 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Physical Model-Guided Framework for Underwater Image Enhancement and Depth Estimation
Jul 05, 2024


Due to the selective absorption and scattering of light by diverse aquatic media, underwater images usually suffer from various visual degradations. Existing underwater image enhancement (UIE) approaches that combine underwater physical imaging models with neural networks often fail to accurately estimate imaging model parameters such as depth and veiling light, resulting in poor performance in certain scenarios. To address this issue, we propose a physical model-guided framework for jointly training a Deep Degradation Model (DDM) with any advanced UIE model. DDM includes three well-designed sub-networks to accurately estimate various imaging parameters: a veiling light estimation sub-network, a factors estimation sub-network, and a depth estimation sub-network. Based on the estimated parameters and the underwater physical imaging model, we impose physical constraints on the enhancement process by modeling the relationship between underwater images and desired clean images, i.e., outputs of the UIE model. Moreover, while our framework is compatible with any UIE model, we design a simple yet effective fully convolutional UIE model, termed UIEConv. UIEConv utilizes both global and local features for image enhancement through a dual-branch structure. UIEConv trained within our framework achieves remarkable enhancement results across diverse underwater scenes. Furthermore, as a byproduct of UIE, the trained depth estimation sub-network enables accurate underwater scene depth estimation. Extensive experiments conducted in various real underwater imaging scenarios, including deep-sea environments with artificial light sources, validate the effectiveness of our framework and the UIEConv model.
End-To-End Underwater Video Enhancement: Dataset and Model
Mar 18, 2024Underwater video enhancement (UVE) aims to improve the visibility and frame quality of underwater videos, which has significant implications for marine research and exploration. However, existing methods primarily focus on developing image enhancement algorithms to enhance each frame independently. There is a lack of supervised datasets and models specifically tailored for UVE tasks. To fill this gap, we construct the Synthetic Underwater Video Enhancement (SUVE) dataset, comprising 840 diverse underwater-style videos paired with ground-truth reference videos. Based on this dataset, we train a novel underwater video enhancement model, UVENet, which utilizes inter-frame relationships to achieve better enhancement performance. Through extensive experiments on both synthetic and real underwater videos, we demonstrate the effectiveness of our approach. This study represents the first comprehensive exploration of UVE to our knowledge. The code is available at https://anonymous.4open.science/r/UVENet.
