 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR$^3$L: Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification
Jan 07, 2026Reinforcement learning drives recent advances in LLM reasoning and agentic capabilities, yet current approaches struggle with both exploration and exploitation. Exploration suffers from low success rates on difficult tasks and high costs of repeated rollouts from scratch. Exploitation suffers from coarse credit assignment and training instability: Trajectory-level rewards penalize valid prefixes for later errors, and failure-dominated groups overwhelm the few positive signals, leaving optimization without constructive direction. To this end, we propose R$^3$L, Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification. To synthesize high-quality trajectories, R$^3$L shifts from stochastic sampling to active synthesis via reflect-then-retry, leveraging language feedback to diagnose errors, transform failed attempts into successful ones, and reduce rollout costs by restarting from identified failure points. With errors diagnosed and localized, Pivotal Credit Assignment updates only the diverging suffix where contrastive signals exist, excluding the shared prefix from gradient update. Since failures dominate on difficult tasks and reflect-then-retry produces off-policy data, risking training instability, Positive Amplification upweights successful trajectories to ensure positive signals guide the optimization process. Experiments on agentic and reasoning tasks demonstrate 5\% to 52\% relative improvements over baselines while maintaining training stability. Our code is released at https://github.com/shiweijiezero/R3L.
Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models
May 23, 2025Trinity-RFT is a general-purpose, flexible and scalable framework designed for reinforcement fine-tuning (RFT) of large language models. It is built with a decoupled design, consisting of (1) an RFT-core that unifies and generalizes synchronous/asynchronous, on-policy/off-policy, and online/offline modes of RFT, (2) seamless integration for agent-environment interaction with high efficiency and robustness, and (3) systematic data pipelines optimized for RFT. Trinity-RFT can be easily adapted for diverse application scenarios, and serves as a unified platform for exploring advanced reinforcement learning paradigms. This technical report outlines the vision, features, design and implementations of Trinity-RFT, accompanied by extensive examples demonstrating the utility and user-friendliness of the proposed framework.
A Simple and Provable Scaling Law for the Test-Time Compute of Large Language Models
Nov 29, 2024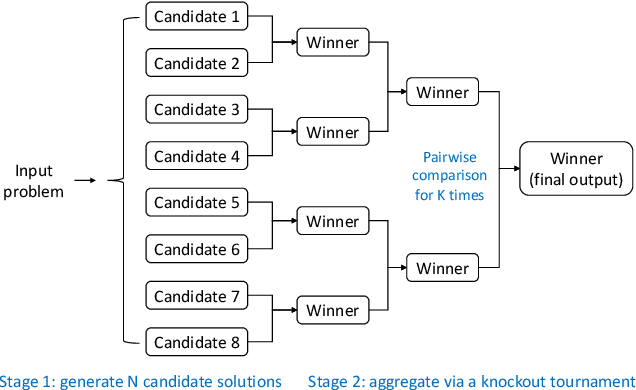



We propose a general two-stage algorithm that enjoys a provable scaling law for the test-time compute of large language models (LLMs). Given an input problem, the proposed algorithm first generates $N$ candidate solutions, and then chooses the best one via a multiple-round knockout tournament where each pair of candidates are compared for $K$ times and only the winners move on to the next round. In a minimalistic implementation, both stages can be executed with a black-box LLM alone and nothing else (e.g., no external verifier or reward model), and a total of $N \times (K + 1)$ highly parallelizable LLM calls are needed for solving an input problem. Assuming that a generated candidate solution is correct with probability $p_{\text{gen}} > 0$ and a comparison between a pair of correct and incorrect solutions identifies the right winner with probability $p_{\text{comp}} > 0.5$ (i.e., better than a random guess), we prove theoretically that the failure probability of the proposed algorithm decays to zero exponentially with respect to $N$ and $K$: $$\mathbb{P}(\text{final output is incorrect}) \le (1 - p_{\text{gen}})^N + \lceil \log_2 N \rceil e^{-2 K (p_{\text{comp}} - 0.5)^2}.$$ Our empirical results with the challenging MMLU-Pro benchmark validate the technical assumptions, as well as the efficacy of the proposed algorithm and the gains from scaling up its test-time compute.
