 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiologically Inspired Event-Based Perception and Sample-Efficient Learning for High-Speed Table Tennis Robots
Apr 06, 2026Perception and decision-making in high-speed dynamic scenarios remain challenging for current robots. In contrast, humans and animals can rapidly perceive and make decisions in such environments. Taking table tennis as a typical example, conventional frame-based vision sensors suffer from motion blur, high latency and data redundancy, which can hardly meet real-time, accurate perception requirements. Inspired by the human visual system, event-based perception methods address these limitations through asynchronous sensing, high temporal resolution, and inherently sparse data representations. However, current event-based methods are still restricted to simplified, unrealistic ball-only scenarios. Meanwhile, existing decision-making approaches typically require thousands of interactions with the environment to converge, resulting in significant computational costs. In this work, we present a biologically inspired approach for high-speed table tennis robots, combining event-based perception with sample-efficient learning. On the perception side, we propose an event-based ball detection method that leverages motion cues and geometric consistency, operating directly on asynchronous event streams without frame reconstruction, to achieve robust and efficient detection in real-world rallies. On the decision-making side, we introduce a human-inspired, sample-efficient training strategy that first trains policies in low-speed scenarios, progressively acquiring skills from basic to advanced, and then adapts them to high-speed scenarios, guided by a case-dependent temporally adaptive reward and a reward-threshold mechanism. With the same training episodes, our method improves return-to-target accuracy by 35.8%. These results demonstrate the effectiveness of biologically inspired perception and decision-making for high-speed robotic systems.
LiRA: Linguistic Robust Anchoring for Cross-lingual Large Language Models
Oct 16, 2025As large language models (LLMs) rapidly advance, performance on high-resource languages (e.g., English, Chinese) is nearing saturation, yet remains substantially lower for low-resource languages (e.g., Urdu, Thai) due to limited training data, machine-translation noise, and unstable cross-lingual alignment. We introduce LiRA (Linguistic Robust Anchoring for Large Language Models), a training framework that robustly improves cross-lingual representations under low-resource conditions while jointly strengthening retrieval and reasoning. LiRA comprises two modules: (i) Arca (Anchored Representation Composition Architecture), which anchors low-resource languages to an English semantic space via anchor-based alignment and multi-agent collaborative encoding, preserving geometric stability in a shared embedding space; and (ii) LaSR (Language-coupled Semantic Reasoner), which adds a language-aware lightweight reasoning head with consistency regularization on top of Arca's multilingual representations, unifying the training objective to enhance cross-lingual understanding, retrieval, and reasoning robustness. We further construct and release a multilingual product retrieval dataset covering five Southeast Asian and two South Asian languages. Experiments across low-resource benchmarks (cross-lingual retrieval, semantic similarity, and reasoning) show consistent gains and robustness under few-shot and noise-amplified settings; ablations validate the contribution of both Arca and LaSR. Code will be released on GitHub and the dataset on Hugging Face.
Embodied Neuromorphic Control Applied on a 7-DOF Robotic Manipulator
Apr 17, 2025



The development of artificial intelligence towards real-time interaction with the environment is a key aspect of embodied intelligence and robotics. Inverse dynamics is a fundamental robotics problem, which maps from joint space to torque space of robotic systems. Traditional methods for solving it rely on direct physical modeling of robots which is difficult or even impossible due to nonlinearity and external disturbance. Recently, data-based model-learning algorithms are adopted to address this issue. However, they often require manual parameter tuning and high computational costs. Neuromorphic computing is inherently suitable to process spatiotemporal features in robot motion control at extremely low costs. However, current research is still in its infancy: existing works control only low-degree-of-freedom systems and lack performance quantification and comparison. In this paper, we propose a neuromorphic control framework to control 7 degree-of-freedom robotic manipulators. We use Spiking Neural Network to leverage the spatiotemporal continuity of the motion data to improve control accuracy, and eliminate manual parameters tuning. We validated the algorithm on two robotic platforms, which reduces torque prediction error by at least 60% and performs a target position tracking task successfully. This work advances embodied neuromorphic control by one step forward from proof of concept to applications in complex real-world tasks.
