 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Large Language Models for Time-Series Forecasting via Vector-Injected In-Context Learning
Jan 12, 2026The World Wide Web needs reliable predictive capabilities to respond to changes in user behavior and usage patterns. Time series forecasting (TSF) is a key means to achieve this goal. In recent years, the large language models (LLMs) for TSF (LLM4TSF) have achieved good performance. However, there is a significant difference between pretraining corpora and time series data, making it hard to guarantee forecasting quality when directly applying LLMs to TSF; fine-tuning LLMs can mitigate this issue, but often incurs substantial computational overhead. Thus, LLM4TSF faces a dual challenge of prediction performance and compute overhead. To address this, we aim to explore a method for improving the forecasting performance of LLM4TSF while freezing all LLM parameters to reduce computational overhead. Inspired by in-context learning (ICL), we propose LVICL. LVICL uses our vector-injected ICL to inject example information into a frozen LLM, eliciting its in-context learning ability and thereby enhancing its performance on the example-related task (i.e., TSF). Specifically, we first use the LLM together with a learnable context vector adapter to extract a context vector from multiple examples adaptively. This vector contains compressed, example-related information. Subsequently, during the forward pass, we inject this vector into every layer of the LLM to improve forecasting performance. Compared with conventional ICL that adds examples into the prompt, our vector-injected ICL does not increase prompt length; moreover, adaptively deriving a context vector from examples suppresses components harmful to forecasting, thereby improving model performance. Extensive experiments demonstrate the effectiveness of our approach.
AmPLe: Supporting Vision-Language Models via Adaptive-Debiased Ensemble Multi-Prompt Learning
Dec 20, 2025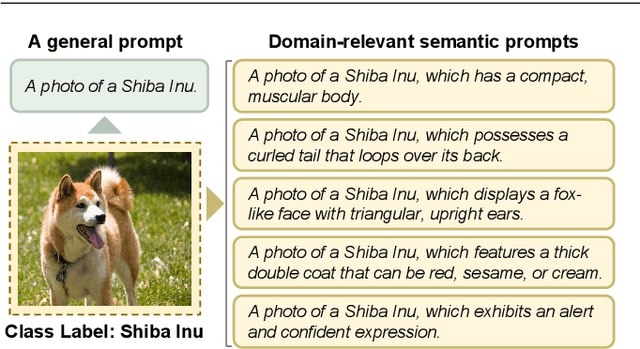

Multi-prompt learning methods have emerged as an effective approach for facilitating the rapid adaptation of vision-language models to downstream tasks with limited resources. Existing multi-prompt learning methods primarily focus on utilizing various meticulously designed prompts within a single foundation vision-language model to achieve superior performance. However, the overlooked model-prompt matching bias hinders the development of multi-prompt learning, i.e., the same prompt can convey different semantics across distinct vision-language models, such as CLIP-ViT-B/16 and CLIP-ViT-B/32, resulting in inconsistent predictions of identical prompt. To mitigate the impact of this bias on downstream tasks, we explore an ensemble learning approach to sufficiently aggregate the benefits of diverse predictions. Additionally, we further disclose the presence of sample-prompt matching bias, which originates from the prompt-irrelevant semantics encapsulated in the input samples. Thus, directly utilizing all information from the input samples for generating weights of ensemble learning can lead to suboptimal performance. In response, we extract prompt-relevant semantics from input samples by leveraging the guidance of the information theory-based analysis, adaptively calculating debiased ensemble weights. Overall, we propose Adaptive-Debiased Ensemble MultiPrompt Learning, abbreviated as AmPLe, to mitigate the two types of bias simultaneously. Extensive experiments on three representative tasks, i.e., generalization to novel classes, new target datasets, and unseen domain shifts, show that AmPLe can widely outperform existing methods. Theoretical validation from a causal perspective further supports the effectiveness of AmPLe.
CellCLAT: Preserving Topology and Trimming Redundancy in Self-Supervised Cellular Contrastive Learning
May 27, 2025Self-supervised topological deep learning (TDL) represents a nascent but underexplored area with significant potential for modeling higher-order interactions in simplicial complexes and cellular complexes to derive representations of unlabeled graphs. Compared to simplicial complexes, cellular complexes exhibit greater expressive power. However, the advancement in self-supervised learning for cellular TDL is largely hindered by two core challenges: \textit{extrinsic structural constraints} inherent to cellular complexes, and intrinsic semantic redundancy in cellular representations. The first challenge highlights that traditional graph augmentation techniques may compromise the integrity of higher-order cellular interactions, while the second underscores that topological redundancy in cellular complexes potentially diminish task-relevant information. To address these issues, we introduce Cellular Complex Contrastive Learning with Adaptive Trimming (CellCLAT), a twofold framework designed to adhere to the combinatorial constraints of cellular complexes while mitigating informational redundancy. Specifically, we propose a parameter perturbation-based augmentation method that injects controlled noise into cellular interactions without altering the underlying cellular structures, thereby preserving cellular topology during contrastive learning. Additionally, a cellular trimming scheduler is employed to mask gradient contributions from task-irrelevant cells through a bi-level meta-learning approach, effectively removing redundant topological elements while maintaining critical higher-order semantics. We provide theoretical justification and empirical validation to demonstrate that CellCLAT achieves substantial improvements over existing self-supervised graph learning methods, marking a significant attempt in this domain.
