 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Estimate Single-View Volumetric Flow Motions without 3D Supervision
Feb 28, 2023We address the challenging problem of jointly inferring the 3D flow and volumetric densities moving in a fluid from a monocular input video with a deep neural network. Despite the complexity of this task, we show that it is possible to train the corresponding networks without requiring any 3D ground truth for training. In the absence of ground truth data we can train our model with observations from real-world capture setups instead of relying on synthetic reconstructions. We make this unsupervised training approach possible by first generating an initial prototype volume which is then moved and transported over time without the need for volumetric supervision. Our approach relies purely on image-based losses, an adversarial discriminator network, and regularization. Our method can estimate long-term sequences in a stable manner, while achieving closely matching targets for inputs such as rising smoke plumes.
Physics Informed Neural Fields for Smoke Reconstruction with Sparse Data
Jun 14, 2022

High-fidelity reconstruction of fluids from sparse multiview RGB videos remains a formidable challenge due to the complexity of the underlying physics as well as complex occlusion and lighting in captures. Existing solutions either assume knowledge of obstacles and lighting, or only focus on simple fluid scenes without obstacles or complex lighting, and thus are unsuitable for real-world scenes with unknown lighting or arbitrary obstacles. We present the first method to reconstruct dynamic fluid by leveraging the governing physics (ie, Navier -Stokes equations) in an end-to-end optimization from sparse videos without taking lighting conditions, geometry information, or boundary conditions as input. We provide a continuous spatio-temporal scene representation using neural networks as the ansatz of density and velocity solution functions for fluids as well as the radiance field for static objects. With a hybrid architecture that separates static and dynamic contents, fluid interactions with static obstacles are reconstructed for the first time without additional geometry input or human labeling. By augmenting time-varying neural radiance fields with physics-informed deep learning, our method benefits from the supervision of images and physical priors. To achieve robust optimization from sparse views, we introduced a layer-by-layer growing strategy to progressively increase the network capacity. Using progressively growing models with a new regularization term, we manage to disentangle density-color ambiguity in radiance fields without overfitting. A pretrained density-to-velocity fluid model is leveraged in addition as the data prior to avoid suboptimal velocity which underestimates vorticity but trivially fulfills physical equations. Our method exhibits high-quality results with relaxed constraints and strong flexibility on a representative set of synthetic and real flow captures.
* accepted to ACM Transactions On Graphics (SIGGRAPH 2022), further info:\url{https://people.mpi-inf.mpg.de/~mchu/projects/PI-NeRF/}
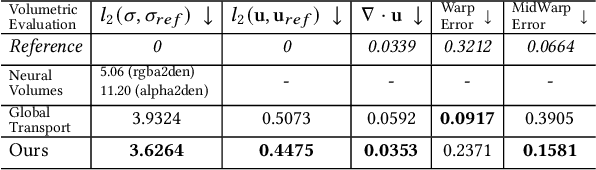
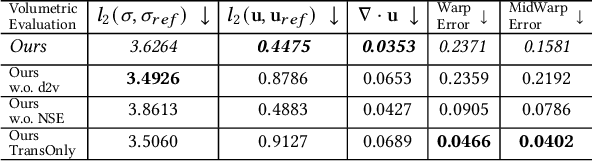
Global Transport for Fluid Reconstruction with Learned Self-Supervision
Apr 13, 2021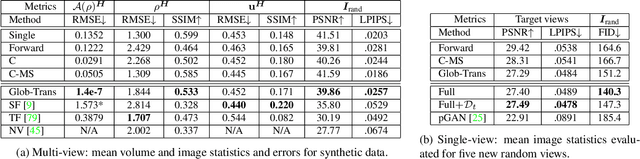
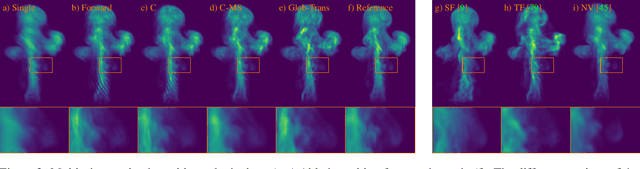

We propose a novel method to reconstruct volumetric flows from sparse views via a global transport formulation. Instead of obtaining the space-time function of the observations, we reconstruct its motion based on a single initial state. In addition we introduce a learned self-supervision that constrains observations from unseen angles. These visual constraints are coupled via the transport constraints and a differentiable rendering step to arrive at a robust end-to-end reconstruction algorithm. This makes the reconstruction of highly realistic flow motions possible, even from only a single input view. We show with a variety of synthetic and real flows that the proposed global reconstruction of the transport process yields an improved reconstruction of the fluid motion.
tempoGAN: A Temporally Coherent, Volumetric GAN for Super-resolution Fluid Flow
May 28, 2018



We propose a temporally coherent generative model addressing the super-resolution problem for fluid flows. Our work represents a first approach to synthesize four-dimensional physics fields with neural networks. Based on a conditional generative adversarial network that is designed for the inference of three-dimensional volumetric data, our model generates consistent and detailed results by using a novel temporal discriminator, in addition to the commonly used spatial one. Our experiments show that the generator is able to infer more realistic high-resolution details by using additional physical quantities, such as low-resolution velocities or vorticities. Besides improvements in the training process and in the generated outputs, these inputs offer means for artistic control as well. We additionally employ a physics-aware data augmentation step, which is crucial to avoid overfitting and to reduce memory requirements. In this way, our network learns to generate advected quantities with highly detailed, realistic, and temporally coherent features. Our method works instantaneously, using only a single time-step of low-resolution fluid data. We demonstrate the abilities of our method using a variety of complex inputs and applications in two and three dimensions.