 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastGHA: Generalized Few-Shot 3D Gaussian Head Avatars with Real-Time Animation
Jan 20, 2026Despite recent progress in 3D Gaussian-based head avatar modeling, efficiently generating high fidelity avatars remains a challenge. Current methods typically rely on extensive multi-view capture setups or monocular videos with per-identity optimization during inference, limiting their scalability and ease of use on unseen subjects. To overcome these efficiency drawbacks, we propose \OURS, a feed-forward method to generate high-quality Gaussian head avatars from only a few input images while supporting real-time animation. Our approach directly learns a per-pixel Gaussian representation from the input images, and aggregates multi-view information using a transformer-based encoder that fuses image features from both DINOv3 and Stable Diffusion VAE. For real-time animation, we extend the explicit Gaussian representations with per-Gaussian features and introduce a lightweight MLP-based dynamic network to predict 3D Gaussian deformations from expression codes. Furthermore, to enhance geometric smoothness of the 3D head, we employ point maps from a pre-trained large reconstruction model as geometry supervision. Experiments show that our approach significantly outperforms existing methods in both rendering quality and inference efficiency, while supporting real-time dynamic avatar animation.
Joint Learning of Depth and Appearance for Portrait Image Animation
Jan 15, 20252D portrait animation has experienced significant advancements in recent years. Much research has utilized the prior knowledge embedded in large generative diffusion models to enhance high-quality image manipulation. However, most methods only focus on generating RGB images as output, and the co-generation of consistent visual plus 3D output remains largely under-explored. In our work, we propose to jointly learn the visual appearance and depth simultaneously in a diffusion-based portrait image generator. Our method embraces the end-to-end diffusion paradigm and introduces a new architecture suitable for learning this conditional joint distribution, consisting of a reference network and a channel-expanded diffusion backbone. Once trained, our framework can be efficiently adapted to various downstream applications, such as facial depth-to-image and image-to-depth generation, portrait relighting, and audio-driven talking head animation with consistent 3D output.
Learning a Generalized Physical Face Model From Data
Feb 29, 2024



Physically-based simulation is a powerful approach for 3D facial animation as the resulting deformations are governed by physical constraints, allowing to easily resolve self-collisions, respond to external forces and perform realistic anatomy edits. Today's methods are data-driven, where the actuations for finite elements are inferred from captured skin geometry. Unfortunately, these approaches have not been widely adopted due to the complexity of initializing the material space and learning the deformation model for each character separately, which often requires a skilled artist followed by lengthy network training. In this work, we aim to make physics-based facial animation more accessible by proposing a generalized physical face model that we learn from a large 3D face dataset in a simulation-free manner. Once trained, our model can be quickly fit to any unseen identity and produce a ready-to-animate physical face model automatically. Fitting is as easy as providing a single 3D face scan, or even a single face image. After fitting, we offer intuitive animation controls, as well as the ability to retarget animations across characters. All the while, the resulting animations allow for physical effects like collision avoidance, gravity, paralysis, bone reshaping and more.
An Implicit Physical Face Model Driven by Expression and Style
Jan 27, 2024



3D facial animation is often produced by manipulating facial deformation models (or rigs), that are traditionally parameterized by expression controls. A key component that is usually overlooked is expression 'style', as in, how a particular expression is performed. Although it is common to define a semantic basis of expressions that characters can perform, most characters perform each expression in their own style. To date, style is usually entangled with the expression, and it is not possible to transfer the style of one character to another when considering facial animation. We present a new face model, based on a data-driven implicit neural physics model, that can be driven by both expression and style separately. At the core, we present a framework for learning implicit physics-based actuations for multiple subjects simultaneously, trained on a few arbitrary performance capture sequences from a small set of identities. Once trained, our method allows generalized physics-based facial animation for any of the trained identities, extending to unseen performances. Furthermore, it grants control over the animation style, enabling style transfer from one character to another or blending styles of different characters. Lastly, as a physics-based model, it is capable of synthesizing physical effects, such as collision handling, setting our method apart from conventional approaches.
