 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain the Agent, Not the Expert: Learning to Harness Heterogeneous Experts for Multi-Turn Visual Reasoning
May 28, 2026Recent progress in computer vision has produced a wide range of powerful specialized models for detection, segmentation, counting, and other visual tasks. However, these models are usually optimized for isolated task formulations, making it difficult to directly support general-purpose visual intelligence, especially when a task requires complex language understanding and dense small-object perception. In this paper, we propose VisHarness, a trainable visual agent that decouples high-level perception, reasoning, and decision-making from low-level task execution. Instead of training a model to solve a specific visual task, VisHarness learns to harness a set of carefully designed heterogeneous visual experts. This paradigm preserves the general intelligence of the agent while fully leveraging the precision advantages of specialized visual models in concrete visual tasks. With only lightweight training, VisHarness learns a generalizable visual expert-harnessing policy and can solve common fundamental vision tasks under various complex conditions through multi-turn interactions with visual expert models. To enable efficient on-policy reinforcement learning training in a live environment, we introduce dynamic visual memory archiving, which mitigates the rapidly accumulating visual-token overhead caused by multi-turn interactions with visual expert models. Experiments on four representative benchmarks covering reasoning segmentation, generalized referring segmentation, dense small-object detection, and referring counting demonstrate that VisHarness substantially outperforms existing general-purpose models and achieves competitive or superior performance compared with task-specific models.
WorldCraft: From Camera Navigation to Object Manipulation in Interactive Video World Models
May 24, 2026Recent video-based world models have made pixel-space environments interactive at the camera level: users can navigate viewpoints while the model generates coherent visual continuations. Yet their action spaces remain incomplete: users can move the camera, but cannot act on individual objects. Since real-world interaction is inherently object-centric, such models remain closer to passive scene observers than truly manipulable environments. We present WorldCraft, a framework that expands interactive video world models from camera navigation to object-level trajectory actions. Given a user click and a sketched path, WorldCraft generates future frames in which the selected object follows the prescribed trajectory while the camera continues to navigate the scene. WorldCraft achieves this through a trajectory-centric control pipeline: First, Normalized World Trajectory (NWT) represents user-drawn motion in a camera-invariant world coordinate system and dynamically re-projects it under the current camera pose, separating object motion from camera-induced screen-space displacement; Spatial-Pathway LoRA (SP-LoRA) then injects this world-space signal through the model's spatial-control pathway, adding object manipulation capability while preserving the pretrained camera controller; finally, Trajectory-Anchored State Persistence (TASP) treats the world trajectory as a persistent spatial state and refreshes autoregressive memory after trajectory-conditioned generation, allowing moved objects to reappear at their updated positions after leaving the camera view. Experiments show that WorldCraft enables accurate object control, preserves the video-based world model's camera fidelity under camera-only evaluation, and maintains object state across long autoregressive rollouts with off-camera excursions.
MLLMs Know When Before Speaking: Revealing and Recovering Temporal Grounding via Attention Cues
May 21, 2026Video temporal grounding (VTG), which localizes the start and end times of a queried event in an untrimmed video, is a key test of whether multimodal large language models (MLLMs) understand not only what happens but also when it happens. Although modern MLLMs describe video content fluently, their timestamp predictions remain unreliable, while existing remedies either require costly post-training on temporal annotations or rely on coarse training-free heuristics. In this work, we probe the cross-modal attention of MLLMs and uncover a perception-generation gap. Our key finding is that MLLMs often know the target interval during prefill, but lose this signal when generating the final answer. In the prefill stage, a sparse set of attention heads, which we call \emph{Temporal Grounding Heads} (TG-Heads), concentrates query-to-video attention on the ground-truth interval. During autoregressive decoding, however, the answer tokens shift attention away from this interval toward visually salient but query-irrelevant segments. This observation motivates an inference-time read-then-regenerate framework. We first convert TG-Head prefill attention into a debiased frame-level relevance signal and extract the high-attention interval it highlights. We then re-invoke the MLLM with visual context restricted to this interval, using video cropping or attention masking to suppress distractors. Without parameter updates and architectural changes, our framework consistently improves MiMo-VL-7B, Qwen3-VL-8B, and TimeLens-8B on three VTG benchmarks, with gains of up to +3.5 mIoU. The project website can be found at https://ddz16.github.io/mllmsknowwhen.github.io/.