Continual Test-Time Adaptation for Single Image Defocus Deblurring via Causal Siamese Networks
Jan 15, 2025



Single image defocus deblurring (SIDD) aims to restore an all-in-focus image from a defocused one. Distribution shifts in defocused images generally lead to performance degradation of existing methods during out-of-distribution inferences. In this work, we gauge the intrinsic reason behind the performance degradation, which is identified as the heterogeneity of lens-specific point spread functions. Empirical evidence supports this finding, motivating us to employ a continual test-time adaptation (CTTA) paradigm for SIDD. However, traditional CTTA methods, which primarily rely on entropy minimization, cannot sufficiently explore task-dependent information for pixel-level regression tasks like SIDD. To address this issue, we propose a novel Siamese networks-based continual test-time adaptation framework, which adapts source models to continuously changing target domains only requiring unlabeled target data in an online manner. To further mitigate semantically erroneous textures introduced by source SIDD models under severe degradation, we revisit the learning paradigm through a structural causal model and propose Causal Siamese networks (CauSiam). Our method leverages large-scale pre-trained vision-language models to derive discriminative universal semantic priors and integrates these priors into Siamese networks, ensuring causal identifiability between blurry inputs and restored images. Extensive experiments demonstrate that CauSiam effectively improves the generalization performance of existing SIDD methods in continuously changing domains.
Understanding Individual Agent Importance in Multi-Agent System via Counterfactual Reasoning
Dec 23, 2024Explaining multi-agent systems (MAS) is urgent as these systems become increasingly prevalent in various applications. Previous work has proveided explanations for the actions or states of agents, yet falls short in understanding the black-boxed agent's importance within a MAS and the overall team strategy. To bridge this gap, we propose EMAI, a novel agent-level explanation approach that evaluates the individual agent's importance. Inspired by counterfactual reasoning, a larger change in reward caused by the randomized action of agent indicates its higher importance. We model it as a MARL problem to capture interactions across agents. Utilizing counterfactual reasoning, EMAI learns the masking agents to identify important agents. Specifically, we define the optimization function to minimize the reward difference before and after action randomization and introduce sparsity constraints to encourage the exploration of more action randomization of agents during training. The experimental results in seven multi-agent tasks demonstratee that EMAI achieves higher fidelity in explanations than baselines and provides more effective guidance in practical applications concerning understanding policies, launching attacks, and patching policies.
A Physical Model-Guided Framework for Underwater Image Enhancement and Depth Estimation
Jul 05, 2024
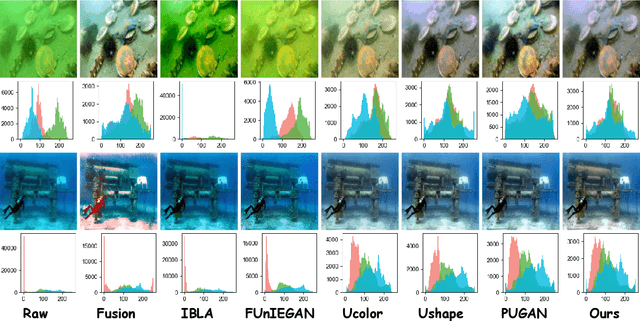


Due to the selective absorption and scattering of light by diverse aquatic media, underwater images usually suffer from various visual degradations. Existing underwater image enhancement (UIE) approaches that combine underwater physical imaging models with neural networks often fail to accurately estimate imaging model parameters such as depth and veiling light, resulting in poor performance in certain scenarios. To address this issue, we propose a physical model-guided framework for jointly training a Deep Degradation Model (DDM) with any advanced UIE model. DDM includes three well-designed sub-networks to accurately estimate various imaging parameters: a veiling light estimation sub-network, a factors estimation sub-network, and a depth estimation sub-network. Based on the estimated parameters and the underwater physical imaging model, we impose physical constraints on the enhancement process by modeling the relationship between underwater images and desired clean images, i.e., outputs of the UIE model. Moreover, while our framework is compatible with any UIE model, we design a simple yet effective fully convolutional UIE model, termed UIEConv. UIEConv utilizes both global and local features for image enhancement through a dual-branch structure. UIEConv trained within our framework achieves remarkable enhancement results across diverse underwater scenes. Furthermore, as a byproduct of UIE, the trained depth estimation sub-network enables accurate underwater scene depth estimation. Extensive experiments conducted in various real underwater imaging scenarios, including deep-sea environments with artificial light sources, validate the effectiveness of our framework and the UIEConv model.
