 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics Informed Neural Fields for Smoke Reconstruction with Sparse Data
Paper and Code
Jun 14, 2022
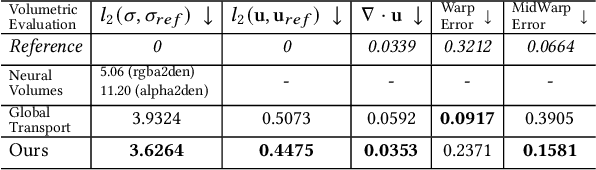

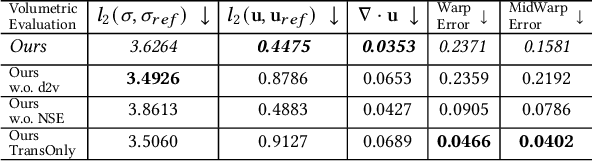
High-fidelity reconstruction of fluids from sparse multiview RGB videos remains a formidable challenge due to the complexity of the underlying physics as well as complex occlusion and lighting in captures. Existing solutions either assume knowledge of obstacles and lighting, or only focus on simple fluid scenes without obstacles or complex lighting, and thus are unsuitable for real-world scenes with unknown lighting or arbitrary obstacles. We present the first method to reconstruct dynamic fluid by leveraging the governing physics (ie, Navier -Stokes equations) in an end-to-end optimization from sparse videos without taking lighting conditions, geometry information, or boundary conditions as input. We provide a continuous spatio-temporal scene representation using neural networks as the ansatz of density and velocity solution functions for fluids as well as the radiance field for static objects. With a hybrid architecture that separates static and dynamic contents, fluid interactions with static obstacles are reconstructed for the first time without additional geometry input or human labeling. By augmenting time-varying neural radiance fields with physics-informed deep learning, our method benefits from the supervision of images and physical priors. To achieve robust optimization from sparse views, we introduced a layer-by-layer growing strategy to progressively increase the network capacity. Using progressively growing models with a new regularization term, we manage to disentangle density-color ambiguity in radiance fields without overfitting. A pretrained density-to-velocity fluid model is leveraged in addition as the data prior to avoid suboptimal velocity which underestimates vorticity but trivially fulfills physical equations. Our method exhibits high-quality results with relaxed constraints and strong flexibility on a representative set of synthetic and real flow captures.