 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Graph Scaffolds for Structural Reasoning in Large Language Models
Jun 01, 2026Graphs have been used to enhance large language models (LLMs) for structured reasoning, mostly as external knowledge sources are provided to models at test time. In this paper, we take a different view: the value of graphs for LLMs lie not only in supplying information, but also in organizing reasoning. Inspired by how humans use graph-structured mind maps to organize branching and converging thoughts, we ask whether graphs can serve as an internal form of reasoning assistance. We study this question on multi-hop question answering tasks, where teacher-provided reasoning traces are rewritten as graph mind maps and used to guide a student model. Our experiments reveal a clear modality gap. When graph structures are flattened into text, their benefits become limited once direct answer hints are removed. Under this abstract guidance setting, both reasoning efficiency and answer quality degrade substantially. In contrast, visual graph guidance remains effective without direct answer clues, and its advantage persists after supervised fine-tuning and KL-based distillation. The above findings support the claim that graphs should be studied not only as external knowledge structures for LLMs, but also as visual scaffolds for organizing reasoning.
Learning Agent-Compatible Context Management for Long-Horizon Tasks
May 29, 2026LLM agents increasingly face long-horizon tasks such as web search and deep research in real-world applications, where accumulated context can cause long-context degradation and reasoning failures. Prior work mitigates this through context management with agent-side context control or fixed strategies such as summarization, which require training the agent itself for adaptation - making it impractical for closed-source agents and ignoring that different agents may require different strategies. We introduce Adaptive Context Management (AdaCoM), which trains an external LLM to manage the context of a frozen agent through flexible modification actions and end-to-end reinforcement learning. Across diverse agents on web search and deep research benchmarks, AdaCoM substantially improves performance by preserving task constraints and progress while pruning stale content. The learned strategies reveal a Fidelity-Reliability Trade-off: agents with higher vanilla ReAct performance benefit from higher-fidelity context preservation, whereas lower-performing agents require more aggressive compression to stay within a reliable reasoning regime. Transfer experiments show that AdaCoM generalizes most effectively across agents with similar capability (measured by vanilla ReAct performance), suggesting a practical path toward reusable context managers for agent systems.
Position: The Turing-Completeness of Real-World Autoregressive Transformers Relies Heavily on Context Management
May 19, 2026Many works make the eye-catching claim that Transformers are Turing-complete. However, the literature often conflates two distinct settings: (i) a fixed Transformer system setting, in which a fixed autoregressive Transformer is coupled with a fixed context-management method to process inputs of different lengths step by step, and (ii) a scaling-family setting, in which a family of different models (with increasing context-window length or numerical precision) is used to handle different input lengths. Existing proofs of Transformer Turing-completeness are frequently established in setting (ii), whereas real-world LLM deployment and the standard notion of Turing-completeness correspond more naturally to setting (i). In this paper, we first formalize the fixed-system setting, thereby providing a concrete characterization of how real-world LLMs operate. We then argue that results proved in the scaling-family setting provide theoretically meaningful resource bounds but do not establish Turing-completeness, thereby clarifying a common misinterpretation of existing results. Finally, we show that different context-management methods can yield sharply different computational power, and we advocate the position that context management is a central component that critically determines the computational power of real-world autoregressive Transformers.
AbFlow : End-to-end Paratope-Centric Antibody Design by Interaction Enhanced Flow Matching
Feb 06, 2026Antigen-antibody binding is a critical process in the immune response. Although recent progress has advanced antibody design, current methods lack a generative framework for end-to-end modeling of full-atom antibody structures and struggle to fully exploit antigen-specific geometric information for optimizing local binding interfaces and global structures. To overcome these limitations, we introduce AbFlow, a flow-matching framework that leverages optimal transport to design full-atom antibodies end-to-end. AbFlow incorporates an extended velocity field network featuring an equivariant Surface Multi-channel Encoder, which uses surface-level antigen interaction data to refine the antibody structure, particularly the CDR-H3 region. Extensive experiments in paratoep-centric antibody design, multi-CDRs and full-atom antibody design, binding affinity optimization, and complex structure prediction show that AbFlow produces superior antigen-antibody complexes, especially at the contact interface, and markedly improves the binding affinity of generated antibodies.
