 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Guided Unsupervised Semantic-Aware Exposure Correction
Jan 27, 2026Improper exposure often leads to severe loss of details, color distortion, and reduced contrast. Exposure correction still faces two critical challenges: (1) the ignorance of object-wise regional semantic information causes the color shift artifacts; (2) real-world exposure images generally have no ground-truth labels, and its labeling entails massive manual editing. To tackle the challenges, we propose a new unsupervised semantic-aware exposure correction network. It contains an adaptive semantic-aware fusion module, which effectively fuses the semantic information extracted from a pre-trained Fast Segment Anything Model into a shared image feature space. Then the fused features are used by our multi-scale residual spatial mamba group to restore the details and adjust the exposure. To avoid manual editing, we propose a pseudo-ground truth generator guided by CLIP, which is fine-tuned to automatically identify exposure situations and instruct the tailored corrections. Also, we leverage the rich priors from the FastSAM and CLIP to develop a semantic-prompt consistency loss to enforce semantic consistency and image-prompt alignment for unsupervised training. Comprehensive experimental results illustrate the effectiveness of our method in correcting real-world exposure images and outperforms state-of-the-art unsupervised methods both numerically and visually.
Fine-grained Verbal Attack Detection via a Hierarchical Divide-and-Conquer Framework
Jan 11, 2026In the digital era, effective identification and analysis of verbal attacks are essential for maintaining online civility and ensuring social security. However, existing research is limited by insufficient modeling of conversational structure and contextual dependency, particularly in Chinese social media where implicit attacks are prevalent. Current attack detection studies often emphasize general semantic understanding while overlooking user response relationships, hindering the identification of implicit and context-dependent attacks. To address these challenges, we present the novel "Hierarchical Attack Comment Detection" dataset and propose a divide-and-conquer, fine-grained framework for verbal attack recognition based on spatiotemporal information. The proposed dataset explicitly encodes hierarchical reply structures and chronological order, capturing complex interaction patterns in multi-turn discussions. Building on this dataset, the framework decomposes attack detection into hierarchical subtasks, where specialized lightweight models handle explicit detection, implicit intent inference, and target identification under constrained context. Extensive experiments on the proposed dataset and benchmark intention detection datasets show that smaller models using our framework significantly outperform larger monolithic models relying on parameter scaling, demonstrating the effectiveness of structured task decomposition.
Human Locomotion Implicit Modeling Based Real-Time Gait Phase Estimation
Jun 18, 2025Gait phase estimation based on inertial measurement unit (IMU) signals facilitates precise adaptation of exoskeletons to individual gait variations. However, challenges remain in achieving high accuracy and robustness, particularly during periods of terrain changes. To address this, we develop a gait phase estimation neural network based on implicit modeling of human locomotion, which combines temporal convolution for feature extraction with transformer layers for multi-channel information fusion. A channel-wise masked reconstruction pre-training strategy is proposed, which first treats gait phase state vectors and IMU signals as joint observations of human locomotion, thus enhancing model generalization. Experimental results demonstrate that the proposed method outperforms existing baseline approaches, achieving a gait phase RMSE of $2.729 \pm 1.071%$ and phase rate MAE of $0.037 \pm 0.016%$ under stable terrain conditions with a look-back window of 2 seconds, and a phase RMSE of $3.215 \pm 1.303%$ and rate MAE of $0.050 \pm 0.023%$ under terrain transitions. Hardware validation on a hip exoskeleton further confirms that the algorithm can reliably identify gait cycles and key events, adapting to various continuous motion scenarios. This research paves the way for more intelligent and adaptive exoskeleton systems, enabling safer and more efficient human-robot interaction across diverse real-world environments.
Learning Novel View Synthesis from Heterogeneous Low-light Captures
Mar 20, 2024



Neural radiance field has achieved fundamental success in novel view synthesis from input views with the same brightness level captured under fixed normal lighting. Unfortunately, synthesizing novel views remains to be a challenge for input views with heterogeneous brightness level captured under low-light condition. The condition is pretty common in the real world. It causes low-contrast images where details are concealed in the darkness and camera sensor noise significantly degrades the image quality. To tackle this problem, we propose to learn to decompose illumination, reflectance, and noise from input views according to that reflectance remains invariant across heterogeneous views. To cope with heterogeneous brightness and noise levels across multi-views, we learn an illumination embedding and optimize a noise map individually for each view. To allow intuitive editing of the illumination, we design an illumination adjustment module to enable either brightening or darkening of the illumination component. Comprehensive experiments demonstrate that this approach enables effective intrinsic decomposition for low-light multi-view noisy images and achieves superior visual quality and numerical performance for synthesizing novel views compared to state-of-the-art methods.
3D-SceneDreamer: Text-Driven 3D-Consistent Scene Generation
Mar 14, 2024Text-driven 3D scene generation techniques have made rapid progress in recent years. Their success is mainly attributed to using existing generative models to iteratively perform image warping and inpainting to generate 3D scenes. However, these methods heavily rely on the outputs of existing models, leading to error accumulation in geometry and appearance that prevent the models from being used in various scenarios (e.g., outdoor and unreal scenarios). To address this limitation, we generatively refine the newly generated local views by querying and aggregating global 3D information, and then progressively generate the 3D scene. Specifically, we employ a tri-plane features-based NeRF as a unified representation of the 3D scene to constrain global 3D consistency, and propose a generative refinement network to synthesize new contents with higher quality by exploiting the natural image prior from 2D diffusion model as well as the global 3D information of the current scene. Our extensive experiments demonstrate that, in comparison to previous methods, our approach supports wide variety of scene generation and arbitrary camera trajectories with improved visual quality and 3D consistency.
Neural Invertible Variable-degree Optical Aberrations Correction
Apr 12, 2023