FuseAnyPart: Diffusion-Driven Facial Parts Swapping via Multiple Reference Images
Oct 30, 2024Facial parts swapping aims to selectively transfer regions of interest from the source image onto the target image while maintaining the rest of the target image unchanged. Most studies on face swapping designed specifically for full-face swapping, are either unable or significantly limited when it comes to swapping individual facial parts, which hinders fine-grained and customized character designs. However, designing such an approach specifically for facial parts swapping is challenged by a reasonable multiple reference feature fusion, which needs to be both efficient and effective. To overcome this challenge, FuseAnyPart is proposed to facilitate the seamless "fuse-any-part" customization of the face. In FuseAnyPart, facial parts from different people are assembled into a complete face in latent space within the Mask-based Fusion Module. Subsequently, the consolidated feature is dispatched to the Addition-based Injection Module for fusion within the UNet of the diffusion model to create novel characters. Extensive experiments qualitatively and quantitatively validate the superiority and robustness of FuseAnyPart. Source codes are available at https://github.com/Thomas-wyh/FuseAnyPart.
UniDM: A Unified Framework for Data Manipulation with Large Language Models
May 10, 2024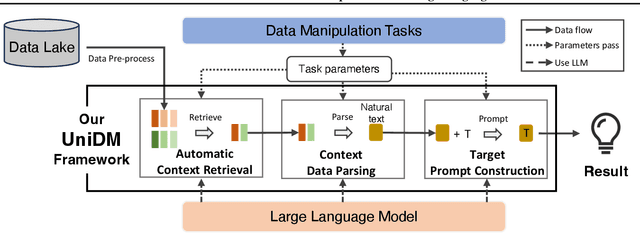
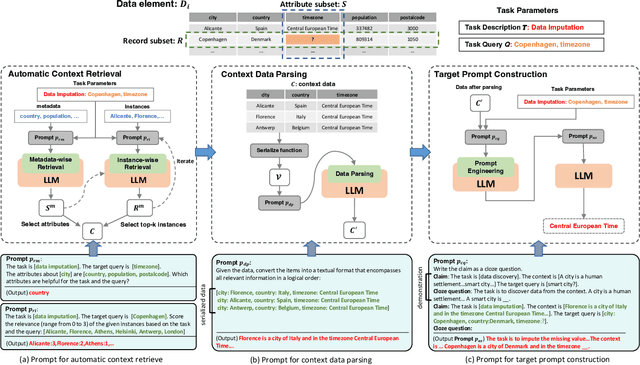
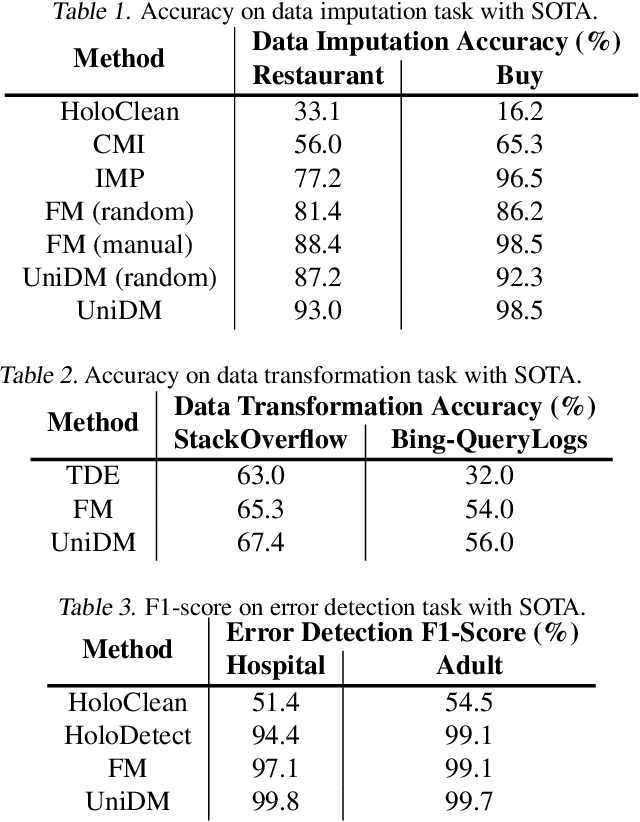
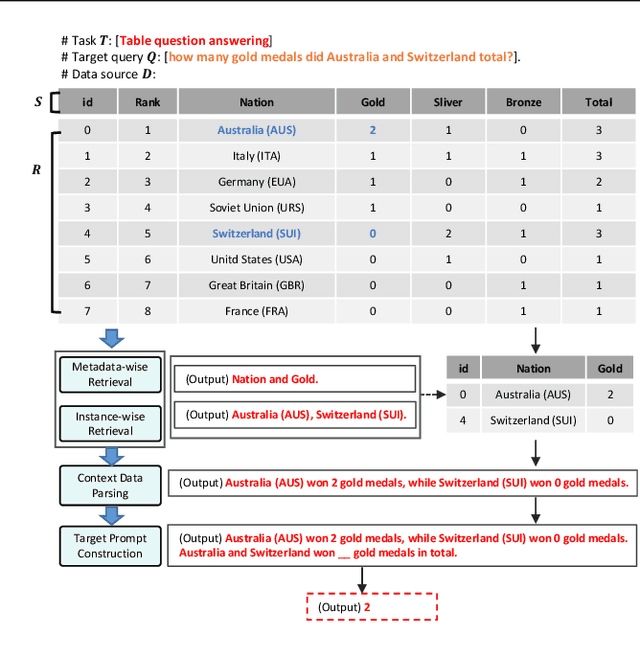
Designing effective data manipulation methods is a long standing problem in data lakes. Traditional methods, which rely on rules or machine learning models, require extensive human efforts on training data collection and tuning models. Recent methods apply Large Language Models (LLMs) to resolve multiple data manipulation tasks. They exhibit bright benefits in terms of performance but still require customized designs to fit each specific task. This is very costly and can not catch up with