 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient U-Transformer with Boundary-Aware Loss for Action Segmentation
Paper and Code
May 26, 2022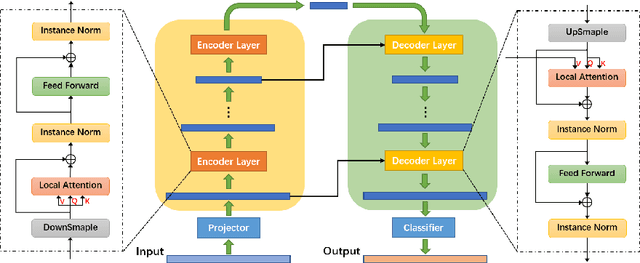
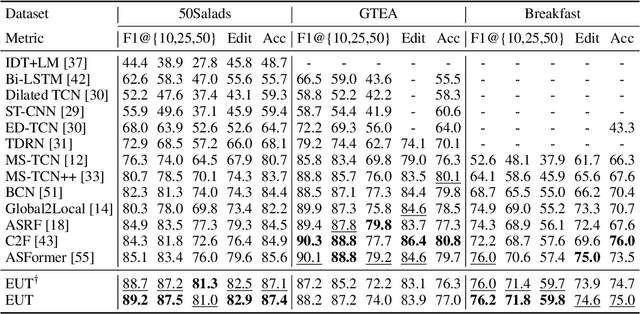
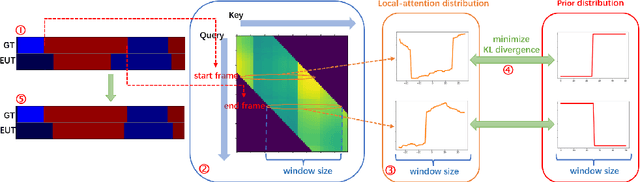
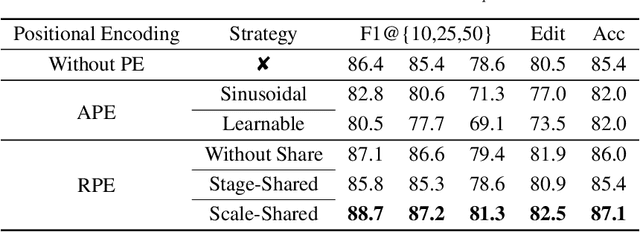
Action classification has made great progress, but segmenting and recognizing actions from long untrimmed videos remains a challenging problem. Most state-of-the-art methods focus on designing temporal convolution-based models, but the limitations on modeling long-term temporal dependencies and inflexibility of temporal convolutions limit the potential of these models. Recently, Transformer-based models with flexible and strong sequence modeling ability have been applied in various tasks. However, the lack of inductive bias and the inefficiency of handling long video sequences limit the application of Transformer in action segmentation. In this paper, we design a pure Transformer-based model without temporal convolutions by incorporating the U-Net architecture. The U-Transformer architecture reduces complexity while introducing an inductive bias that adjacent frames are more likely to belong to the same class, but the introduction of coarse resolutions results in the misclassification of boundaries. We observe that the similarity distribution between a boundary frame and its neighboring frames depends on whether the boundary frame is the start or end of an action segment. Therefore, we further propose a boundary-aware loss based on the distribution of similarity scores between frames from attention modules to enhance the ability to recognize boundaries. Extensive experiments show the effectiveness of our model.