 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverseDiT: Towards Diverse Representation Learning in Diffusion Transformers
Mar 04, 2026Recent breakthroughs in Diffusion Transformers (DiTs) have revolutionized the field of visual synthesis due to their superior scalability. To facilitate DiTs' capability of capturing meaningful internal representations, recent works such as REPA incorporate external pretrained encoders for representation alignment. However, the underlying mechanisms governing representation learning within DiTs are not well understood. To this end, we first systematically investigate the representation dynamics of DiTs. Through analyzing the evolution and influence of internal representations under various settings, we reveal that representation diversity across blocks is a crucial factor for effective learning. Based on this key insight, we propose DiverseDiT, a novel framework that explicitly promotes representation diversity. DiverseDiT incorporates long residual connections to diversify input representations across blocks and a representation diversity loss to encourage blocks to learn distinct features. Extensive experiments on ImageNet 256x256 and 512x512 demonstrate that our DiverseDiT yields consistent performance gains and convergence acceleration when applied to different backbones with various sizes, even when tested on the challenging one-step generation setting. Furthermore, we show that DiverseDiT is complementary to existing representation learning techniques, leading to further performance gains. Our work provides valuable insights into the representation learning dynamics of DiTs and offers a practical approach for enhancing their performance.
Omni-Video 2: Scaling MLLM-Conditioned Diffusion for Unified Video Generation and Editing
Feb 09, 2026We present Omni-Video 2, a scalable and computationally efficient model that connects pretrained multimodal large-language models (MLLMs) with video diffusion models for unified video generation and editing. Our key idea is to exploit the understanding and reasoning capabilities of MLLMs to produce explicit target captions to interpret user instructions. In this way, the rich contextual representations from the understanding model are directly used to guide the generative process, thereby improving performance on complex and compositional editing. Moreover, a lightweight adapter is developed to inject multimodal conditional tokens into pretrained text-to-video diffusion models, allowing maximum reuse of their powerful generative priors in a parameter-efficient manner. Benefiting from these designs, we scale up Omni-Video 2 to a 14B video diffusion model on meticulously curated training data with quality, supporting high quality text-to-video generation and various video editing tasks such as object removal, addition, background change, complex motion editing, \emph{etc.} We evaluate the performance of Omni-Video 2 on the FiVE benchmark for fine-grained video editing and the VBench benchmark for text-to-video generation. The results demonstrate its superior ability to follow complex compositional instructions in video editing, while also achieving competitive or superior quality in video generation tasks.
SARA: Structural and Adversarial Representation Alignment for Training-efficient Diffusion Models
Mar 11, 2025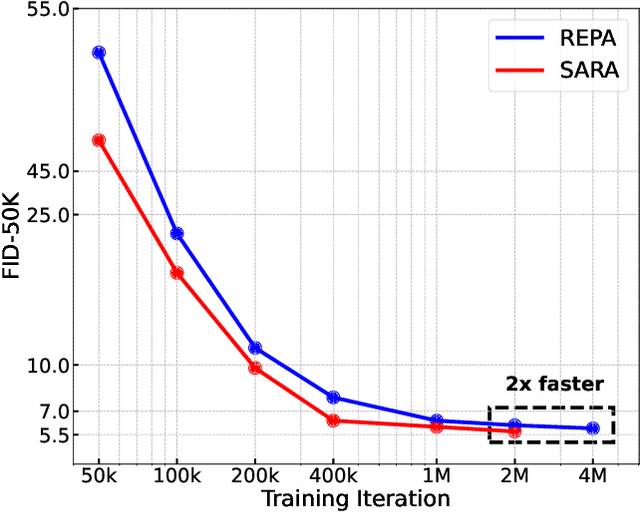
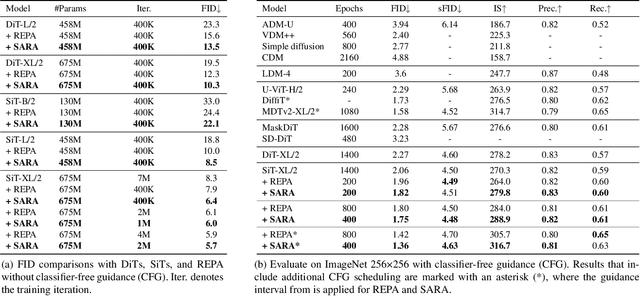