UIEDP:Underwater Image Enhancement with Diffusion Prior
Dec 11, 2023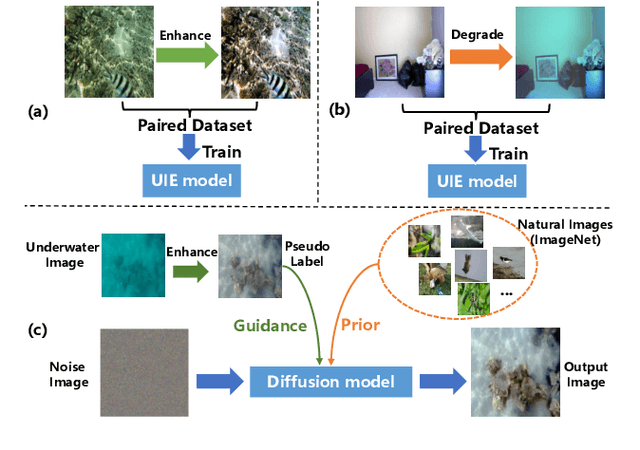
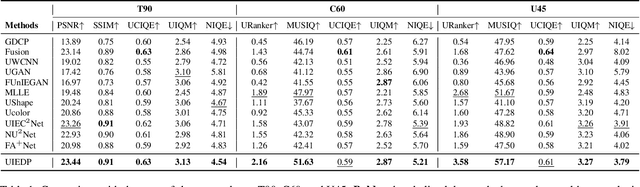
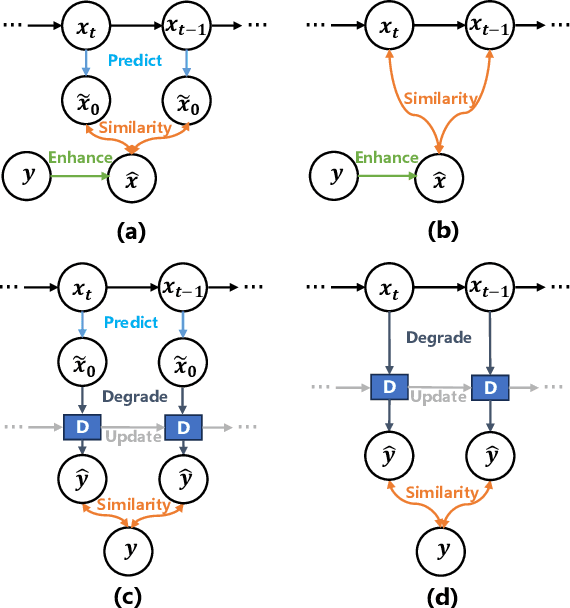

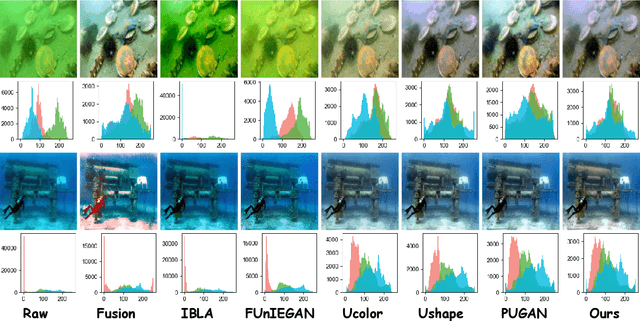
Underwater image enhancement (UIE) aims to generate clear images from low-quality underwater images. Due to the unavailability of clear reference images, researchers often synthesize them to construct paired datasets for training deep models. However, these synthesized images may sometimes lack quality, adversely affecting training outcomes. To address this issue, we propose UIE with Diffusion Prior (UIEDP), a novel framework treating UIE as a posterior distribution sampling process of clear images conditioned on degraded underwater inputs. Specifically, UIEDP combines a pre-trained diffusion model capturing natural image priors with any existing UIE algorithm, leveraging the latter to guide conditional generation. The diffusion prior mitigates the drawbacks of inferior synthetic images, resulting in higher-quality image generation. Extensive experiments have demonstrated that our UIEDP yields significant improvements across various metrics, especially no-reference image quality assessment. And the generated enhanced images also exhibit a more natural appearance.
Timestamp-Supervised Action Segmentation in the Perspective of Clustering
Dec 22, 2022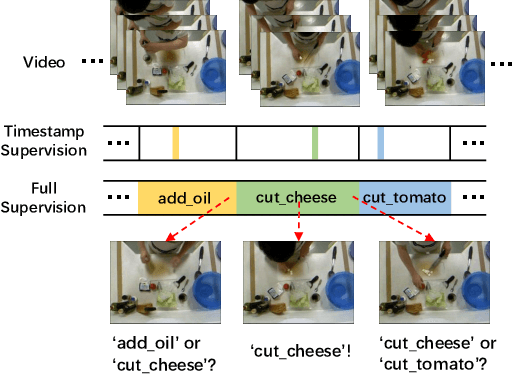
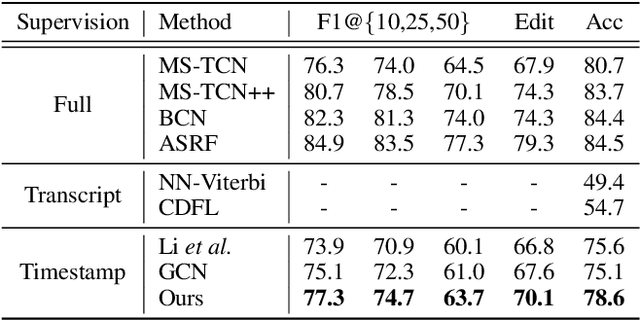
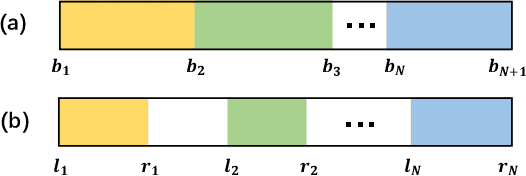
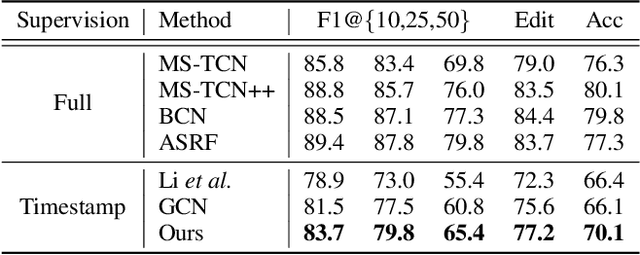
Video action segmentation aims to slice the video into several action segments. Recently, timestamp supervision has received much attention due to lower annotation costs. We find the frames near the boundaries of action segments are in the transition region between two consecutive actions and have unclear semantics, which we call ambiguous intervals. Most existing methods iteratively generate pseudo-labels for all frames in each video to train the segmentation model. However, ambiguous intervals are more likely to be assigned with noisy and incorrect pseudo-labels, which leads to performance degradation. We propose a novel framework to train the model under timestamp supervision including the following two parts. First, pseudo-label ensembling generates pseudo-label sequences with ambiguous intervals, where the frames have no pseudo-labels. Second, iterative clustering iteratively propagates the pseudo-labels to the ambiguous intervals by clustering, and thus updates the pseudo-label sequences to train the model. We further introduce a clustering loss, which encourages the features of frames within the same action segment more compact. Extensive experiments show the effectiveness of our method.