 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgefVDB: A Deep-Learning Framework for Sparse, Large-Scale, and High-Performance Spatial Intelligence
Jul 01, 2024



We present fVDB, a novel GPU-optimized framework for deep learning on large-scale 3D data. fVDB provides a complete set of differentiable primitives to build deep learning architectures for common tasks in 3D learning such as convolution, pooling, attention, ray-tracing, meshing, etc. fVDB simultaneously provides a much larger feature set (primitives and operators) than established frameworks with no loss in efficiency: our operators match or exceed the performance of other frameworks with narrower scope. Furthermore, fVDB can process datasets with much larger footprint and spatial resolution than prior works, while providing a competitive memory footprint on small inputs. To achieve this combination of versatility and performance, fVDB relies on a single novel VDB index grid acceleration structure paired with several key innovations including GPU accelerated sparse grid construction, convolution using tensorcores, fast ray tracing kernels using a Hierarchical Digital Differential Analyzer algorithm (HDDA), and jagged tensors. Our framework is fully integrated with PyTorch enabling interoperability with existing pipelines, and we demonstrate its effectiveness on a number of representative tasks such as large-scale point-cloud segmentation, high resolution 3D generative modeling, unbounded scale Neural Radiance Fields, and large-scale point cloud reconstruction.
Neural Fluidic System Design and Control with Differentiable Simulation
May 22, 2024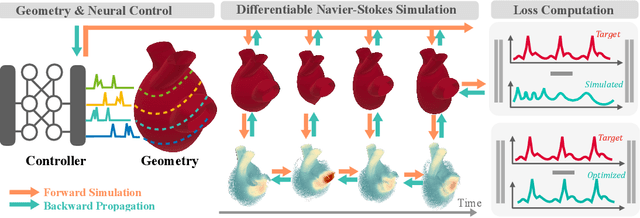
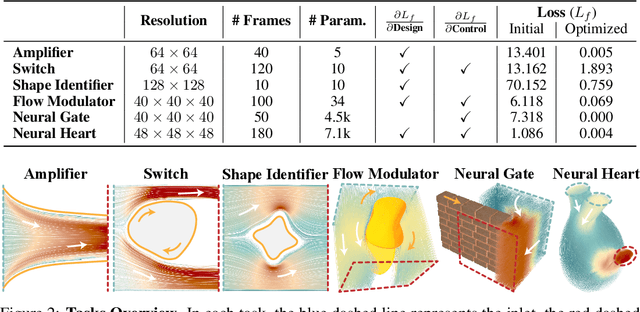
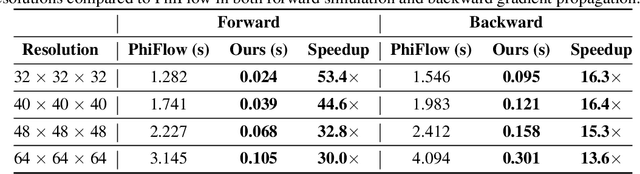
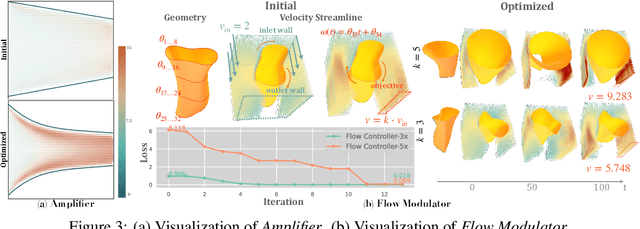
We present a novel framework to explore neural control and design of complex fluidic systems with dynamic solid boundaries. Our system features a fast differentiable Navier-Stokes solver with solid-fluid interface handling, a low-dimensional differentiable parametric geometry representation, a control-shape co-design algorithm, and gym-like simulation environments to facilitate various fluidic control design applications. Additionally, we present a benchmark of design, control, and learning tasks on high-fidelity, high-resolution dynamic fluid environments that pose challenges for existing differentiable fluid simulators. These tasks include designing the control of artificial hearts, identifying robotic end-effector shapes, and controlling a fluid gate. By seamlessly incorporating our differentiable fluid simulator into a learning framework, we demonstrate successful design, control, and learning results that surpass gradient-free solutions in these benchmark tasks.
Learning a Generalized Physical Face Model From Data
Feb 29, 2024