Modern diffusion models encounter a fundamental trade-off between training efficiency and generation quality. While existing representation alignment methods, such as REPA, accelerate convergence through patch-wise alignment, they often fail to capture structural relationships within visual representations and ensure global distribution consistency between pretrained encoders and denoising networks. To address these limitations, we introduce SARA, a hierarchical alignment framework that enforces multi-level representation constraints: (1) patch-wise alignment to preserve local semantic details, (2) autocorrelation matrix alignment to maintain structural consistency within representations, and (3) adversarial distribution alignment to mitigate global representation discrepancies. Unlike previous approaches, SARA explicitly models both intra-representation correlations via self-similarity matrices and inter-distribution coherence via adversarial alignment, enabling comprehensive alignment across local and global scales. Experiments on ImageNet-256 show that SARA achieves an FID of 1.36 while converging twice as fast as REPA, surpassing recent state-of-the-art image generation methods. This work establishes a systematic paradigm for optimizing diffusion training through hierarchical representation alignment.
Raccoon: Multi-stage Diffusion Training with Coarse-to-Fine Curating Videos
Feb 28, 2025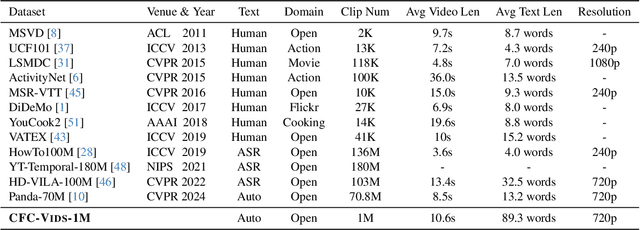


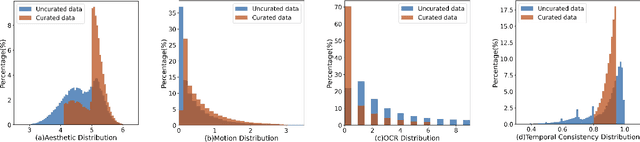
Text-to-video generation has demonstrated promising progress with the advent of diffusion models, yet existing approaches are limited by dataset quality and computational resources. To address these limitations, this paper presents a comprehensive approach that advances both data curation and model design. We introduce CFC-VIDS-1M, a high-quality video dataset constructed through a systematic coarse-to-fine curation pipeline. The pipeline first evaluates video quality across multiple dimensions, followed by a fine-grained stage that leverages vision-language models to enhance text-video alignment and semantic richness. Building upon the curated dataset's emphasis on visual quality and temporal coherence, we develop RACCOON, a transformer-based architecture with decoupled spatial-temporal attention mechanisms. The model is trained through a progressive four-stage strategy designed to efficiently handle the complexities of video generation. Extensive experiments demonstrate that our integrated approach of high-quality data curation and efficient training strategy generates visually appealing and temporally coherent videos while maintaining computational efficiency. We will release our dataset, code, and models.
E2EDiff: Direct Mapping from Noise to Data for Enhanced Diffusion Models
Dec 30, 2024



Diffusion models have emerged as a powerful framework for generative modeling, achieving state-of-the-art performance across various tasks. However, they face several inherent limitations, including a training-sampling gap, information leakage in the progressive noising process, and the inability to incorporate advanced loss functions like perceptual and adversarial losses during training. To address these challenges, we propose an innovative end-to-end training framework that aligns the training and sampling processes by directly optimizing the final reconstruction output. Our method eliminates the training-sampling gap, mitigates information leakage by treating the training process as a direct mapping from pure noise to the target data distribution, and enables the integration of perceptual and adversarial losses into the objective. Extensive experiments on benchmarks such as COCO30K and HW30K demonstrate that our approach consistently outperforms traditional diffusion models, achieving superior results in terms of FID and CLIP score, even with reduced sampling steps. These findings highlight the potential of end-to-end training to advance diffusion-based generative models toward more robust and efficient solutions.