the requirements of big data lake platforms. In this paper, inspired by the cross-task generality of LLMs on NLP tasks, we pave the first step to design an automatic and general solution to tackle with data manipulation tasks. We propose UniDM, a unified framework which establishes a new paradigm to process data manipulation tasks using LLMs. UniDM formalizes a number of data manipulation tasks in a unified form and abstracts three main general steps to solve each task. We develop an automatic context retrieval to allow the LLMs to retrieve data from data lakes, potentially containing evidence and factual information. For each step, we design effective prompts to guide LLMs to produce high quality results. By our comprehensive evaluation on a variety of benchmarks, our UniDM exhibits great generality and state-of-the-art performance on a wide variety of data manipulation tasks.
Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks
Mar 30, 2023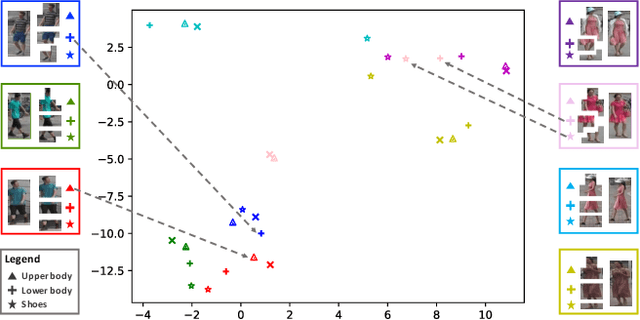
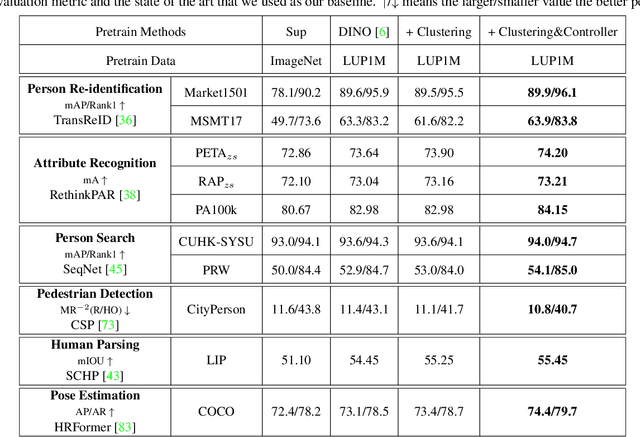
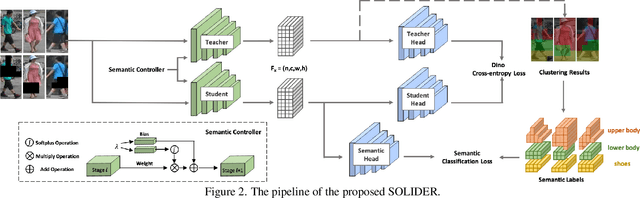
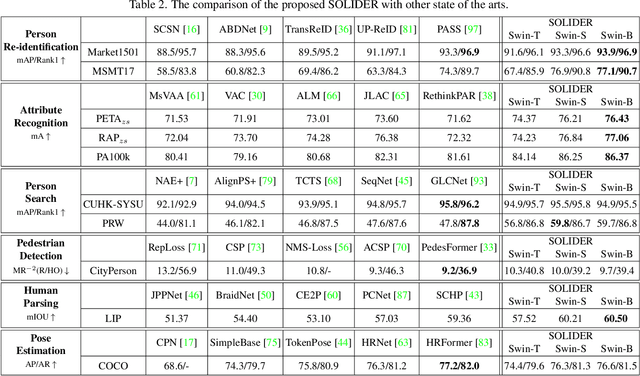
Human-centric visual tasks have attracted increasing research attention due to their widespread applications. In this paper, we aim to learn a general human representation from massive unlabeled human images which can benefit downstream human-centric tasks to the maximum extent. We call this method SOLIDER, a Semantic cOntrollable seLf-supervIseD lEaRning framework. Unlike the existing self-supervised learning methods, prior knowledge from human images is utilized in SOLIDER to build pseudo semantic labels and import more semantic information into the learned representation. Meanwhile, we note that different downstream tasks always require different ratios of semantic information and appearance information. For example, human parsing requires more semantic information, while person re-identification needs more appearance information for identification purpose. So a single learned representation cannot fit