Implicit Neural Representation for Physics-driven Actuated Soft Bodies
Jan 26, 2024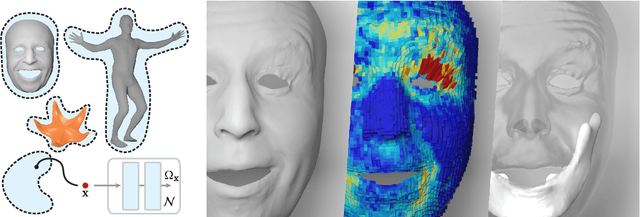

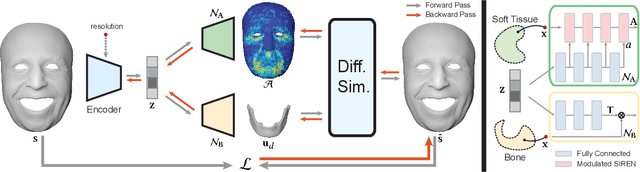
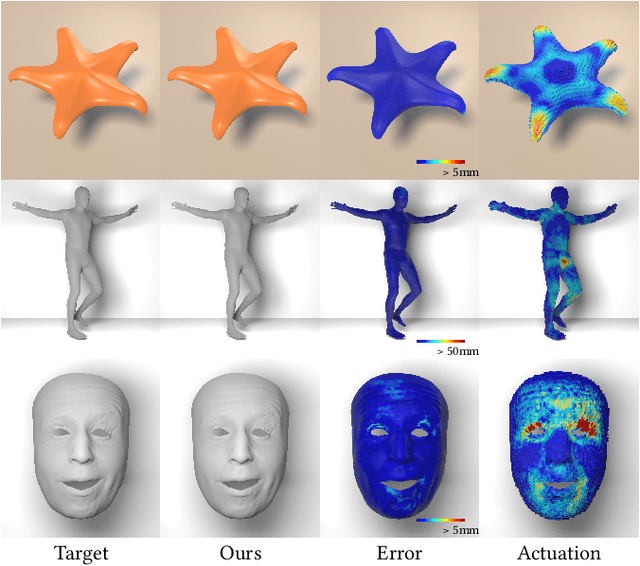
Active soft bodies can affect their shape through an internal actuation mechanism that induces a deformation. Similar to recent work, this paper utilizes a differentiable, quasi-static, and physics-based simulation layer to optimize for actuation signals parameterized by neural networks. Our key contribution is a general and implicit formulation to control active soft bodies by defining a function that enables a continuous mapping from a spatial point in the material space to the actuation value. This property allows us to capture the signal's dominant frequencies, making the method discretization agnostic and widely applicable. We extend our implicit model to mandible kinematics for the particular case of facial animation and show that we can reliably reproduce facial expressions captured with high-quality capture systems. We apply the method to volumetric soft bodies, human poses, and facial expressions, demonstrating artist-friendly properties, such as simple control over the latent space and resolution invariance at test time.
Efficient Incremental Potential Contact for Actuated Face Simulation
Dec 03, 2023


We present a quasi-static finite element simulator for human face animation. We model the face as an actuated soft body, which can be efficiently simulated using Projective Dynamics (PD). We adopt Incremental Potential Contact (IPC) to handle self-intersection. However, directly integrating IPC into the simulation would impede the high efficiency of the PD solver, since the stiffness matrix in the global step is no longer constant and cannot be pre-factorized. We notice that the actual number of vertices affected by the collision is only a small fraction of the whole model, and by utilizing this fact we effectively decrease the scale of the linear system to be solved. With the proposed optimization method for collision, we achieve high visual fidelity at a relatively low performance overhead.