Data-Juicer: A One-Stop Data Processing System for Large Language Models
Sep 05, 2023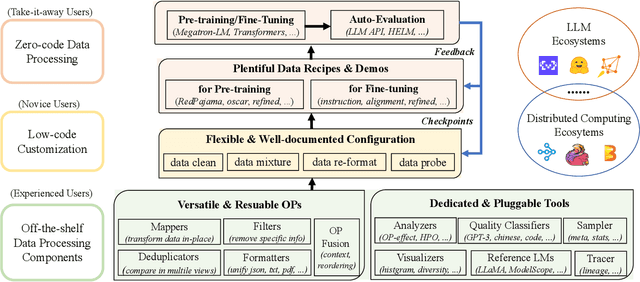
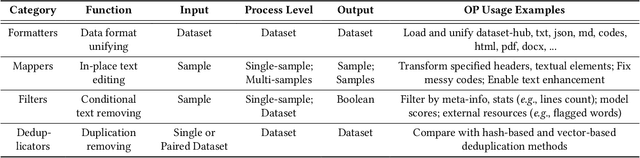
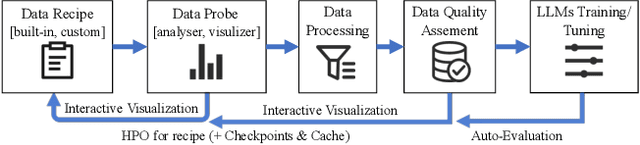
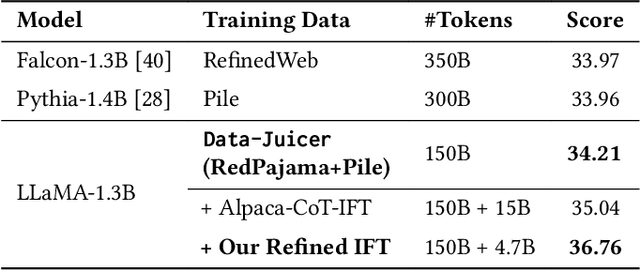
The immense evolution in Large Language Models (LLMs) has underscored the importance of massive, diverse, and high-quality data. Despite this, existing open-source tools for LLM data processing remain limited and mostly tailored to specific datasets, with an emphasis on the reproducibility of released data over adaptability and usability, inhibiting potential applications. In response, we propose a one-stop, powerful yet flexible and user-friendly LLM data processing system named Data-Juicer. Our system offers over 50 built-in versatile operators and pluggable tools, which synergize modularity, composability, and extensibility dedicated to diverse LLM data processing needs. By incorporating visualized and automatic evaluation capabilities, Data-Juicer enables a timely feedback loop to accelerate data processing and gain data insights. To enhance usability, Data-Juicer provides out-of-the-box components for users with various backgrounds, and fruitful data recipes for LLM pre-training and post-tuning usages. Further, we employ multi-facet system optimization and seamlessly integrate Data-Juicer with both LLM and distributed computing ecosystems, to enable efficient and scalable data processing. Empirical validation of the generated data recipes reveals considerable improvements in LLaMA performance for various pre-training and post-tuning cases, demonstrating up to 7.45% relative improvement of averaged score across 16 LLM benchmarks and 16.25% higher win rate using pair-wise GPT-4 evaluation. The system's efficiency and scalability are also validated, supported by up to 88.7% reduction in single-machine processing time, 77.1% and 73.1% less memory and CPU usage respectively, and 7.91x processing acceleration when utilizing distributed computing ecosystems. Our system, data recipes, and multiple tutorial demos are released, calling for broader research centered on LLM data.