for all requirements. To solve this problem, SOLIDER introduces a conditional network with a semantic controller. After the model is trained, users can send values to the controller to produce representations with different ratios of semantic information, which can fit different needs of downstream tasks. Finally, SOLIDER is verified on six downstream human-centric visual tasks. It outperforms state of the arts and builds new baselines for these tasks. The code is released in https://github.com/tinyvision/SOLIDER.
DeepMAD: Mathematical Architecture Design for Deep Convolutional Neural Network
Mar 05, 2023



The rapid advances in Vision Transformer (ViT) refresh the state-of-the-art performances in various vision tasks, overshadowing the conventional CNN-based models. This ignites a few recent striking-back research in the CNN world showing that pure CNN models can achieve as good performance as ViT models when carefully tuned. While encouraging, designing such high-performance CNN models is challenging, requiring non-trivial prior knowledge of network design. To this end, a novel framework termed Mathematical Architecture Design for Deep CNN (DeepMAD) is proposed to design high-performance CNN models in a principled way. In DeepMAD, a CNN network is modeled as an information processing system whose expressiveness and effectiveness can be analytically formulated by their structural parameters. Then a constrained mathematical programming (MP) problem is proposed to optimize these structural parameters. The MP problem can be easily solved by off-the-shelf MP solvers on CPUs with a small memory footprint. In addition, DeepMAD is a pure mathematical framework: no GPU or training data is required during network design. The superiority of DeepMAD is validated on multiple large-scale computer vision benchmark datasets. Notably on ImageNet-1k, only using conventional convolutional layers, DeepMAD achieves 0.7% and 1.5% higher top-1 accuracy than ConvNeXt and Swin on Tiny level, and 0.8% and 0.9% higher on Small level.