Fused Gromov-Wasserstein Contrastive Learning for Effective Enzyme-Reaction Screening
Dec 09, 2025Enzymes are crucial catalysts that enable a wide range of biochemical reactions. Efficiently identifying specific enzymes from vast protein libraries is essential for advancing biocatalysis. Traditional computational methods for enzyme screening and retrieval are time-consuming and resource-intensive. Recently, deep learning approaches have shown promise. However, these methods focus solely on the interaction between enzymes and reactions, overlooking the inherent hierarchical relationships within each domain. To address these limitations, we introduce FGW-CLIP, a novel contrastive learning framework based on optimizing the fused Gromov-Wasserstein distance. FGW-CLIP incorporates multiple alignments, including inter-domain alignment between reactions and enzymes and intra-domain alignment within enzymes and reactions. By introducing a tailored regularization term, our method minimizes the Gromov-Wasserstein distance between enzyme and reaction spaces, which enhances information integration across these domains. Extensive evaluations demonstrate the superiority of FGW-CLIP in challenging enzyme-reaction tasks. On the widely-used EnzymeMap benchmark, FGW-CLIP achieves state-of-the-art performance in enzyme virtual screening, as measured by BEDROC and EF metrics. Moreover, FGW-CLIP consistently outperforms across all three splits of ReactZyme, the largest enzyme-reaction benchmark, demonstrating robust generalization to novel enzymes and reactions. These results position FGW-CLIP as a promising framework for enzyme discovery in complex biochemical settings, with strong adaptability across diverse screening scenarios.
Future Link Prediction Without Memory or Aggregation
May 26, 2025Future link prediction on temporal graphs is a fundamental task with wide applicability in real-world dynamic systems. These scenarios often involve both recurring (seen) and novel (unseen) interactions, requiring models to generalize effectively across both types of edges. However, existing methods typically rely on complex memory and aggregation modules, yet struggle to handle unseen edges. In this paper, we revisit the architecture of existing temporal graph models and identify two essential but overlooked modeling requirements for future link prediction: representing nodes with unique identifiers and performing target-aware matching between source and destination nodes. To this end, we propose Cross-Attention based Future Link Predictor on Temporal Graphs (CRAFT), a simple yet effective architecture that discards memory and aggregation modules and instead builds on two components: learnable node embeddings and cross-attention between the destination and the source's recent interactions. This design provides strong expressive power and enables target-aware modeling of the compatibility between candidate destinations and the source's interaction patterns. Extensive experiments on diverse datasets demonstrate that CRAFT consistently achieves superior performance with high efficiency, making it well-suited for large-scale real-world applications.
Rethinking Link Prediction for Directed Graphs
Feb 08, 2025



Link prediction for directed graphs is a crucial task with diverse real-world applications. Recent advances in embedding methods and Graph Neural Networks (GNNs) have shown promising improvements. However, these methods often lack a thorough analysis of embedding expressiveness and suffer from ineffective benchmarks for a fair evaluation. In this paper, we propose a unified framework to assess the expressiveness of existing methods, highlighting the impact of dual embeddings and decoder design on performance. To address limitations in current experimental setups, we introduce DirLinkBench, a robust new benchmark with comprehensive coverage and standardized evaluation. The results show that current methods struggle to achieve strong performance on the new benchmark, while DiGAE outperforms others overall. We further revisit DiGAE theoretically, showing its graph convolution aligns with GCN on an undirected bipartite graph. Inspired by these insights, we propose a novel spectral directed graph auto-encoder SDGAE that achieves SOTA results on DirLinkBench. Finally, we analyze key factors influencing directed link prediction and highlight open challenges.