Physically-based simulation is a powerful approach for 3D facial animation as the resulting deformations are governed by physical constraints, allowing to easily resolve self-collisions, respond to external forces and perform realistic anatomy edits. Today's methods are data-driven, where the actuations for finite elements are inferred from captured skin geometry. Unfortunately, these approaches have not been widely adopted due to the complexity of initializing the material space and learning the deformation model for each character separately, which often requires a skilled artist followed by lengthy network training. In this work, we aim to make physics-based facial animation more accessible by proposing a generalized physical face model that we learn from a large 3D face dataset in a simulation-free manner. Once trained, our model can be quickly fit to any unseen identity and produce a ready-to-animate physical face model automatically. Fitting is as easy as providing a single 3D face scan, or even a single face image. After fitting, we offer intuitive animation controls, as well as the ability to retarget animations across characters. All the while, the resulting animations allow for physical effects like collision avoidance, gravity, paralysis, bone reshaping and more.
An Implicit Physical Face Model Driven by Expression and Style
Jan 27, 2024



3D facial animation is often produced by manipulating facial deformation models (or rigs), that are traditionally parameterized by expression controls. A key component that is usually overlooked is expression 'style', as in, how a particular expression is performed. Although it is common to define a semantic basis of expressions that characters can perform, most characters perform each expression in their own style. To date, style is usually entangled with the expression, and it is not possible to transfer the style of one character to another when considering facial animation. We present a new face model, based on a data-driven implicit neural physics model, that can be driven by both expression and style separately. At the core, we present a framework for learning implicit physics-based actuations for multiple subjects simultaneously, trained on a few arbitrary performance capture sequences from a small set of identities. Once trained, our method allows generalized physics-based facial animation for any of the trained identities, extending to unseen performances. Furthermore, it grants control over the animation style, enabling style transfer from one character to another or blending styles of different characters. Lastly, as a physics-based model, it is capable of synthesizing physical effects, such as collision handling, setting our method apart from conventional approaches.
Fast Sparse 3D Convolution Network with VDB
Nov 15, 2023We proposed a new Convolution Neural Network implementation optimized for sparse 3D data inference. This implementation uses NanoVDB as the data structure to store the sparse tensor. It leaves a relatively small memory footprint while maintaining high performance. We demonstrate that this architecture is around 20 times faster than the state-of-the-art dense CNN model on a high-resolution 3D object classification network.
Near-realtime Facial Animation by Deep 3D Simulation Super-Resolution
May 05, 2023



