 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Juicer Sandbox: A Comprehensive Suite for Multimodal Data-Model Co-development
Jul 16, 2024



The emergence of large-scale multi-modal generative models has drastically advanced artificial intelligence, introducing unprecedented levels of performance and functionality. However, optimizing these models remains challenging due to historically isolated paths of model-centric and data-centric developments, leading to suboptimal outcomes and inefficient resource utilization. In response, we present a novel sandbox suite tailored for integrated data-model co-development. This sandbox provides a comprehensive experimental platform, enabling rapid iteration and insight-driven refinement of both data and models. Our proposed "Probe-Analyze-Refine" workflow, validated through applications on state-of-the-art LLaVA-like and DiT based models, yields significant performance boosts, such as topping the VBench leaderboard. We also uncover fruitful insights gleaned from exhaustive benchmarks, shedding light on the critical interplay between data quality, diversity, and model behavior. With the hope of fostering deeper understanding and future progress in multi-modal data and generative modeling, our codes, datasets, and models are maintained and accessible at https://github.com/modelscope/data-juicer/blob/main/docs/Sandbox.md.
Data Mixing Made Efficient: A Bivariate Scaling Law for Language Model Pretraining
May 23, 2024Large language models exhibit exceptional generalization capabilities, primarily attributed to the utilization of diversely sourced data. However, conventional practices in integrating this diverse data heavily rely on heuristic schemes, lacking theoretical guidance. This research tackles these limitations by investigating strategies based on low-cost proxies for data mixtures, with the aim of streamlining data curation to enhance training efficiency. Specifically, we propose a unified scaling law, termed BiMix, which accurately models the bivariate scaling behaviors of both data quantity and mixing proportions. We conduct systematic experiments and provide empirical evidence for the predictive power and fundamental principles of BiMix. Notably, our findings reveal that entropy-driven training-free data mixtures can achieve comparable or even better performance than more resource-intensive methods. We hope that our quantitative insights can shed light on further judicious research and development in cost-effective language modeling.
Data-Juicer: A One-Stop Data Processing System for Large Language Models
Sep 05, 2023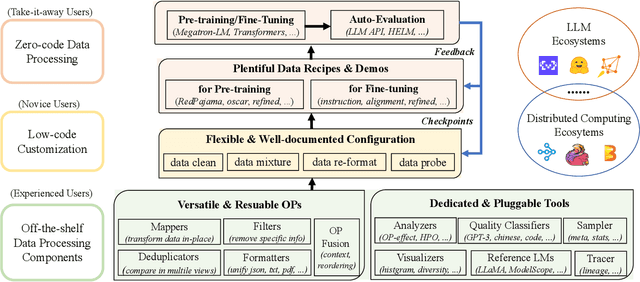
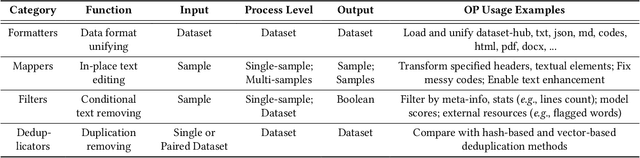
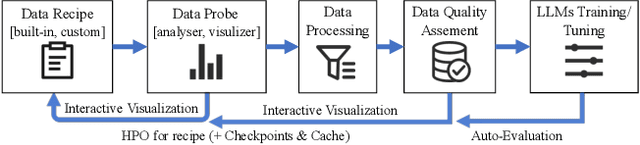
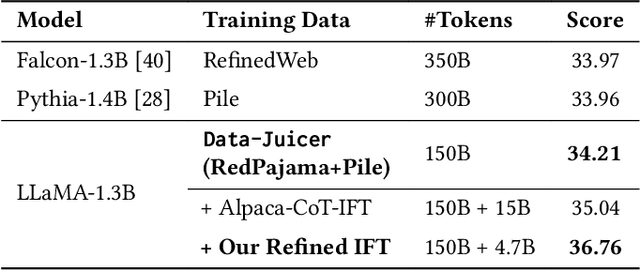
The immense evolution in Large Language Models (LLMs) has underscored the importance of massive, diverse, and high-quality data. Despite this, existing open-source tools for LLM data processing remain limited and mostly tailored to specific datasets, with an emphasis on the reproducibility of released data over adaptability and usability, inhibiting potential applications. In response, we propose a one-stop, powerful yet flexible and user-friendly LLM data processing system named Data-Juicer. Our system offers over 50 built-in versatile operators and pluggable tools, which synergize modularity, composability, and extensibility dedicated to diverse LLM data processing needs. By incorporating visualized and automatic evaluation capabilities, Data-Juicer enables a timely feedback loop to accelerate data processing and gain data insights. To enhance usability, Data-Juicer provides out-of-the-box components for users with various backgrounds, and fruitful data recipes for LLM pre-training and post-tuning usages. Further, we employ multi-facet system optimization and seamlessly integrate Data-Juicer with both LLM and distributed computing ecosystems, to enable efficient and scalable data processing. Empirical validation of the generated data recipes reveals considerable improvements in LLaMA performance for various pre-training and post-tuning cases, demonstrating up to 7.45% relative improvement of averaged score across 16 LLM benchmarks and 16.25% higher win rate using pair-wise GPT-4 evaluation. The system's efficiency and scalability are also validated, supported by up to 88.7% reduction in single-machine processing time, 77.1% and 73.1% less memory and CPU usage respectively, and 7.91x processing acceleration when utilizing distributed computing ecosystems. Our system, data recipes, and multiple tutorial demos are released, calling for broader research centered on LLM data.
