 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimestamp-Supervised Action Segmentation in the Perspective of Clustering
Paper and Code
Dec 22, 2022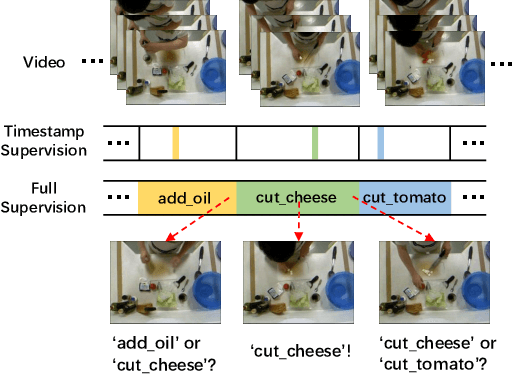
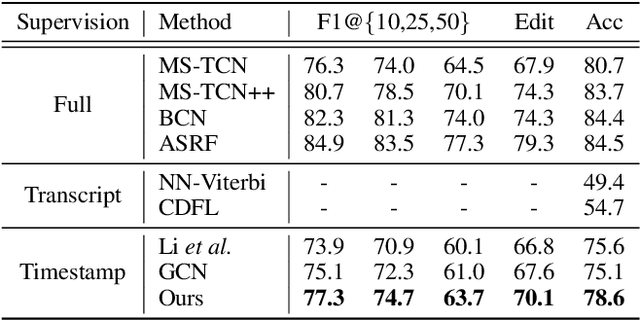
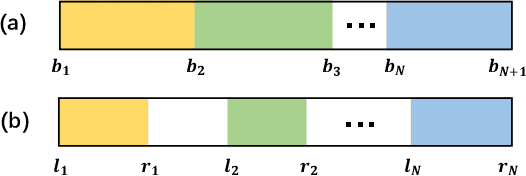
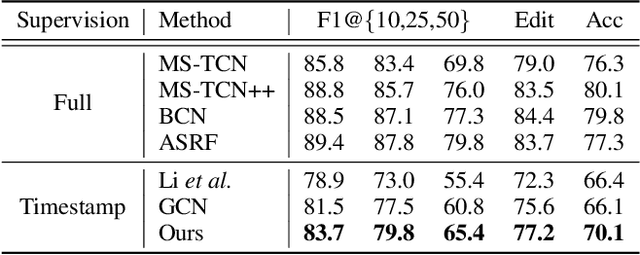
Video action segmentation aims to slice the video into several action segments. Recently, timestamp supervision has received much attention due to lower annotation costs. We find the frames near the boundaries of action segments are in the transition region between two consecutive actions and have unclear semantics, which we call ambiguous intervals. Most existing methods iteratively generate pseudo-labels for all frames in each video to train the segmentation model. However, ambiguous intervals are more likely to be assigned with noisy and incorrect pseudo-labels, which leads to performance degradation. We propose a novel framework to train the model under timestamp supervision including the following two parts. First, pseudo-label ensembling generates pseudo-label sequences with ambiguous intervals, where the frames have no pseudo-labels. Second, iterative clustering iteratively propagates the pseudo-labels to the ambiguous intervals by clustering, and thus updates the pseudo-label sequences to train the model. We further introduce a clustering loss, which encourages the features of frames within the same action segment more compact. Extensive experiments show the effectiveness of our method.