Dynamic and Textual Graph Generation Via Large-Scale LLM-based Agent Simulation
Oct 13, 2024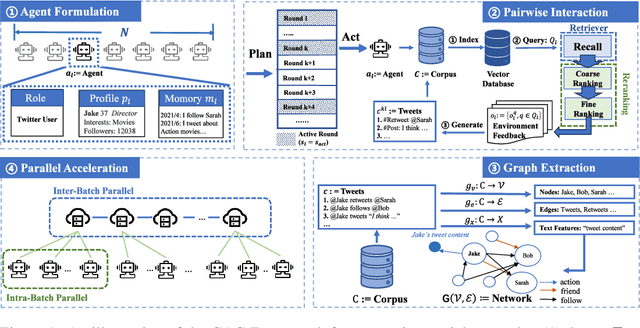
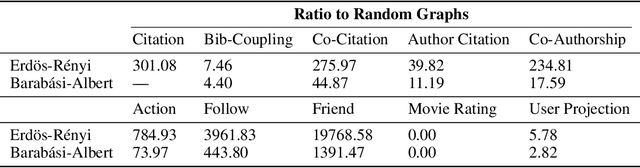
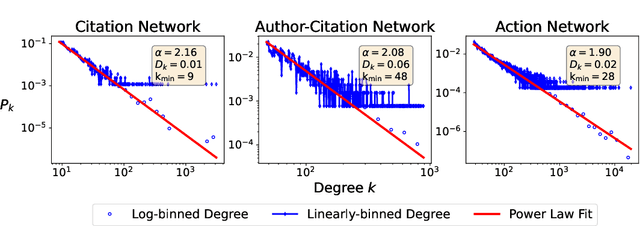
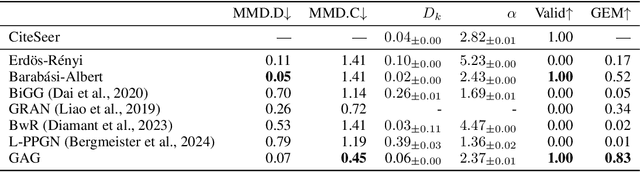
Graph generation is a fundamental task that has been extensively studied in social, technological, and scientific analysis. For modeling the dynamic graph evolution process, traditional rule-based methods struggle to capture community structures within graphs, while deep learning methods only focus on fitting training graphs. This limits existing graph generators to producing graphs that adhere to predefined rules or closely resemble training datasets, achieving poor performance in dynamic graph generation. Given that graphs are abstract representations arising from pairwise interactions in human activities, a realistic simulation of human-wise interaction could provide deeper insights into the graph evolution mechanism. With the increasing recognition of large language models (LLMs) in simulating human behavior, we introduce GraphAgent-Generator (GAG), a novel simulation-based framework for dynamic graph generation. Without training or fine-tuning process of LLM, our framework effectively replicates seven macro-level structural characteristics in established network science theories while surpassing existing baselines in graph expansion tasks by 31\% on specific evaluation metrics. Through node classification task, we validate GAG effectively preserves characteristics of real-world network for node-wise textual features in generated text-rich graph. Furthermore, by incorporating parallel acceleration, GAG supports generating graphs with up to nearly 100,000 nodes or 10 million edges through large-scale LLM-based agent simulation, with a minimum speed-up of 90.4\%. The source code is available at https://anonymous.4open.science/r/GraphAgent-2206.
GenSim: A General Social Simulation Platform with Large Language Model based Agents
Oct 06, 2024

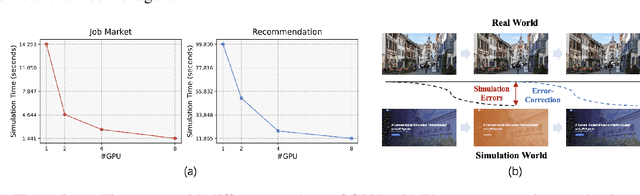

With the rapid advancement of large language models (LLMs), recent years have witnessed many promising studies on leveraging LLM-based agents to simulate human social behavior. While prior work has demonstrated significant potential across various domains, much of it has focused on specific scenarios involving a limited number of agents and has lacked the ability to adapt when errors occur during simulation. To overcome these limitations, we propose a novel LLM-agent-based simulation platform called \textit{GenSim}, which: (1) \textbf{Abstracts a set of general functions} to simplify the simulation of customized social scenarios; (2) \textbf{Supports one hundred thousand agents} to better simulate large-scale populations in real-world contexts; (3) \textbf{Incorporates error-correction mechanisms} to ensure more reliable and long-term simulations. To evaluate our platform, we assess both the efficiency of large-scale agent simulations and the effectiveness of the error-correction mechanisms. To our knowledge, GenSim represents an initial step toward a general, large-scale, and correctable social simulation platform based on LLM agents, promising to further advance the field of social science.