Fine-Grained AutoAugmentation for Multi-Label Classification
Jul 13, 2021
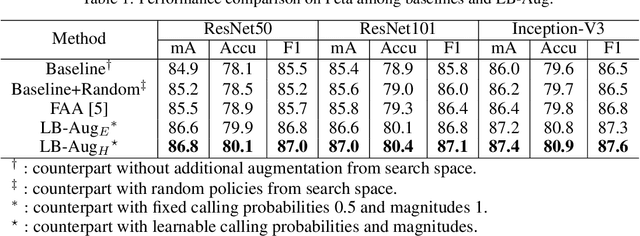
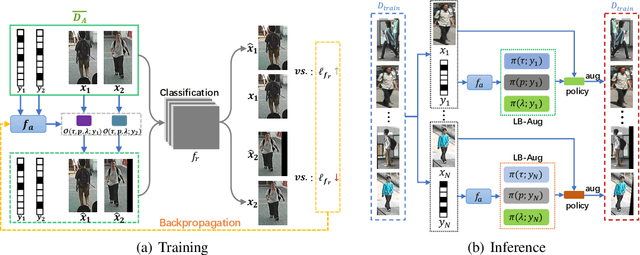
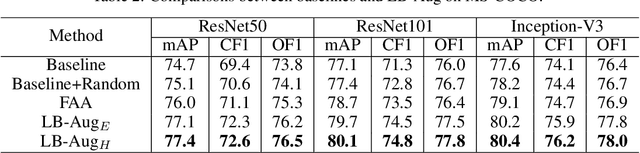
Data augmentation is a commonly used approach to improving the generalization of deep learning models. Recent works show that learned data augmentation policies can achieve better generalization than hand-crafted ones. However, most of these works use unified augmentation policies for all samples in a dataset, which is observed not necessarily beneficial for all labels in multi-label classification tasks, i.e., some policies may have negative impacts on some labels while benefitting the others. To tackle this problem, we propose a novel Label-Based AutoAugmentation (LB-Aug) method for multi-label scenarios, where augmentation policies are generated with respect to labels by an augmentation-policy network. The policies are learned via reinforcement learning using policy gradient methods, providing a mapping from instance labels to their optimal augmentation policies. Numerical experiments show that our LB-Aug outperforms previous state-of-the-art augmentation methods by large margins in multiple benchmarks on image and video classification.
Zen-NAS: A Zero-Shot NAS for High-Performance Deep Image Recognition
Feb 01, 2021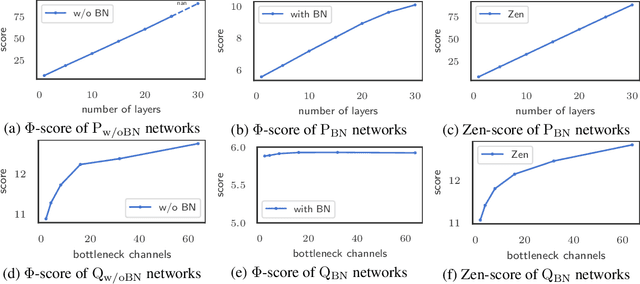
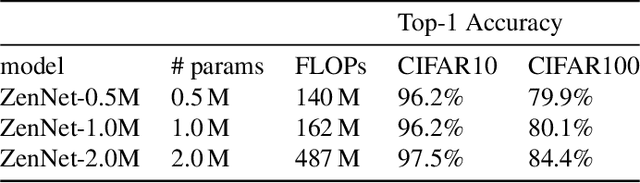
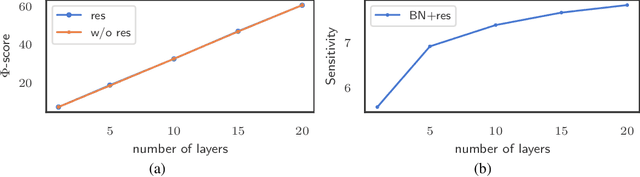
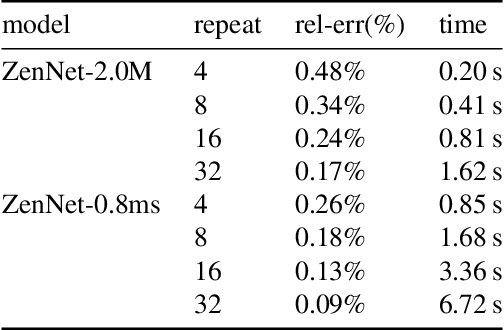
A key component in Neural Architecture Search (NAS) is an accuracy predictor which asserts the accuracy of a queried architecture. To build a high quality accuracy predictor, conventional NAS algorithms rely on training a mass of architectures or a big supernet. This step often consumes hundreds to thousands of GPU days, dominating the total search cost. To address this issue, we propose to replace the accuracy predictor with a novel model-complexity index named Zen-score. Instead of predicting model accuracy, Zen-score directly asserts the model complexity of a network without training its parameters. This is inspired by recent advances in deep learning theories which show that model complexity of a network positively correlates to its accuracy on the target dataset. The computation of Zen-score only takes a few forward inferences through a randomly