OICSR: Out-In-Channel Sparsity Regularization for Compact Deep Neural Networks
Jun 06, 2019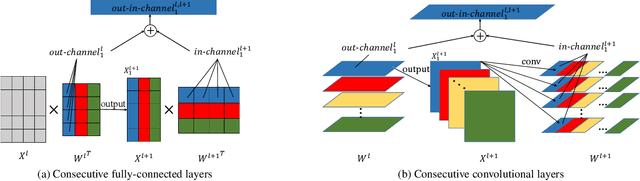
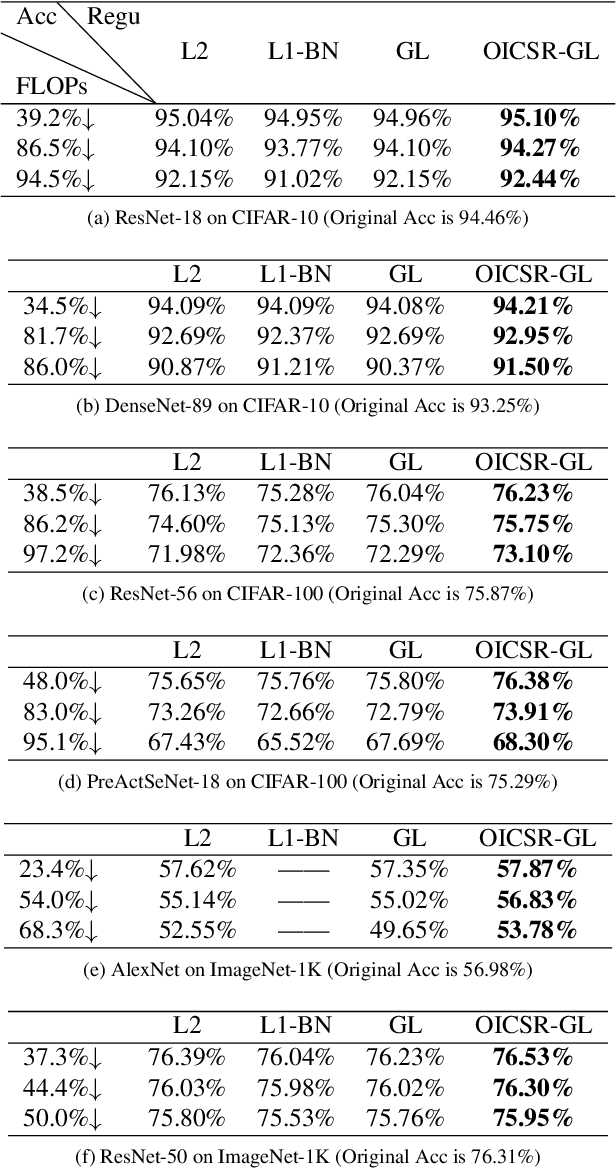

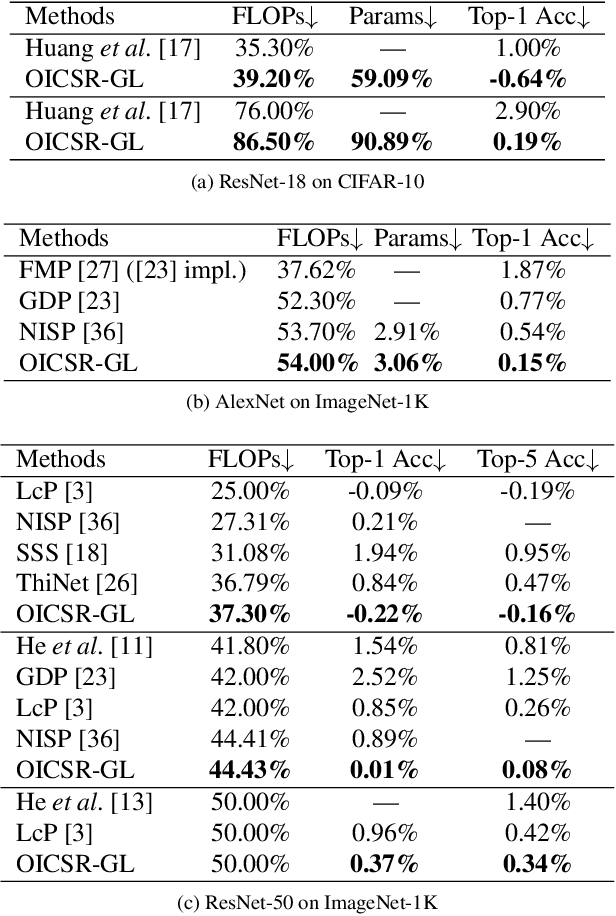
Channel pruning can significantly accelerate and compress deep neural networks. Many channel pruning works utilize structured sparsity regularization to zero out all the weights in some channels and automatically obtain structure-sparse network in training stage. However, these methods apply structured sparsity regularization on each layer separately where the correlations between consecutive layers are omitted. In this paper, we first combine one out-channel in current layer and the corresponding in-channel in next layer as a regularization group, namely out-in-channel. Our proposed Out-In-Channel Sparsity Regularization (OICSR) considers correlations between successive layers to further retain predictive power of the compact network. Training with OICSR thoroughly transfers discriminative features into a fraction of out-in-channels. Correspondingly, OICSR measures channel importance based on statistics computed from two consecutive layers, not individual layer. Finally, a global greedy pruning algorithm is designed to remove redundant out-in-channels in an iterative way. Our method is comprehensively evaluated with various CNN architectures including CifarNet, AlexNet, ResNet, DenseNet and PreActSeNet on CIFAR-10, CIFAR-100 and ImageNet-1K datasets. Notably, on ImageNet-1K, we reduce 37.2% FLOPs on ResNet-50 while outperforming the original model by 0.22% top-1 accuracy.