Spatially Adaptive Cloth Regression with Implicit Neural Representations
Nov 27, 2023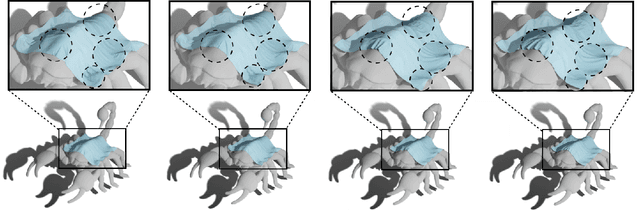
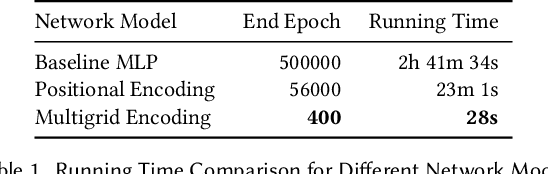
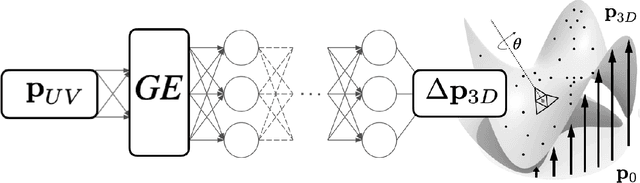
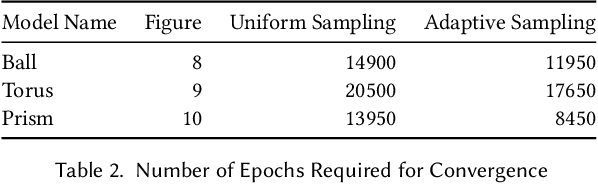
The accurate representation of fine-detailed cloth wrinkles poses significant challenges in computer graphics. The inherently non-uniform structure of cloth wrinkles mandates the employment of intricate discretization strategies, which are frequently characterized by high computational demands and complex methodologies. Addressing this, the research introduced in this paper elucidates a novel anisotropic cloth regression technique that capitalizes on the potential of implicit neural representations of surfaces. Our first core contribution is an innovative mesh-free sampling approach, crafted to reduce the reliance on traditional mesh structures, thereby offering greater flexibility and accuracy in capturing fine cloth details. Our second contribution is a novel adversarial training scheme, which is designed meticulously to strike a harmonious balance between the sampling and simulation objectives. The adversarial approach ensures that the wrinkles are represented with high fidelity, while also maintaining computational efficiency. Our results showcase through various cloth-object interaction scenarios that our method, given the same memory constraints, consistently surpasses traditional discrete representations, particularly when modelling highly-detailed localized wrinkles.
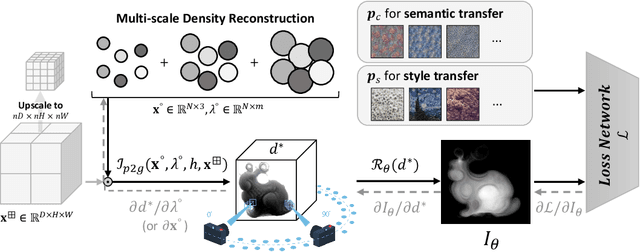
Learning to Estimate Single-View Volumetric Flow Motions without 3D Supervision
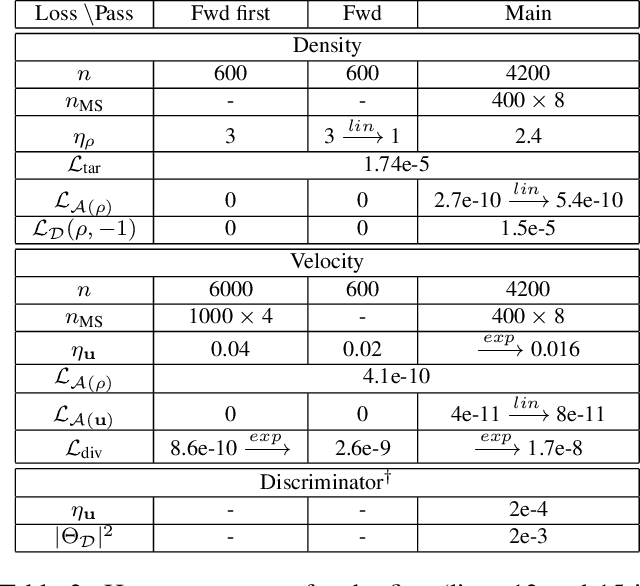
Feb 28, 2023We address the challenging problem of jointly inferring the 3D flow and volumetric densities moving in a fluid from a monocular input video with a deep neural network. Despite the complexity of this task, we show that it is possible to train the corresponding networks without requiring any 3D ground truth for training. In the absence of ground truth data we can train our model with observations from real-world capture setups instead of relying on synthetic reconstructions. We make this unsupervised training approach possible by first generating an initial prototype volume which is then moved and transported over time without the need for volumetric supervision. Our approach relies purely on image-based losses, an adversarial discriminator network, and regularization. Our method can estimate long-term sequences in a stable manner, while achieving closely matching targets for inputs such as rising smoke plumes.