Mutual Information Learned Regressor: an Information-theoretic Viewpoint of Training Regression Systems
Nov 23, 2022As one of the central tasks in machine learning, regression finds lots of applications in different fields. An existing common practice for solving regression problems is the mean square error (MSE) minimization approach or its regularized variants which require prior knowledge about the models. Recently, Yi et al., proposed a mutual information based supervised learning framework where they introduced a label entropy regularization which does not require any prior knowledge. When applied to classification tasks and solved via a stochastic gradient descent (SGD) optimization algorithm, their approach achieved significant improvement over the commonly used cross entropy loss and its variants. However, they did not provide a theoretical convergence analysis of the SGD algorithm for the proposed formulation. Besides, applying the framework to regression tasks is nontrivial due to the potentially infinite support set of the label. In this paper, we investigate the regression under the mutual information based supervised learning framework. We first argue that the MSE minimization approach is equivalent to a conditional entropy learning problem, and then propose a mutual information learning formulation for solving regression problems by using a reparameterization technique. For the proposed formulation, we give the convergence analysis of the SGD algorithm for solving it in practice. Finally, we consider a multi-output regression data model where we derive the generalization performance lower bound in terms of the mutual information associated with the underlying data distribution. The result shows that the high dimensionality can be a bless instead of a curse, which is controlled by a threshold. We hope our work will serve as a good starting point for further research on the mutual information based regression.
Robust Graph Structure Learning over Images via Multiple Statistical Tests
Oct 08, 2022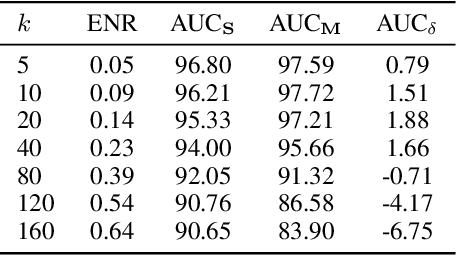
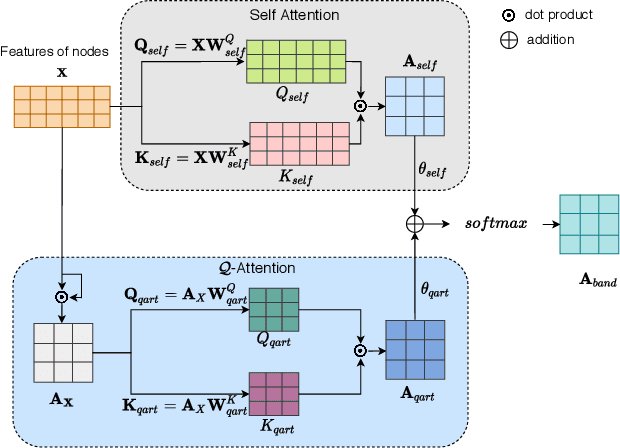
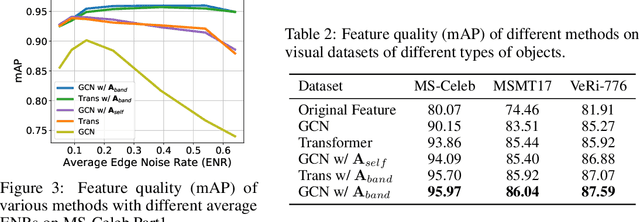
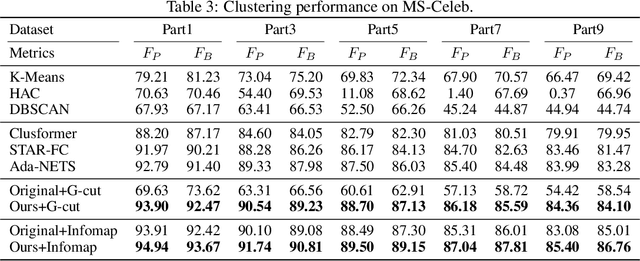
Graph structure learning aims to learn connectivity in a graph from data. It is particularly important for many computer vision related tasks since no explicit graph structure is available for images for most cases. A natural way to construct a graph among images is to treat each image as a node and assign pairwise image similarities as weights to corresponding edges. It is well known that pairwise similarities between images are sensitive to the noise in feature representations, leading to unreliable graph structures. We address this problem from the viewpoint of statistical tests. By viewing the feature vector of each node as an independent sample, the decision of whether creating an edge between two nodes based on their similarity in feature representation can be thought as a ${\it single}$ statistical test. To improve the robustness in the decision of creating an edge, multiple samples are drawn and integrated by ${\it multiple}$ statistical tests to generate a more reliable similarity measure, consequentially more reliable graph structure. The corresponding elegant matrix form named $\mathcal{B}\textbf{-Attention}$ is designed for efficiency. The effectiveness of multiple tests for graph structure learning is verified both theoretically and empirically on multiple clustering and ReID benchmark datasets. Source codes are available at https://github.com/Thomas-wyh/B-Attention.