Teleporter Theory: A General and Simple Approach for Modeling Cross-World Counterfactual Causality
Jun 18, 2024Leveraging the development of structural causal model (SCM), researchers can establish graphical models for exploring the causal mechanisms behind machine learning techniques. As the complexity of machine learning applications rises, single-world interventionism causal analysis encounters theoretical adaptation limitations. Accordingly, cross-world counterfactual approach extends our understanding of causality beyond observed data, enabling hypothetical reasoning about alternative scenarios. However, the joint involvement of cross-world variables, encompassing counterfactual variables and real-world variables, challenges the construction of the graphical model. Twin network is a subtle attempt, establishing a symbiotic relationship, to bridge the gap between graphical modeling and the introduction of counterfactuals albeit with room for improvement in generalization. In this regard, we demonstrate the theoretical breakdowns of twin networks in certain cross-world counterfactual scenarios. To this end, we propose a novel teleporter theory to establish a general and simple graphical representation of counterfactuals, which provides criteria for determining teleporter variables to connect multiple worlds. In theoretical application, we determine that introducing the proposed teleporter theory can directly obtain the conditional independence between counterfactual variables and real-world variables from the cross-world SCM without requiring complex algebraic derivations. Accordingly, we can further identify counterfactual causal effects through cross-world symbolic derivation. We demonstrate the generality of the teleporter theory to the practical application. Adhering to the proposed theory, we build a plug-and-play module, and the effectiveness of which are substantiated by experiments on benchmarks.
Intriguing Properties of Positional Encoding in Time Series Forecasting
Apr 16, 2024Transformer-based methods have made significant progress in time series forecasting (TSF). They primarily handle two types of tokens, i.e., temporal tokens that contain all variables of the same timestamp, and variable tokens that contain all input time points for a specific variable. Transformer-based methods rely on positional encoding (PE) to mark tokens' positions, facilitating the model to perceive the correlation between tokens. However, in TSF, research on PE remains insufficient. To address this gap, we conduct experiments and uncover intriguing properties of existing PEs in TSF: (i) The positional information injected by PEs diminishes as the network depth increases; (ii) Enhancing positional information in deep networks is advantageous for improving the model's performance; (iii) PE based on the similarity between tokens can improve the model's performance. Motivated by these findings, we introduce two new PEs: Temporal Position Encoding (T-PE) for temporal tokens and Variable Positional Encoding (V-PE) for variable tokens. Both T-PE and V-PE incorporate geometric PE based on tokens' positions and semantic PE based on the similarity between tokens but using different calculations. To leverage both the PEs, we design a Transformer-based dual-branch framework named T2B-PE. It first calculates temporal tokens' correlation and variable tokens' correlation respectively and then fuses the dual-branch features through the gated unit. Extensive experiments demonstrate the superior robustness and effectiveness of T2B-PE. The code is available at: \href{https://github.com/jlu-phyComputer/T2B-PE}{https://github.com/jlu-phyComputer/T2B-PE}.
Learning Novel View Synthesis from Heterogeneous Low-light Captures
Mar 20, 2024Neural radiance field has achieved fundamental success in novel view synthesis from input views with the same brightness level captured under fixed normal lighting. Unfortunately, synthesizing novel views remains to be a challenge for input views with heterogeneous brightness level captured under low-light condition. The condition is pretty common in the real world. It causes low-contrast images where details are concealed in the darkness and camera sensor noise significantly degrades the image quality. To tackle this problem, we propose to learn to decompose illumination, reflectance, and noise from input views according to that reflectance remains invariant across heterogeneous views. To cope with heterogeneous brightness and noise levels across multi-views, we learn an illumination embedding and optimize a noise map individually for each view. To allow intuitive editing of the illumination, we design an illumination adjustment module to enable either brightening or darkening of the illumination component. Comprehensive experiments demonstrate that this approach enables effective intrinsic decomposition for low-light multi-view noisy images and achieves superior visual quality and numerical performance for synthesizing novel views compared to state-of-the-art methods.
End-To-End Underwater Video Enhancement: Dataset and Model
Mar 18, 2024Underwater video enhancement (UVE) aims to improve the visibility and frame quality of underwater videos, which has significant implications for marine research and exploration. However, existing methods primarily focus on developing image enhancement algorithms to enhance each frame independently. There is a lack of supervised datasets and models specifically tailored for UVE tasks. To fill this gap, we construct the Synthetic Underwater Video Enhancement (SUVE) dataset, comprising 840 diverse underwater-style videos paired with ground-truth reference videos. Based on this dataset, we train a novel underwater video enhancement model, UVENet, which utilizes inter-frame relationships to achieve better enhancement performance. Through extensive experiments on both synthetic and real underwater videos, we demonstrate the effectiveness of our approach. This study represents the first comprehensive exploration of UVE to our knowledge. The code is available at https://anonymous.4open.science/r/UVENet.