Global Transport for Fluid Reconstruction with Learned Self-Supervision
Apr 13, 2021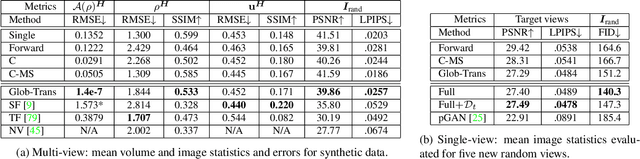
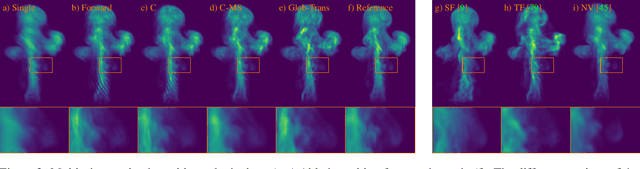

We propose a novel method to reconstruct volumetric flows from sparse views via a global transport formulation. Instead of obtaining the space-time function of the observations, we reconstruct its motion based on a single initial state. In addition we introduce a learned self-supervision that constrains observations from unseen angles. These visual constraints are coupled via the transport constraints and a differentiable rendering step to arrive at a robust end-to-end reconstruction algorithm. This makes the reconstruction of highly realistic flow motions possible, even from only a single input view. We show with a variety of synthetic and real flows that the proposed global reconstruction of the transport process yields an improved reconstruction of the fluid motion.
Lagrangian Neural Style Transfer for Fluids
May 02, 2020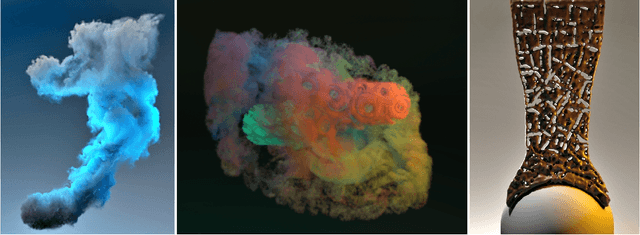
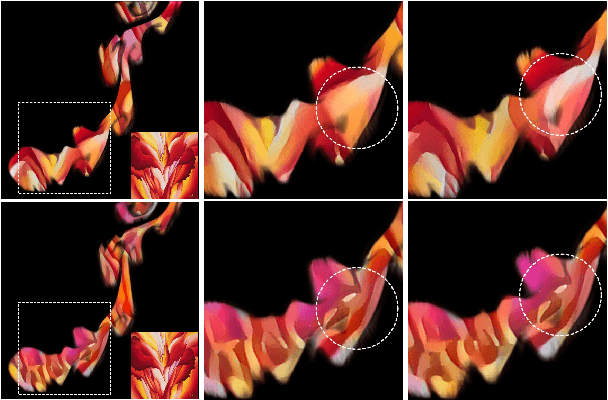
Artistically controlling the shape, motion and appearance of fluid simulations pose major challenges in visual effects production. In this paper, we present a neural style transfer approach from images to 3D fluids formulated in a Lagrangian viewpoint. Using particles for style transfer has unique benefits compared to grid-based techniques. Attributes are stored on the particles and hence are trivially transported by the particle motion. This intrinsically ensures temporal consistency of the optimized stylized structure and notably improves the resulting quality. Simultaneously, the expensive, recursive alignment of stylization velocity fields of grid approaches is unnecessary, reducing the computation time to less than an hour and rendering neural flow stylization practical in production settings. Moreover, the Lagrangian representation improves artistic control as it allows for multi-fluid stylization and consistent color transfer from images, and the generality of the method enables stylization of smoke and liquids likewise.
* ACM Transaction on Graphics (SIGGRAPH 2020), additional materials: http://www.byungsoo.me/project/lnst/index.html