TGB-Seq Benchmark: Challenging Temporal GNNs with Complex Sequential Dynamics
Feb 05, 2025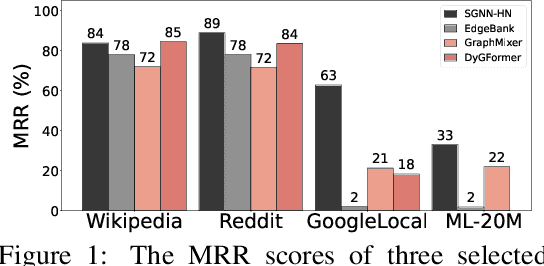
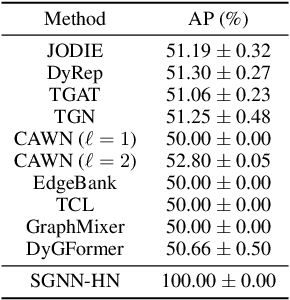
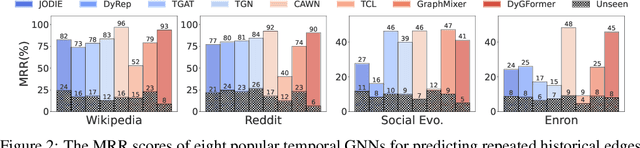

Future link prediction is a fundamental challenge in various real-world dynamic systems. To address this, numerous temporal graph neural networks (temporal GNNs) and benchmark datasets have been developed. However, these datasets often feature excessive repeated edges and lack complex sequential dynamics, a key characteristic inherent in many real-world applications such as recommender systems and ``Who-To-Follow'' on social networks. This oversight has led existing methods to inadvertently downplay the importance of learning sequential dynamics, focusing primarily on predicting repeated edges. In this study, we demonstrate that existing methods, such as GraphMixer and DyGFormer, are inherently incapable of learning simple sequential dynamics, such as ``a user who has followed OpenAI and Anthropic is more likely to follow AI at Meta next.'' Motivated by this issue, we introduce the Temporal Graph Benchmark with Sequential Dynamics (TGB-Seq), a new benchmark carefully curated to minimize repeated edges, challenging models to learn sequential dynamics and generalize to unseen edges. TGB-Seq comprises large real-world datasets spanning diverse domains, including e-commerce interactions, movie ratings, business reviews, social networks, citation networks and web link networks. Benchmarking experiments reveal that current methods usually suffer significant performance degradation and incur substantial training costs on TGB-Seq, posing new challenges and opportunities for future research. TGB-Seq datasets, leaderboards, and example codes are available at https://tgb-seq.github.io/.
Large-Scale Spectral Graph Neural Networks via Laplacian Sparsification: Technical Report
Jan 08, 2025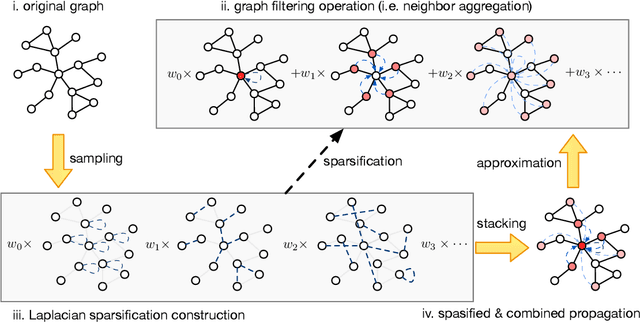
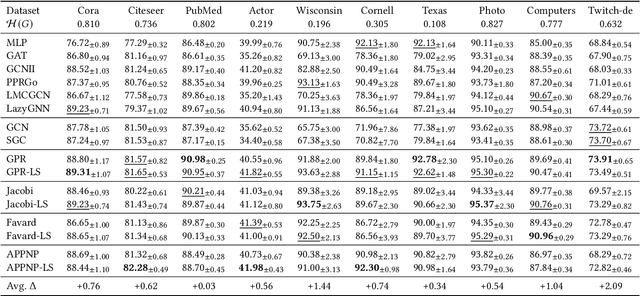
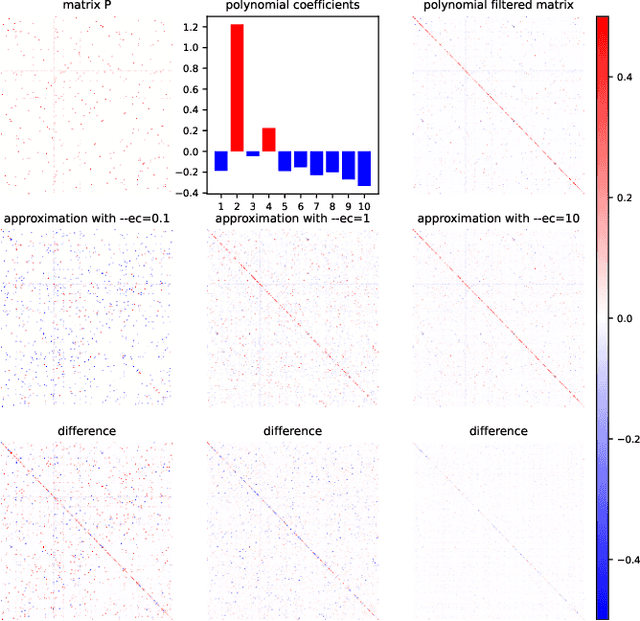
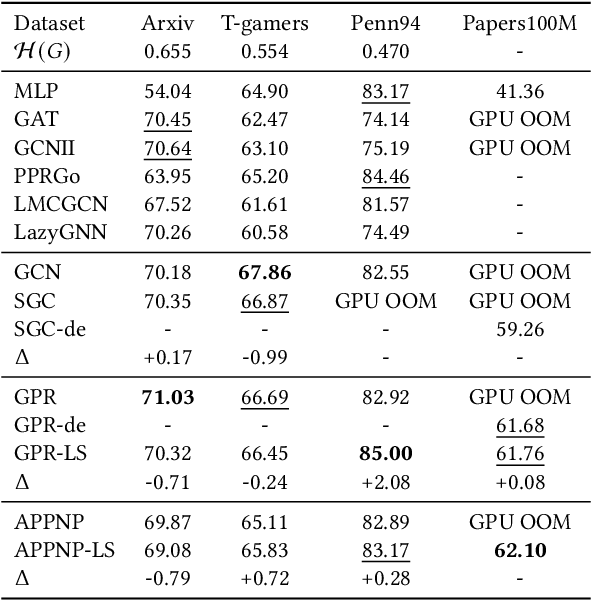
Graph Neural Networks (GNNs) play a pivotal role in graph-based tasks for their proficiency in representation learning. Among the various GNN methods, spectral GNNs employing polynomial filters have shown promising performance on tasks involving both homophilous and heterophilous graph structures. However, The scalability of spectral GNNs on large graphs is limited