 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelightAnyone: A Generalized Relightable 3D Gaussian Head Model
Jan 06, 20263D Gaussian Splatting (3DGS) has become a standard approach to reconstruct and render photorealistic 3D head avatars. A major challenge is to relight the avatars to match any scene illumination. For high quality relighting, existing methods require subjects to be captured under complex time-multiplexed illumination, such as one-light-at-a-time (OLAT). We propose a new generalized relightable 3D Gaussian head model that can relight any subject observed in a single- or multi-view images without requiring OLAT data for that subject. Our core idea is to learn a mapping from flat-lit 3DGS avatars to corresponding relightable Gaussian parameters for that avatar. Our model consists of two stages: a first stage that models flat-lit 3DGS avatars without OLAT lighting, and a second stage that learns the mapping to physically-based reflectance parameters for high-quality relighting. This two-stage design allows us to train the first stage across diverse existing multi-view datasets without OLAT lighting ensuring cross-subject generalization, where we learn a dataset-specific lighting code for self-supervised lighting alignment. Subsequently, the second stage can be trained on a significantly smaller dataset of subjects captured under OLAT illumination. Together, this allows our method to generalize well and relight any subject from the first stage as if we had captured them under OLAT lighting. Furthermore, we can fit our model to unseen subjects from as little as a single image, allowing several applications in novel view synthesis and relighting for digital avatars.
Joint Learning of Depth and Appearance for Portrait Image Animation
Jan 15, 20252D portrait animation has experienced significant advancements in recent years. Much research has utilized the prior knowledge embedded in large generative diffusion models to enhance high-quality image manipulation. However, most methods only focus on generating RGB images as output, and the co-generation of consistent visual plus 3D output remains largely under-explored. In our work, we propose to jointly learn the visual appearance and depth simultaneously in a diffusion-based portrait image generator. Our method embraces the end-to-end diffusion paradigm and introduces a new architecture suitable for learning this conditional joint distribution, consisting of a reference network and a channel-expanded diffusion backbone. Once trained, our framework can be efficiently adapted to various downstream applications, such as facial depth-to-image and image-to-depth generation, portrait relighting, and audio-driven talking head animation with consistent 3D output.
Monocular Facial Appearance Capture in the Wild
Dec 17, 2024



We present a new method for reconstructing the appearance properties of human faces from a lightweight capture procedure in an unconstrained environment. Our method recovers the surface geometry, diffuse albedo, specular intensity and specular roughness from a monocular video containing a simple head rotation in-the-wild. Notably, we make no simplifying assumptions on the environment lighting, and we explicitly take visibility and occlusions into account. As a result, our method can produce facial appearance maps that approach the fidelity of studio-based multi-view captures, but with a far easier and cheaper procedure.
Multimodal Conditional 3D Face Geometry Generation
Jul 01, 2024



We present a new method for multimodal conditional 3D face geometry generation that allows user-friendly control over the output identity and expression via a number of different conditioning signals. Within a single model, we demonstrate 3D faces generated from artistic sketches, 2D face landmarks, Canny edges, FLAME face model parameters, portrait photos, or text prompts. Our approach is based on a diffusion process that generates 3D geometry in a 2D parameterized UV domain. Geometry generation passes each conditioning signal through a set of cross-attention layers (IP-Adapter), one set for each user-defined conditioning signal. The result is an easy-to-use 3D face generation tool that produces high resolution geometry with fine-grain user control.
Infinite 3D Landmarks: Improving Continuous 2D Facial Landmark Detection
May 30, 2024In this paper, we examine 3 important issues in the practical use of state-of-the-art facial landmark detectors and show how a combination of specific architectural modifications can directly improve their accuracy and temporal stability. First, many facial landmark detectors require face normalization as a preprocessing step, which is accomplished by a separately-trained neural network that crops and resizes the face in the input image. There is no guarantee that this pre-trained network performs the optimal face normalization for landmark detection. We instead analyze the use of a spatial transformer network that is trained alongside the landmark detector in an unsupervised manner, and jointly learn optimal face normalization and landmark detection. Second, we show that modifying the output head of the landmark predictor to infer landmarks in a canonical 3D space can further improve accuracy. To convert the predicted 3D landmarks into screen-space, we additionally predict the camera intrinsics and head pose from the input image. As a side benefit, this allows to predict the 3D face shape from a given image only using 2D landmarks as supervision, which is useful in determining landmark visibility among other things. Finally, when training a landmark detector on multiple datasets at the same time, annotation inconsistencies across datasets forces the network to produce a suboptimal average. We propose to add a semantic correction network to address this issue. This additional lightweight neural network is trained alongside the landmark detector, without requiring any additional supervision. While the insights of this paper can be applied to most common landmark detectors, we specifically target a recently-proposed continuous 2D landmark detector to demonstrate how each of our additions leads to meaningful improvements over the state-of-the-art on standard benchmarks.
Learning a Generalized Physical Face Model From Data
Feb 29, 2024