Optical aberrations of optical systems cause significant degradation of imaging quality. Aberration correction by sophisticated lens designs and special glass materials generally incurs high cost of manufacturing and the increase in the weight of optical systems, thus recent work has shifted to aberration correction with deep learning-based post-processing. Though real-world optical aberrations vary in degree, existing methods cannot eliminate variable-degree aberrations well, especially for the severe degrees of degradation. Also, previous methods use a single feed-forward neural network and suffer from information loss in the output. To address the issues, we propose a novel aberration correction method with an invertible architecture by leveraging its information-lossless property. Within the architecture, we develop conditional invertible blocks to allow the processing of aberrations with variable degrees. Our method is evaluated on both a synthetic dataset from physics-based imaging simulation and a real captured dataset. Quantitative and qualitative experimental results demonstrate that our method outperforms compared methods in correcting variable-degree optical aberrations.
A survey on facial image deblurring
Feb 10, 2023When the facial image is blurred, it has a great impact on high-level vision tasks such as face recognition. The purpose of facial image deblurring is to recover a clear image from a blurry input image, which can improve the recognition accuracy and so on. General deblurring methods can not perform well on facial images. So some face deblurring methods are proposed to improve the performance by adding semantic or structural information as specific priors according to the characteristics of facial images. This paper surveys and summarizes recently published methods for facial image deblurring, most of which are based on deep learning. Firstly, we give a brief introduction to the modeling of image blur. Next, we summarize face deblurring methods into two categories, namely model-based methods and deep learning-based methods. Furthermore, we summarize the datasets, loss functions, and performance evaluation metrics commonly used in the neural network training process. We show the performance of classical methods on these datasets and metrics and give a brief discussion on the differences of model-based and learning-based methods. Finally, we discuss current challenges and possible future research directions.
Shap-CAM: Visual Explanations for Convolutional Neural Networks based on Shapley Value
Aug 09, 2022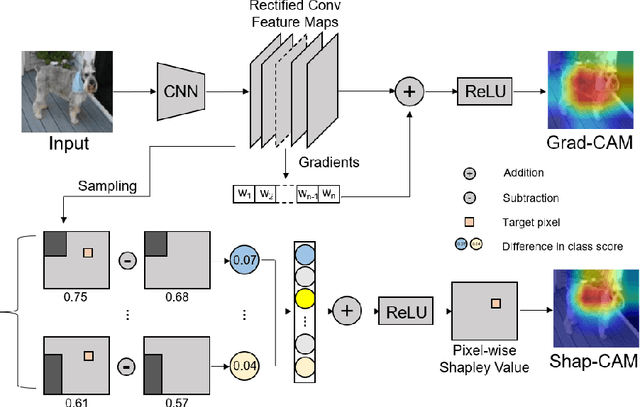