We present a neural network-based simulation super-resolution framework that can efficiently and realistically enhance a facial performance produced by a low-cost, realtime physics-based simulation to a level of detail that closely approximates that of a reference-quality off-line simulator with much higher resolution (26x element count in our examples) and accurate physical modeling. Our approach is rooted in our ability to construct - via simulation - a training set of paired frames, from the low- and high-resolution simulators respectively, that are in semantic correspondence with each other. We use face animation as an exemplar of such a simulation domain, where creating this semantic congruence is achieved by simply dialing in the same muscle actuation controls and skeletal pose in the two simulators. Our proposed neural network super-resolution framework generalizes from this training set to unseen expressions, compensates for modeling discrepancies between the two simulations due to limited resolution or cost-cutting approximations in the real-time variant, and does not require any semantic descriptors or parameters to be provided as input, other than the result of the real-time simulation. We evaluate the efficacy of our pipeline on a variety of expressive performances and provide comparisons and ablation experiments for plausible variations and alternatives to our proposed scheme.
Differentiable Implicit Soft-Body Physics
Feb 11, 2021We present a differentiable soft-body physics simulator that can be composed with neural networks as a differentiable layer. In contrast to other differentiable physics approaches that use explicit forward models to define state transitions, we focus on implicit state transitions defined via function minimization. Implicit state transitions appear in implicit numerical integration methods, which offer the benefits of large time steps and excellent numerical stability, but require a special treatment to achieve differentiability due to the absence of an explicit differentiable forward pass. In contrast to other implicit differentiation approaches that require explicit formulas for the force function and the force Jacobian matrix, we present an energy-based approach that allows us to compute these derivatives automatically and in a matrix-free fashion via reverse-mode automatic differentiation. This allows for more flexibility and productivity when defining physical models and is particularly important in the context of neural network training, which often relies on reverse-mode automatic differentiation (backpropagation). We demonstrate the effectiveness of our differentiable simulator in policy optimization for locomotion tasks and show that it achieves better sample efficiency than model-free reinforcement learning.
Real-time Non-line-of-Sight imaging of dynamic scenes
Oct 24, 2020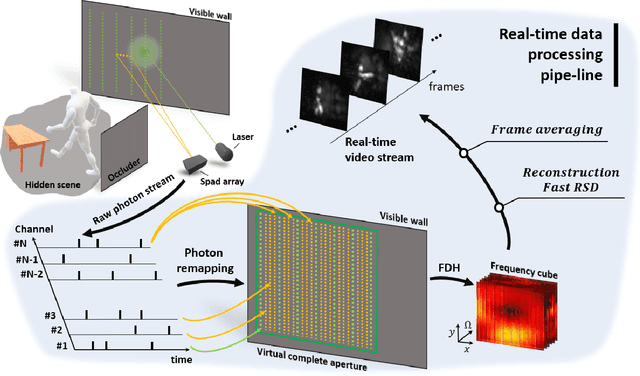
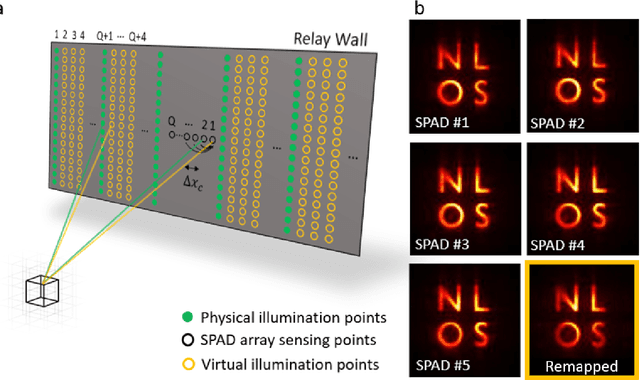
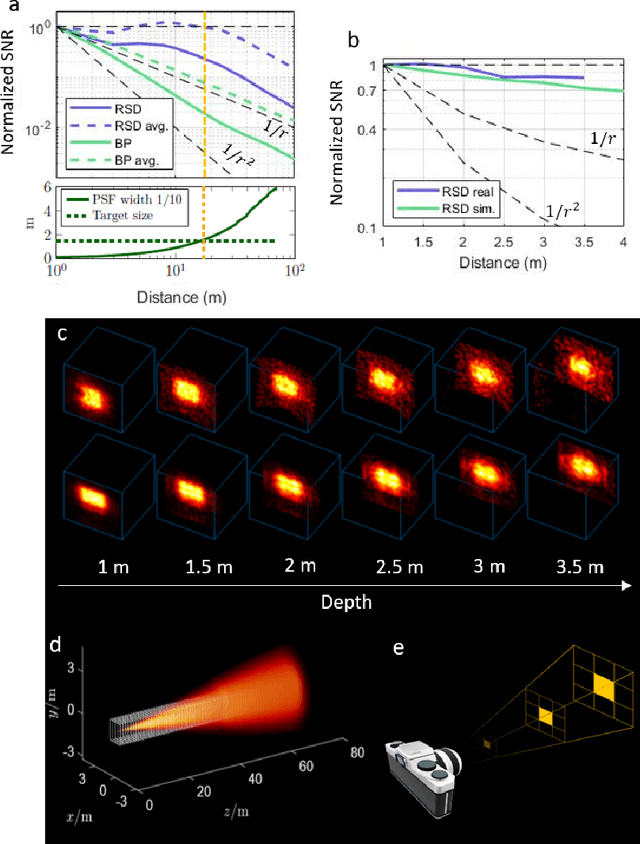

Non-Line-of-Sight (NLOS) imaging aims at recovering the 3D geometry of objects that are hidden from the direct line of sight. In the past, this method has suffered from the weak available multibounce signal limiting scene size, capture speed, and reconstruction quality. While algorithms capable of reconstructing scenes at several frames per second have been demonstrated, real-time NLOS video has only been demonstrated for retro-reflective objects where the NLOS signal strength is enhanced by 4 orders of magnitude or more. Furthermore, it has also been noted that the signal-to-noise ratio of reconstructions in NLOS methods drops quickly with distance and past reconstructions, therefore, have been limited to small scenes with depths of few meters. Actual models of noise and resolution in the scene have been simplistic, ignoring many of the complexities of the problem. We show that SPAD (Single-Photon Avalanche Diode) array detectors with a total of just 28 pixels combined with a specifically extended Phasor Field reconstruction algorithm can reconstruct live real-time videos of non-retro-reflective NLOS scenes. We provide an analysis of the Signal-to-Noise-Ratio (SNR) of our reconstructions and show that for our method it is possible to reconstruct the scene such that SNR, motion blur, angular resolution, and depth resolution are all independent of scene size suggesting that reconstruction of very large scenes may be possible. In the future, the light efficiency for NLOS imaging systems can be improved further by adding more pixels to the sensor array.