Physically-based simulation is a powerful approach for 3D facial animation as the resulting deformations are governed by physical constraints, allowing to easily resolve self-collisions, respond to external forces and perform realistic anatomy edits. Today's methods are data-driven, where the actuations for finite elements are inferred from captured skin geometry. Unfortunately, these approaches have not been widely adopted due to the complexity of initializing the material space and learning the deformation model for each character separately, which often requires a skilled artist followed by lengthy network training. In this work, we aim to make physics-based facial animation more accessible by proposing a generalized physical face model that we learn from a large 3D face dataset in a simulation-free manner. Once trained, our model can be quickly fit to any unseen identity and produce a ready-to-animate physical face model automatically. Fitting is as easy as providing a single 3D face scan, or even a single face image. After fitting, we offer intuitive animation controls, as well as the ability to retarget animations across characters. All the while, the resulting animations allow for physical effects like collision avoidance, gravity, paralysis, bone reshaping and more.
An Implicit Physical Face Model Driven by Expression and Style
Jan 27, 2024



3D facial animation is often produced by manipulating facial deformation models (or rigs), that are traditionally parameterized by expression controls. A key component that is usually overlooked is expression 'style', as in, how a particular expression is performed. Although it is common to define a semantic basis of expressions that characters can perform, most characters perform each expression in their own style. To date, style is usually entangled with the expression, and it is not possible to transfer the style of one character to another when considering facial animation. We present a new face model, based on a data-driven implicit neural physics model, that can be driven by both expression and style separately. At the core, we present a framework for learning implicit physics-based actuations for multiple subjects simultaneously, trained on a few arbitrary performance capture sequences from a small set of identities. Once trained, our method allows generalized physics-based facial animation for any of the trained identities, extending to unseen performances. Furthermore, it grants control over the animation style, enabling style transfer from one character to another or blending styles of different characters. Lastly, as a physics-based model, it is capable of synthesizing physical effects, such as collision handling, setting our method apart from conventional approaches.
Implicit Neural Representation for Physics-driven Actuated Soft Bodies
Jan 26, 2024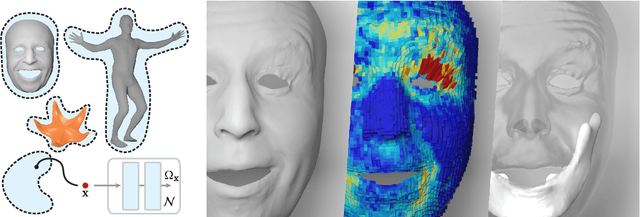