Learning Spatiotemporal Sensitivity in Video LLMs via Counterfactual Reinforcement Learning
May 21, 2026Video large language models (Video LLMs) achieve strong benchmark accuracy, yet often answer video questions through shortcuts such as single-frame cues and language priors rather than by tracking spatiotemporal dynamics. This issue is exacerbated in RL post-training, where correctness-only rewards can further reinforce shortcut policies that obtain high reward without tracking video dynamics. We address this by asking a controlled counterfactual question: if the visual world changed while the question remained fixed, should the answer change or stay the same? Based on this view, we propose \textbf{Counterfactual Relational Policy Optimization (CRPO)}, a dual-branch RL framework for improving \emph{spatiotemporal sensitivity}. CRPO constructs counterfactual videos through horizontal flips and temporal reversals, trains on both original and counterfactual branches, and introduces a \textbf{Counterfactual Relation Reward (CRR)} between their answers. CRR encourages answers to change for dynamic questions and remain unchanged for static questions. This cross-branch constraint makes it difficult for shortcut policies to be consistently rewarded across both branches. To evaluate this property, we introduce \textbf{DyBench}, a paired counterfactual video benchmark with 3,014 videos covering reversible dynamics, moving direction, and event sequence, together with a strict pair-accuracy metric that prevents fixed-answer shortcuts from inflating scores. Experiments show that CRPO outperforms prior RL methods on spatiotemporal-sensitive evaluations while maintaining competitive general video performance. On Qwen3-VL-8B, CRPO improves DyBench P-Acc by +7.7 and TimeBlind I-Acc by +8.2 over the base model, indicating improved spatiotemporal sensitivity rather than stronger reliance on static shortcuts. The project website can be found at https://ddz16.github.io/crpo.github.io/ .
Mesh-Pro: Asynchronous Advantage-guided Ranking Preference Optimization for Artist-style Quadrilateral Mesh Generation
Feb 28, 2026Reinforcement learning (RL) has demonstrated remarkable success in text and image generation, yet its potential in 3D generation remains largely unexplored. Existing attempts typically rely on offline direct preference optimization (DPO) method, which suffers from low training efficiency and limited generalization. In this work, we aim to enhance both the training efficiency and generation quality of RL in 3D mesh generation. Specifically, (1) we design the first asynchronous online RL framework tailored for 3D mesh generation post-training efficiency improvement, which is 3.75$\times$ faster than synchronous RL. (2) We propose Advantage-guided Ranking Preference Optimization (ARPO), a novel RL algorithm that achieves a better trade-off between training efficiency and generalization than current RL algorithms designed for 3D mesh generation, such as DPO and group relative policy optimization (GRPO). (3) Based on asynchronous ARPO, we propose Mesh-Pro, which additionally introduces a novel diagonal-aware mixed triangular-quadrilateral tokenization for mesh representation and a ray-based reward for geometric integrity. Mesh-Pro achieves state-of-the-art performance on artistic and dense meshes.
Predicting the Future by Retrieving the Past
Nov 08, 2025Deep learning models such as MLP, Transformer, and TCN have achieved remarkable success in univariate time series forecasting, typically relying on sliding window samples from historical data for training. However, while these models implicitly compress historical information into their parameters during training, they are unable to explicitly and dynamically access this global knowledge during inference, relying only on the local context within the lookback window. This results in an underutilization of rich patterns from the global history. To bridge this gap, we propose Predicting the Future by Retrieving the Past (PFRP), a novel approach that explicitly integrates global historical data to enhance forecasting accuracy. Specifically, we construct a Global Memory Bank (GMB) to effectively store and manage global historical patterns. A retrieval mechanism is then employed to extract similar patterns from the GMB, enabling the generation of global predictions. By adaptively combining these global predictions with the outputs of any local prediction model, PFRP produces more accurate and interpretable forecasts. Extensive experiments conducted on seven real-world datasets demonstrate that PFRP significantly enhances the average performance of advanced univariate forecasting models by 8.4\%. Codes can be found in https://github.com/ddz16/PFRP.