Ada-NETS: Face Clustering via Adaptive Neighbour Discovery in the Structure Space
Feb 08, 2022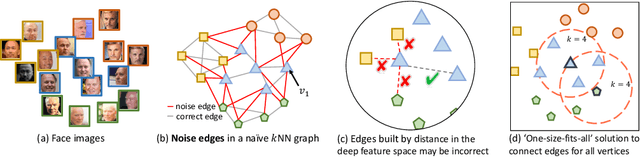
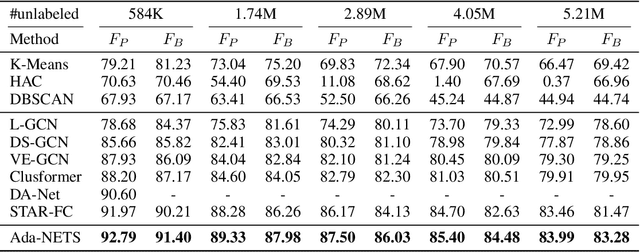
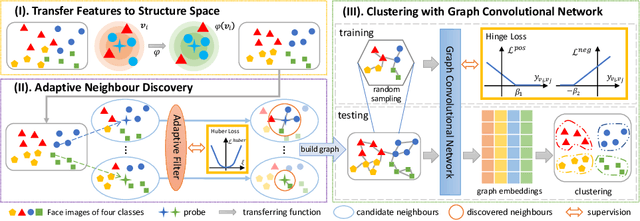
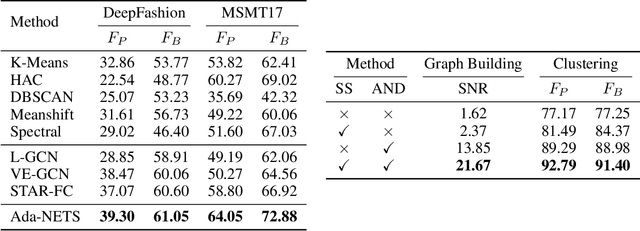
Face clustering has attracted rising research interest recently to take advantage of massive amounts of face images on the web. State-of-the-art performance has been achieved by Graph Convolutional Networks (GCN) due to their powerful representation capacity. However, existing GCN-based methods build face graphs mainly according to kNN relations in the feature space, which may lead to a lot of noise edges connecting two faces of different classes. The face features will be polluted when messages pass along these noise edges, thus degrading the performance of GCNs. In this paper, a novel algorithm named Ada-NETS is proposed to cluster faces by constructing clean graphs for GCNs. In Ada-NETS, each face is transformed to a new structure space, obtaining robust features by considering face features of the neighbour images. Then, an adaptive neighbour discovery strategy is proposed to determine a proper number of edges connecting to each face image. It significantly reduces the noise edges while maintaining the good ones to build a graph with clean yet rich edges for GCNs to cluster faces. Experiments on multiple public clustering datasets show that Ada-NETS significantly outperforms current state-of-the-art methods, proving its superiority and generalization.