because they learn the polynomial coefficients through multiple forward propagation executions during forward propagation. Existing works have attempted to scale up spectral GNNs by eliminating the linear layers on the input node features, a change that can disrupt end-to-end training, potentially impact performance, and become impractical with high-dimensional input features. To address the above challenges, we propose "Spectral Graph Neural Networks with Laplacian Sparsification (SGNN-LS)", a novel graph spectral sparsification method to approximate the propagation patterns of spectral GNNs. We prove that our proposed method generates Laplacian sparsifiers that can approximate both fixed and learnable polynomial filters with theoretical guarantees. Our method allows the application of linear layers on the input node features, enabling end-to-end training as well as the handling of raw text features. We conduct an extensive experimental analysis on datasets spanning various graph scales and properties to demonstrate the superior efficiency and effectiveness of our method. The results show that our method yields superior results in comparison with the corresponding approximated base models, especially on dataset Ogbn-papers100M(111M nodes, 1.6B edges) and MAG-scholar-C (2.8M features).
SRAP-Agent: Simulating and Optimizing Scarce Resource Allocation Policy with LLM-based Agent
Oct 18, 2024



Public scarce resource allocation plays a crucial role in economics as it directly influences the efficiency and equity in society. Traditional studies including theoretical model-based, empirical study-based and simulation-based methods encounter limitations due to the idealized assumption of complete information and individual rationality, as well as constraints posed by limited available data. In this work, we propose an innovative framework, SRAP-Agent (Simulating and Optimizing Scarce Resource Allocation Policy with LLM-based Agent), which integrates Large Language Models (LLMs) into economic simulations, aiming to bridge the gap between theoretical models and real-world dynamics. Using public housing allocation scenarios as a case study, we conduct extensive policy simulation experiments to verify the feasibility and effectiveness of the SRAP-Agent and employ the Policy Optimization Algorithm with certain optimization objectives. The source code can be found in https://github.com/jijiarui-cather/SRAPAgent_Framework