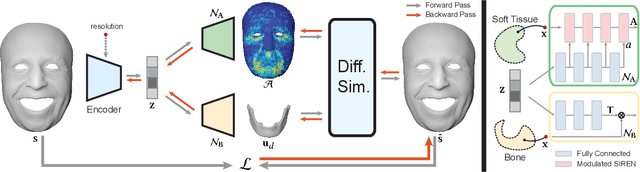
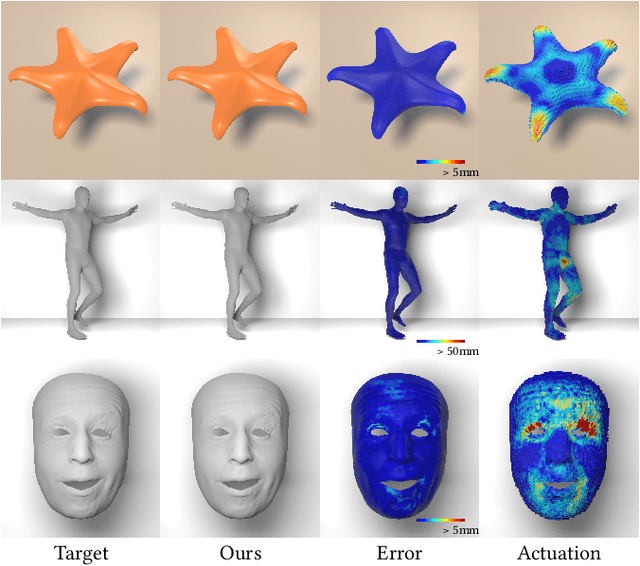
Active soft bodies can affect their shape through an internal actuation mechanism that induces a deformation. Similar to recent work, this paper utilizes a differentiable, quasi-static, and physics-based simulation layer to optimize for actuation signals parameterized by neural networks. Our key contribution is a general and implicit formulation to control active soft bodies by defining a function that enables a continuous mapping from a spatial point in the material space to the actuation value. This property allows us to capture the signal's dominant frequencies, making the method discretization agnostic and widely applicable. We extend our implicit model to mandible kinematics for the particular case of facial animation and show that we can reliably reproduce facial expressions captured with high-quality capture systems. We apply the method to volumetric soft bodies, human poses, and facial expressions, demonstrating artist-friendly properties, such as simple control over the latent space and resolution invariance at test time.
Anatomically Constrained Implicit Face Models
Dec 12, 2023Coordinate based implicit neural representations have gained rapid popularity in recent years as they have been successfully used in image, geometry and scene modeling tasks. In this work, we present a novel use case for such implicit representations in the context of learning anatomically constrained face models. Actor specific anatomically constrained face models are the state of the art in both facial performance capture and performance retargeting. Despite their practical success, these anatomical models are slow to evaluate and often require extensive data capture to be built. We propose the anatomical implicit face model; an ensemble of implicit neural networks that jointly learn to model the facial anatomy and the skin surface with high-fidelity, and can readily be used as a drop in replacement to conventional blendshape models. Given an arbitrary set of skin surface meshes of an actor and only a neutral shape with estimated skull and jaw bones, our method can recover a dense anatomical substructure which constrains every point on the facial surface. We demonstrate the usefulness of our approach in several tasks ranging from shape fitting, shape editing, and performance retargeting.
Artist-Friendly Relightable and Animatable Neural Heads
Dec 06, 2023



An increasingly common approach for creating photo-realistic digital avatars is through the use of volumetric neural fields. The original neural radiance field (NeRF) allowed for impressive novel view synthesis of static heads when trained on a set of multi-view images, and follow up methods showed that these neural representations can be extended to dynamic avatars. Recently, new variants also surpassed the usual drawback of baked-in illumination in neural representations, showing that static neural avatars can be relit in any environment. In this work we simultaneously tackle both the motion and illumination problem, proposing a new method for relightable and animatable neural heads. Our method builds on a proven dynamic avatar approach based on a mixture of volumetric primitives, combined with a recently-proposed lightweight hardware setup for relightable neural fields, and includes a novel architecture that allows relighting dynamic neural avatars performing unseen expressions in any environment, even with nearfield illumination and viewpoints.