initialized network using random Gaussian input. It is applicable to any Vanilla Convolutional Neural Networks (VCN-networks) or compatible variants, covering a majority of networks popular in real-world applications. When combining Zen-score with Evolutionary Algorithm, we obtain a novel Zero-Shot NAS algorithm named Zen-NAS. We conduct extensive experiments on CIFAR10/CIFAR100 and ImageNet. In summary, Zen-NAS is able to design high performance architectures in less than half GPU day (12 GPU hours). The resultant networks, named ZenNets, achieve up to $83.0\%$ top-1 accuracy on ImageNet. Comparing to EfficientNets-B3/B5 of the same or better accuracies, ZenNets are up to $5.6$ times faster on NVIDIA V100, $11$ times faster on NVIDIA T4, $2.6$ times faster on Google Pixel2 and uses $50\%$ less FLOPs. Our source code and pre-trained models are released on https://github.com/idstcv/ZenNAS.
Neural Architecture Design for GPU-Efficient Networks
Jul 12, 2020
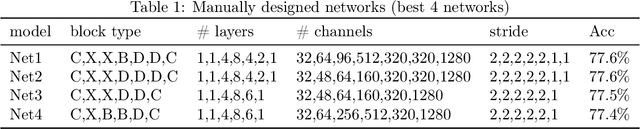
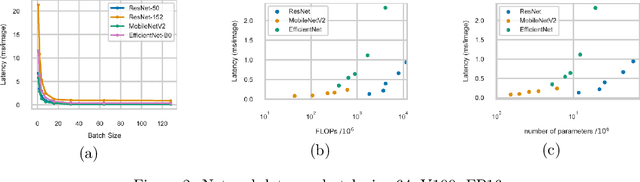
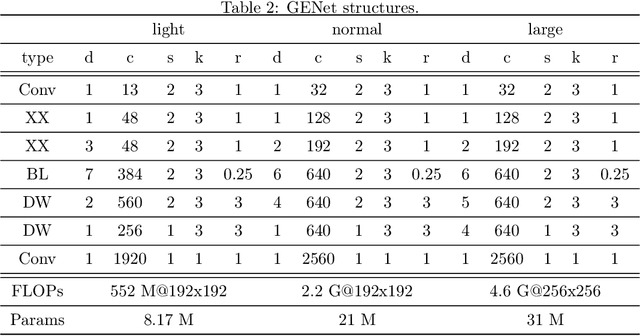
Many mission-critical systems are based on GPU for inference. It requires not only high recognition accuracy but also low latency in responding time. Although many studies are devoted to optimizing the structure of deep models for efficient inference, most of them do not leverage the architecture of \textbf{modern GPU} for fast inference, leading to suboptimal performance. To address this issue, we propose a general principle for designing GPU-efficient networks based on extensive empirical studies. This design principle enables us to search for GPU-efficient network structures effectively by a simple and lightweight method as opposed to most Neural Architecture Search (NAS) methods that are complicated and computationally expensive. Based on the proposed framework, we design a family of GPU-Efficient Networks, or GENets in short. We did extensive evaluations on multiple GPU platforms and inference engines. While achieving $\geq 81.3\%$ top-1 accuracy on ImageNet, GENet is up to $6.4$ times faster than EfficienNet on GPU. It also outperforms most state-of-the-art models that are more efficient than EfficientNet in high precision regimes. Our source code and pre-trained models are available from \url{https://github.com/idstcv/GPU-Efficient-Networks}.