 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Juicer: A One-Stop Data Processing System for Large Language Models
Paper and Code
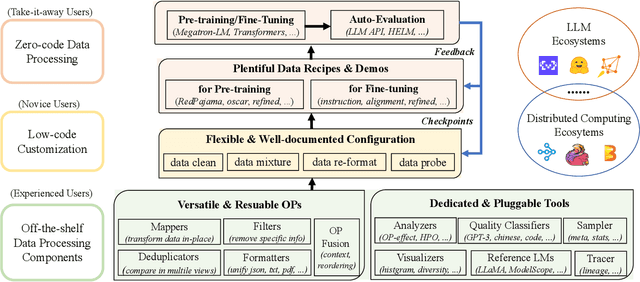
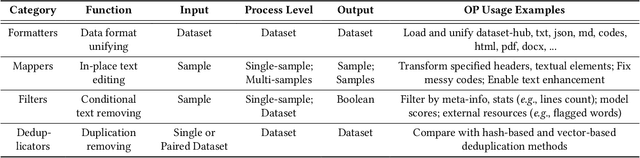
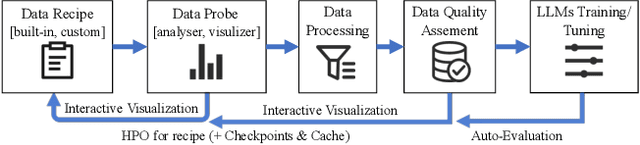
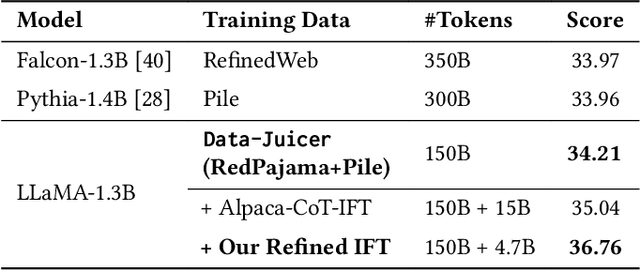
The immense evolution in Large Language Models (LLMs) has underscored the importance of massive, diverse, and high-quality data. Despite this, existing open-source tools for LLM data processing remain limited and mostly tailored to specific datasets, with an emphasis on the reproducibility of released data over adaptability and usability, inhibiting potential applications. In response, we propose a one-stop, powerful yet flexible and user-friendly LLM data processing system named Data-Juicer. Our system offers over 50 built-in versatile operators and pluggable tools, which synergize modularity, composability, and extensibility dedicated to diverse LLM data processing needs. By incorporating visualized and automatic evaluation capabilities, Data-Juicer enables a timely feedback loop to accelerate data processing and gain data insights. To enhance usability, Data-Juicer provides out-of-the-box components for users with various backgrounds, and fruitful data recipes for LLM pre-training and post-tuning usages. Further, we employ multi-facet system optimization and seamlessly integrate Data-Juicer with both LLM and distributed computing ecosystems, to enable efficient and scalable data processing. Empirical validation of the generated data recipes reveals considerable improvements in LLaMA performance for various pre-training and post-tuning cases, demonstrating up to 7.45% relative improvement of averaged score across 16 LLM benchmarks and 16.25% higher win rate using pair-wise GPT-4 evaluation. The system's efficiency and scalability are also validated, supported by up to 88.7% reduction in single-machine processing time, 77.1% and 73.1% less memory and CPU usage respectively, and 7.91x processing acceleration when utilizing distributed computing ecosystems. Our system, data recipes, and multiple tutorial demos are released, calling for broader research centered on LLM data.