A Physical Model-Guided Framework for Underwater Image Enhancement and Depth Estimation
Jul 05, 2024


Due to the selective absorption and scattering of light by diverse aquatic media, underwater images usually suffer from various visual degradations. Existing underwater image enhancement (UIE) approaches that combine underwater physical imaging models with neural networks often fail to accurately estimate imaging model parameters such as depth and veiling light, resulting in poor performance in certain scenarios. To address this issue, we propose a physical model-guided framework for jointly training a Deep Degradation Model (DDM) with any advanced UIE model. DDM includes three well-designed sub-networks to accurately estimate various imaging parameters: a veiling light estimation sub-network, a factors estimation sub-network, and a depth estimation sub-network. Based on the estimated parameters and the underwater physical imaging model, we impose physical constraints on the enhancement process by modeling the relationship between underwater images and desired clean images, i.e., outputs of the UIE model. Moreover, while our framework is compatible with any UIE model, we design a simple yet effective fully convolutional UIE model, termed UIEConv. UIEConv utilizes both global and local features for image enhancement through a dual-branch structure. UIEConv trained within our framework achieves remarkable enhancement results across diverse underwater scenes. Furthermore, as a byproduct of UIE, the trained depth estimation sub-network enables accurate underwater scene depth estimation. Extensive experiments conducted in various real underwater imaging scenarios, including deep-sea environments with artificial light sources, validate the effectiveness of our framework and the UIEConv model.
End-To-End Underwater Video Enhancement: Dataset and Model
Mar 18, 2024Underwater video enhancement (UVE) aims to improve the visibility and frame quality of underwater videos, which has significant implications for marine research and exploration. However, existing methods primarily focus on developing image enhancement algorithms to enhance each frame independently. There is a lack of supervised datasets and models specifically tailored for UVE tasks. To fill this gap, we construct the Synthetic Underwater Video Enhancement (SUVE) dataset, comprising 840 diverse underwater-style videos paired with ground-truth reference videos. Based on this dataset, we train a novel underwater video enhancement model, UVENet, which utilizes inter-frame relationships to achieve better enhancement performance. Through extensive experiments on both synthetic and real underwater videos, we demonstrate the effectiveness of our approach. This study represents the first comprehensive exploration of UVE to our knowledge. The code is available at https://anonymous.4open.science/r/UVENet.
UIEDP:Underwater Image Enhancement with Diffusion Prior
Dec 11, 2023
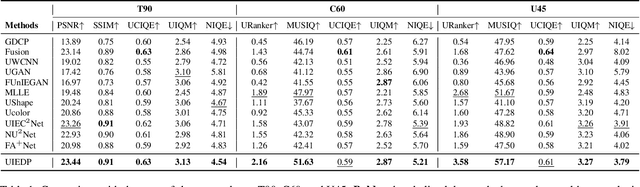
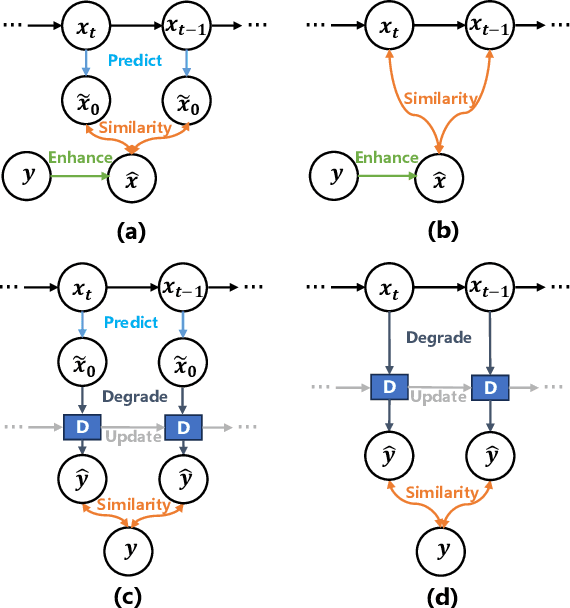

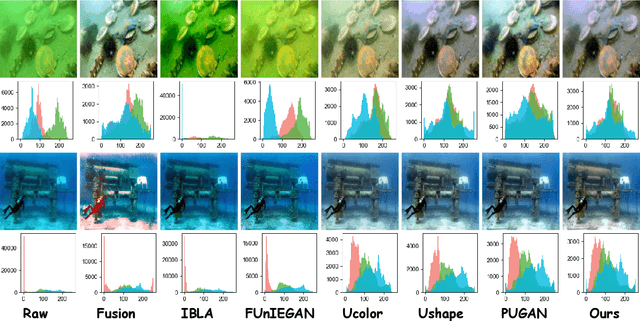
Underwater image enhancement (UIE) aims to generate clear images from low-quality underwater images. Due to the unavailability of clear reference images, researchers often synthesize them to construct paired datasets for training deep models. However, these synthesized images may sometimes lack quality, adversely affecting training outcomes. To address this issue, we propose UIE with Diffusion Prior (UIEDP), a novel framework treating UIE as a posterior distribution sampling process of clear images conditioned on degraded underwater inputs. Specifically, UIEDP combines a pre-trained diffusion model capturing natural image priors with any existing UIE algorithm, leveraging the latter to guide conditional generation. The diffusion prior mitigates the drawbacks of inferior synthetic images, resulting in higher-quality image generation. Extensive experiments have demonstrated that our UIEDP yields significant improvements across various metrics, especially no-reference image quality assessment. And the generated enhanced images also exhibit a more natural appearance.