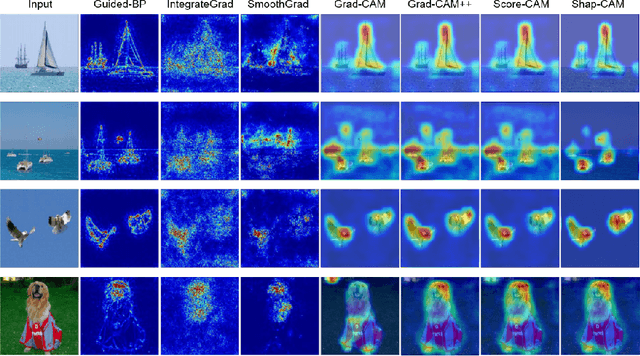

Explaining deep convolutional neural networks has been recently drawing increasing attention since it helps to understand the networks' internal operations and why they make certain decisions. Saliency maps, which emphasize salient regions largely connected to the network's decision-making, are one of the most common ways for visualizing and analyzing deep networks in the computer vision community. However, saliency maps generated by existing methods cannot represent authentic information in images due to the unproven proposals about the weights of activation maps which lack solid theoretical foundation and fail to consider the relations between each pixel. In this paper, we develop a novel post-hoc visual explanation method called Shap-CAM based on class activation mapping. Unlike previous gradient-based approaches, Shap-CAM gets rid of the dependence on gradients by obtaining the importance of each pixel through Shapley value. We demonstrate that Shap-CAM achieves better visual performance and fairness for interpreting the decision making process. Our approach outperforms previous methods on both recognition and localization tasks.
Physics Informed Neural Fields for Smoke Reconstruction with Sparse Data
Jun 14, 2022
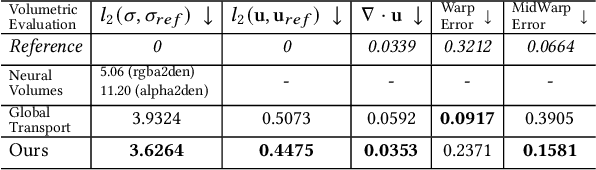

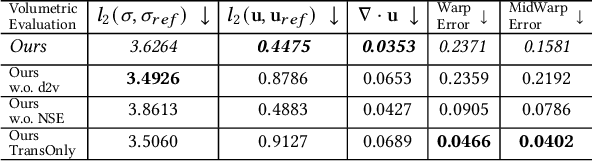
High-fidelity reconstruction of fluids from sparse multiview RGB videos remains a formidable challenge due to the complexity of the underlying physics as well as complex occlusion and lighting in captures. Existing solutions either assume knowledge of obstacles and lighting, or only focus on simple fluid scenes without obstacles or complex lighting, and thus are unsuitable for real-world scenes with unknown lighting or arbitrary obstacles. We present the first method to reconstruct dynamic fluid by leveraging the governing physics (ie, Navier -Stokes equations) in an end-to-end optimization from sparse videos without taking lighting conditions, geometry information, or boundary conditions as input. We provide a continuous spatio-temporal scene representation using neural networks as the ansatz of density and velocity solution functions for fluids as well as the radiance field for static objects. With a hybrid architecture that separates static and dynamic contents, fluid interactions with static obstacles are reconstructed for the first time without additional geometry input or human labeling. By augmenting time-varying neural radiance fields with physics-informed deep learning, our method benefits from the supervision of images and physical priors. To achieve robust optimization from sparse views, we introduced a layer-by-layer growing strategy to progressively increase the network capacity. Using progressively growing models with a new regularization term, we manage to disentangle density-color ambiguity in radiance fields without overfitting. A pretrained density-to-velocity fluid model is leveraged in addition as the data prior to avoid suboptimal velocity which underestimates vorticity but trivially fulfills physical equations. Our method exhibits high-quality results with relaxed constraints and strong flexibility on a representative set of synthetic and real flow captures.
* accepted to ACM Transactions On Graphics (SIGGRAPH 2022), further info:\url{https://people.mpi-inf.mpg.de/~mchu/projects/PI-NeRF/}
Neural Relightable Participating Media Rendering
Oct 25, 2021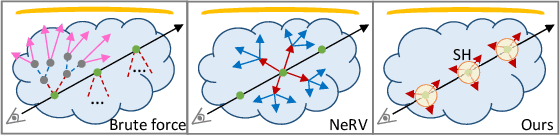
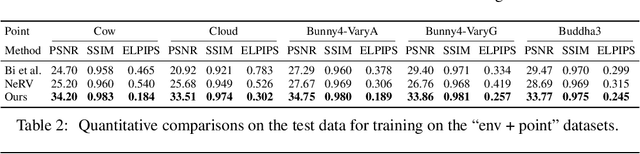
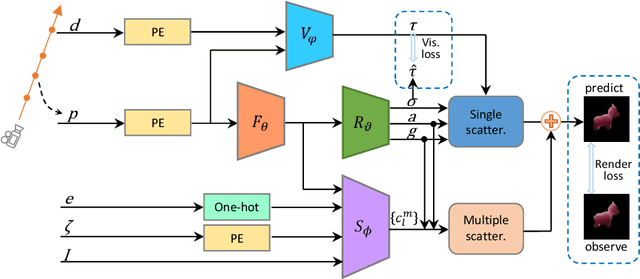

Learning neural radiance fields of a scene has recently allowed realistic novel view synthesis of the scene, but they are limited to synthesize images under the original fixed lighting condition. Therefore, they are not flexible for the eagerly desired tasks like relighting, scene editing and scene composition. To tackle this problem, several recent methods propose to disentangle reflectance and illumination from the radiance field. These methods can cope with solid objects with opaque surfaces but participating media are neglected. Also, they take into account only direct illumination or at most one-bounce indirect illumination, thus suffer from energy loss due to ignoring the high-order indirect illumination. We propose to learn neural representations for participating media with a complete simulation of global illumination. We estimate direct illumination via ray tracing and compute indirect illumination with spherical harmonics. Our approach avoids computing the lengthy indirect bounces and does not suffer from energy loss. Our experiments on multiple scenes show that our approach achieves superior visual quality and numerical performance compared to state-of-the-art methods, and it can generalize to deal with solid objects with opaque surfaces as well.