Very Large-Scale Multi-Agent Simulation in AgentScope
Jul 25, 2024Recent advances in large language models (LLMs) have opened new avenues for applying multi-agent systems in very large-scale simulations. However, there remain several challenges when conducting multi-agent simulations with existing platforms, such as limited scalability and low efficiency, unsatisfied agent diversity, and effort-intensive management processes. To address these challenges, we develop several new features and components for AgentScope, a user-friendly multi-agent platform, enhancing its convenience and flexibility for supporting very large-scale multi-agent simulations. Specifically, we propose an actor-based distributed mechanism as the underlying technological infrastructure towards great scalability and high efficiency, and provide flexible environment support for simulating various real-world scenarios, which enables parallel execution of multiple agents, centralized workflow orchestration, and both inter-agent and agent-environment interactions among agents. Moreover, we integrate an easy-to-use configurable tool and an automatic background generation pipeline in AgentScope, simplifying the process of creating agents with diverse yet detailed background settings. Last but not least, we provide a web-based interface for conveniently monitoring and managing a large number of agents that might deploy across multiple devices. We conduct a comprehensive simulation to demonstrate the effectiveness of the proposed enhancements in AgentScope, and provide detailed observations and discussions to highlight the great potential of applying multi-agent systems in large-scale simulations. The source code is released on GitHub at https://github.com/modelscope/agentscope to inspire further research and development in large-scale multi-agent simulations.
AgentScope: A Flexible yet Robust Multi-Agent Platform
Feb 21, 2024With the rapid advancement of Large Language Models (LLMs), significant progress has been made in multi-agent applications. However, the complexities in coordinating agents' cooperation and LLMs' erratic performance pose notable challenges in developing robust and efficient multi-agent applications. To tackle these challenges, we propose AgentScope, a developer-centric multi-agent platform with message exchange as its core communication mechanism. Together with abundant syntactic tools, built-in resources, and user-friendly interactions, our communication mechanism significantly reduces the barriers to both development and understanding. Towards robust and flexible multi-agent application, AgentScope provides both built-in and customizable fault tolerance mechanisms while it is also armed with system-level supports for multi-modal data generation, storage and transmission. Additionally, we design an actor-based distribution framework, enabling easy conversion between local and distributed deployments and automatic parallel optimization without extra effort. With these features, AgentScope empowers developers to build applications that fully realize the potential of intelligent agents. We have released AgentScope at https://github.com/modelscope/agentscope, and hope AgentScope invites wider participation and innovation in this fast-moving field.
EE-Tuning: An Economical yet Scalable Solution for Tuning Early-Exit Large Language Models
Feb 01, 2024This work introduces EE-Tuning, a lightweight and economical solution to training/tuning early-exit large language models (LLMs). In contrast to the common approach of full-parameter pre-training, EE-Tuning augments any pre-trained (and possibly fine-tuned) standard LLM with additional early-exit layers that are tuned in a parameter-efficient manner, which requires significantly less computational resources and training data. Our implementation of EE-Tuning achieves outstanding training efficiency via extensive performance optimizations, as well as scalability due to its full compatibility with 3D parallelism. Results of systematic experiments validate the efficacy of EE-Tuning, confirming that effective early-exit LLM inference can be achieved with a limited training budget. In hope of making early-exit LLMs accessible to the community, we release the source code of our implementation of EE-Tuning at https://github.com/pan-x-c/EE-LLM.