Timestamp-Supervised Action Segmentation in the Perspective of Clustering
Dec 22, 2022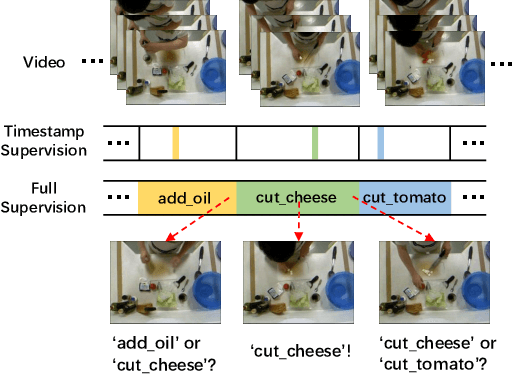
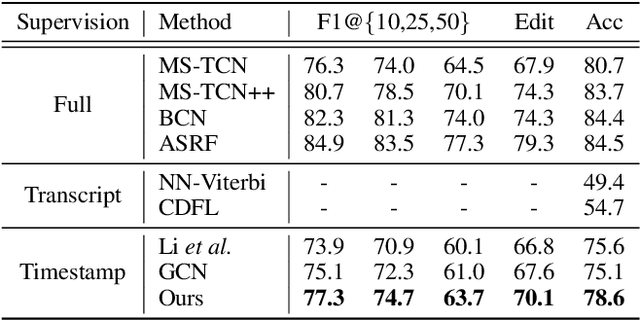
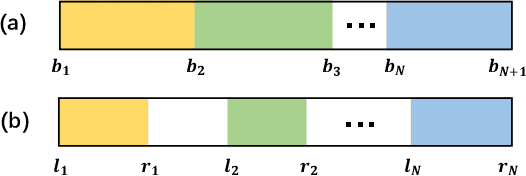
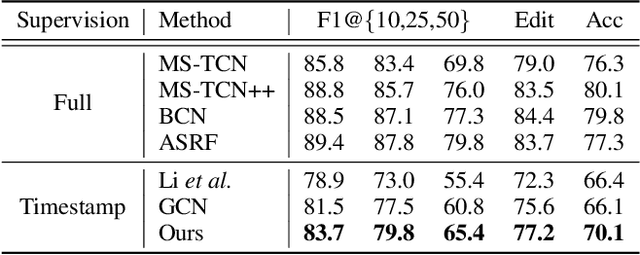
Video action segmentation aims to slice the video into several action segments. Recently, timestamp supervision has received much attention due to lower annotation costs. We find the frames near the boundaries of action segments are in the transition region between two consecutive actions and have unclear semantics, which we call ambiguous intervals. Most existing methods iteratively generate pseudo-labels for all frames in each video to train the segmentation model. However, ambiguous intervals are more likely to be assigned with noisy and incorrect pseudo-labels, which leads to performance degradation. We propose a novel framework to train the model under timestamp supervision including the following two parts. First, pseudo-label ensembling generates pseudo-label sequences with ambiguous intervals, where the frames have no pseudo-labels. Second, iterative clustering iteratively propagates the pseudo-labels to the ambiguous intervals by clustering, and thus updates the pseudo-label sequences to train the model. We further introduce a clustering loss, which encourages the features of frames within the same action segment more compact. Extensive experiments show the effectiveness of our method.