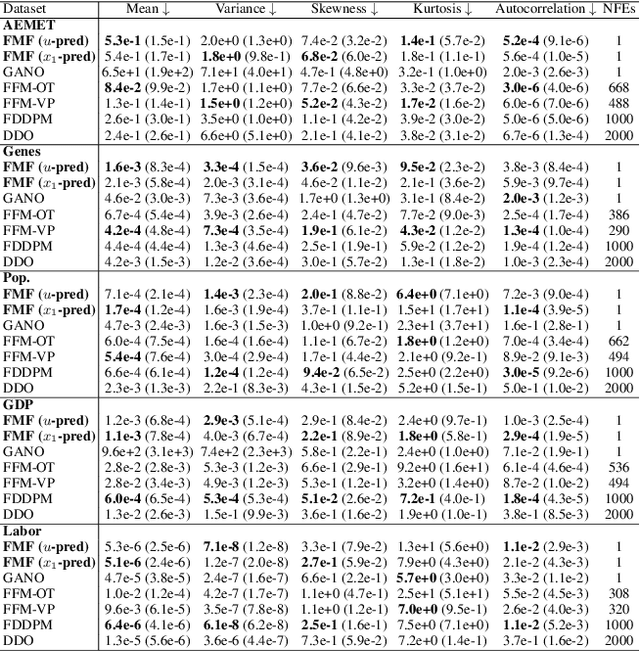

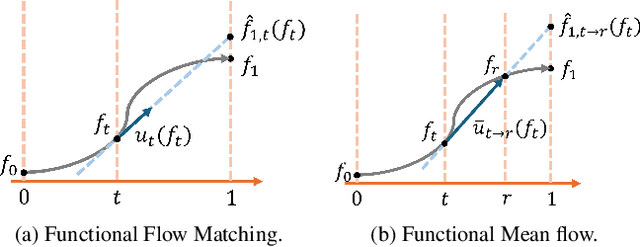
We present Functional Mean Flow (FMF) as a one-step generative model defined in infinite-dimensional Hilbert space. FMF extends the one-step Mean Flow framework to functional domains by providing a theoretical formulation for Functional Flow Matching and a practical implementation for efficient training and sampling. We also introduce an $x_1$-prediction variant that improves stability over the original $u$-prediction form. The resulting framework is a practical one-step Flow Matching method applicable to a wide range of functional data generation tasks such as time series, images, PDEs, and 3D geometry.
FluidNexus: 3D Fluid Reconstruction and Prediction from a Single Video
Mar 06, 2025We study reconstructing and predicting 3D fluid appearance and velocity from a single video. Current methods require multi-view videos for fluid reconstruction. We present FluidNexus, a novel framework that bridges video generation and physics simulation to tackle this task. Our key insight is to synthesize multiple novel-view videos as references for reconstruction. FluidNexus consists of two key components: (1) a novel-view video synthesizer that combines frame-wise view synthesis with video diffusion refinement for generating realistic videos, and (2) a physics-integrated particle representation coupling differentiable simulation and rendering to simultaneously facilitate 3D fluid reconstruction and prediction. To evaluate our approach, we collect two new real-world fluid datasets featuring textured backgrounds and object interactions. Our method enables dynamic novel view synthesis, future prediction, and interaction simulation from a single fluid video. Project website: https://yuegao.me/FluidNexus.
On the Exploration of LM-Based Soft Modular Robot Design
Nov 01, 2024



Recent large language models (LLMs) have demonstrated promising capabilities in modeling real-world knowledge and enhancing knowledge-based generation tasks. In this paper, we further explore the potential of using LLMs to aid in the design of soft modular robots, taking into account both user instructions and physical laws, to reduce the reliance on extensive trial-and-error experiments typically needed to achieve robot designs that meet specific structural or task requirements. Specifically, we formulate the robot design process as a sequence generation task and find that LLMs are able to capture key requirements expressed in natural language and reflect them in the construction sequences of robots. To simplify, rather than conducting real-world experiments to assess design quality, we utilize a simulation tool to provide feedback to the generative model, allowing for iterative improvements without requiring extensive human annotations. Furthermore, we introduce five evaluation metrics to assess the quality of robot designs from multiple angles including task completion and adherence to instructions, supporting an automatic evaluation process. Our model performs well in evaluations for designing soft modular robots with uni- and bi-directional locomotion and stair-descending capabilities, highlighting the potential of using natural language and LLMs for robot design. However, we also observe certain limitations that suggest areas for further improvement.
MoH: Multi-Head Attention as Mixture-of-Head Attention
Oct 15, 2024In this work, we upgrade the multi-head attention mechanism, the core of the Transformer model, to improve efficiency while maintaining or surpassing the previous accuracy level. We show that multi-head attention can be expressed in the summation form. Drawing on the insight that not all attention heads hold equal significance, we propose Mixture-of-Head attention (MoH), a new architecture that treats attention heads as experts in the Mixture-of-Experts (MoE) mechanism. MoH has two significant advantages: First, MoH enables each token to select the appropriate attention heads, enhancing inference efficiency without compromising accuracy or increasing the number of parameters. Second, MoH replaces the standard summation in multi-head attention with a weighted summation, introducing flexibility to the attention mechanism and unlocking extra performance potential. Extensive experiments on ViT, DiT, and LLMs demonstrate that MoH outperforms multi-head attention by using only 50%-90% of the attention heads. Moreover, we demonstrate that pre-trained multi-head attention models, such as LLaMA3-8B, can be further continue-tuned into our MoH models. Notably, MoH-LLaMA3-8B achieves an average accuracy of 64.0% across 14 benchmarks, outperforming LLaMA3-8B by 2.4% by utilizing only 75% of the attention heads. We believe the proposed MoH is a promising alternative to multi-head attention and provides a strong foundation for developing advanced and efficient attention-based models.
MoE++: Accelerating Mixture-of-Experts Methods with Zero-Computation Experts
Oct 09, 2024



In this work, we aim to simultaneously enhance the effectiveness and efficiency of Mixture-of-Experts (MoE) methods. To achieve this, we propose MoE++, a general and heterogeneous MoE framework that integrates both Feed-Forward Network~(FFN) and zero-computation experts. Specifically, we introduce three types of zero-computation experts: the zero expert, copy expert, and constant expert, which correspond to discard, skip, and replace operations, respectively. This design offers three key advantages: (i) Low Computing Overhead: Unlike the uniform mixing mechanism for all tokens within vanilla MoE, MoE++ allows each token to engage with a dynamic number of FFNs, be adjusted by constant vectors, or even skip the MoE layer entirely. (ii) High Performance: By enabling simple tokens to utilize fewer FFN experts, MoE++ allows more experts to focus on challenging tokens, thereby unlocking greater performance potential than vanilla MoE. (iii) Deployment Friendly: Given that zero-computation experts have negligible parameters, we can deploy all zero-computation experts on each GPU, eliminating the significant communication overhead and expert load imbalance associated with FFN experts distributed across different GPUs. Moreover, we leverage gating residuals, enabling each token to consider the pathway taken in the previous layer when selecting the appropriate experts. Extensive experimental results demonstrate that MoE++ achieves better performance while delivering 1.1-2.1x expert forward throughput compared to a vanilla MoE model of the same size, which lays a solid foundation for developing advanced and efficient MoE-related models.