EE-LLM: Large-Scale Training and Inference of Early-Exit Large Language Models with 3D Parallelism
Dec 08, 2023

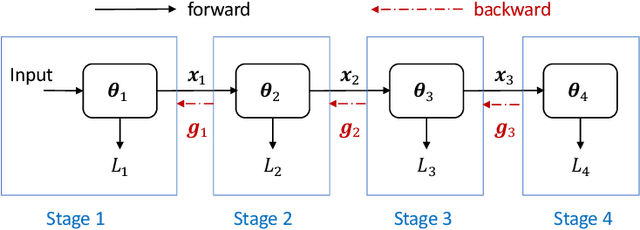

We present EE-LLM, a framework for large-scale training and inference of early-exit large language models (LLMs). While recent works have shown preliminary evidence for the efficacy of early exiting in accelerating LLM inference, EE-LLM makes a foundational step towards scaling up early-exit LLMs by supporting their training and inference with massive 3D parallelism. Built upon Megatron-LM, EE-LLM implements a variety of algorithmic innovations and performance optimizations tailored to early exiting, including a lightweight method that facilitates backpropagation for the early-exit training objective with pipeline parallelism, techniques of leveraging idle resources in the original pipeline schedule for computation related to early-exit layers, and two approaches of early-exit inference that are compatible with KV caching for autoregressive generation. Our analytical and empirical study shows that EE-LLM achieves great training efficiency with negligible computational overhead compared to standard LLM training, as well as outstanding inference speedup without compromising output quality. To facilitate further research and adoption, we release EE-LLM at https://github.com/pan-x-c/EE-LLM.
Data-Juicer: A One-Stop Data Processing System for Large Language Models
Sep 05, 2023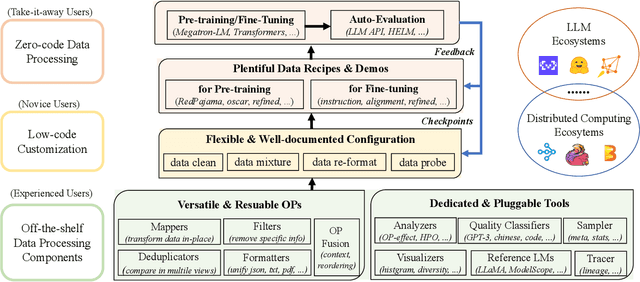
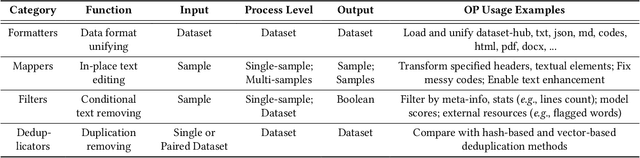
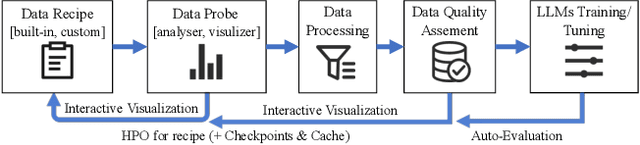
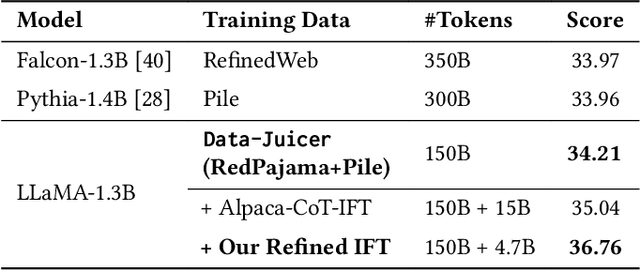
The immense evolution in Large Language Models (LLMs) has underscored the importance of massive, diverse, and high-quality data. Despite this, existing open-source tools for LLM data processing remain limited and mostly tailored to specific datasets, with an emphasis on the reproducibility of released data over adaptability and usability, inhibiting potential applications. In response, we propose a one-stop, powerful yet flexible and user-friendly LLM data processing system named Data-Juicer. Our system offers over 50 built-in versatile operators and pluggable tools, which synergize modularity, composability, and extensibility dedicated to diverse LLM data processing needs. By incorporating visualized and automatic evaluation capabilities, Data-Juicer enables a timely feedback loop to accelerate data processing and gain data insights. To enhance usability, Data-Juicer provides out-of-the-box components for users with various backgrounds, and fruitful data recipes for LLM pre-training and post-tuning usages. Further, we employ multi-facet system optimization and seamlessly integrate Data-Juicer with both LLM and distributed computing ecosystems, to enable efficient and scalable data processing. Empirical validation of the generated data recipes reveals considerable improvements in LLaMA performance for various pre-training and post-tuning cases, demonstrating up to 7.45% relative improvement of averaged score across 16 LLM benchmarks and 16.25% higher win rate using pair-wise GPT-4 evaluation. The system's efficiency and scalability are also validated, supported by up to 88.7% reduction in single-machine processing time, 77.1% and 73.1% less memory and CPU usage respectively, and 7.91x processing acceleration when utilizing distributed computing ecosystems. Our system, data recipes, and multiple tutorial demos are released, calling for broader research centered on LLM data.