 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiRA: Linguistic Robust Anchoring for Cross-lingual Large Language Models
Oct 16, 2025As large language models (LLMs) rapidly advance, performance on high-resource languages (e.g., English, Chinese) is nearing saturation, yet remains substantially lower for low-resource languages (e.g., Urdu, Thai) due to limited training data, machine-translation noise, and unstable cross-lingual alignment. We introduce LiRA (Linguistic Robust Anchoring for Large Language Models), a training framework that robustly improves cross-lingual representations under low-resource conditions while jointly strengthening retrieval and reasoning. LiRA comprises two modules: (i) Arca (Anchored Representation Composition Architecture), which anchors low-resource languages to an English semantic space via anchor-based alignment and multi-agent collaborative encoding, preserving geometric stability in a shared embedding space; and (ii) LaSR (Language-coupled Semantic Reasoner), which adds a language-aware lightweight reasoning head with consistency regularization on top of Arca's multilingual representations, unifying the training objective to enhance cross-lingual understanding, retrieval, and reasoning robustness. We further construct and release a multilingual product retrieval dataset covering five Southeast Asian and two South Asian languages. Experiments across low-resource benchmarks (cross-lingual retrieval, semantic similarity, and reasoning) show consistent gains and robustness under few-shot and noise-amplified settings; ablations validate the contribution of both Arca and LaSR. Code will be released on GitHub and the dataset on Hugging Face.
UniEdit-Flow: Unleashing Inversion and Editing in the Era of Flow Models
Apr 17, 2025

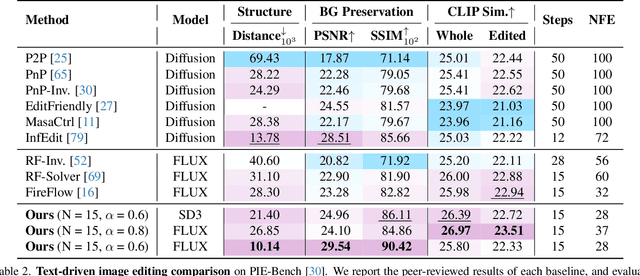
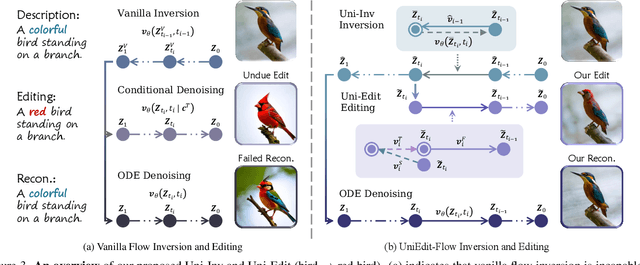
Flow matching models have emerged as a strong alternative to diffusion models, but existing inversion and editing methods designed for diffusion are often ineffective or inapplicable to them. The straight-line, non-crossing trajectories of flow models pose challenges for diffusion-based approaches but also open avenues for novel solutions. In this paper, we introduce a predictor-corrector-based framework for inversion and editing in flow models. First, we propose Uni-Inv, an effective inversion method designed for accurate reconstruction. Building on this, we extend the concept of delayed injection to flow models and introduce Uni-Edit, a region-aware, robust image editing approach. Our methodology is tuning-free, model-agnostic, efficient, and effective, enabling diverse edits while ensuring strong preservation of edit-irrelevant regions. Extensive experiments across various generative models demonstrate the superiority and generalizability of Uni-Inv and Uni-Edit, even under low-cost settings. Project page: https://uniedit-flow.github.io/
Semantic-Rearrangement-Based Multi-Level Alignment for Domain Generalized Segmentation
Apr 21, 2024



Domain generalized semantic segmentation is an essential computer vision task, for which models only leverage source data to learn the capability of generalized semantic segmentation towards the unseen target domains. Previous works typically address this challenge by global style randomization or feature regularization. In this paper, we argue that given the observation that different local semantic regions perform different visual characteristics from the source domain to the target domain, methods focusing on global operations are hard to capture such regional discrepancies, thus failing to construct domain-invariant representations with the consistency from local to global level. Therefore, we propose the Semantic-Rearrangement-based Multi-Level Alignment (SRMA) to overcome this problem. SRMA first incorporates a Semantic Rearrangement Module (SRM), which conducts semantic region randomization to enhance the diversity of the source domain sufficiently. A Multi-Level Alignment module (MLA) is subsequently proposed with the help of such diversity to establish the global-regional-local consistent domain-invariant representations. By aligning features across randomized samples with domain-neutral knowledge at multiple levels, SRMA provides a more robust way to handle the source-target domain gap. Extensive experiments demonstrate the superiority of SRMA over the current state-of-the-art works on various benchmarks.
LafitE: Latent Diffusion Model with Feature Editing for Unsupervised Multi-class Anomaly Detection
Jul 16, 2023



In the context of flexible manufacturing systems that are required to produce different types and quantities of products with minimal reconfiguration, this paper addresses the problem of unsupervised multi-class anomaly detection: develop a unified model to detect anomalies from objects belonging to multiple classes when only normal data is accessible. We first explore the generative-based approach and investigate latent diffusion models for reconstruction to mitigate the notorious ``identity shortcut'' issue in auto-encoder based methods. We then introduce a feature editing strategy that modifies the input feature space of the diffusion model to further alleviate ``identity shortcuts'' and meanwhile improve the reconstruction quality of normal regions, leading to fewer false positive predictions. Moreover, we are the first who pose the problem of hyperparameter selection in unsupervised anomaly detection, and propose a solution of synthesizing anomaly data for a pseudo validation set to address this problem. Extensive experiments on benchmark datasets MVTec-AD and MPDD show that the proposed LafitE, \ie, Latent Diffusion Model with Feature Editing, outperforms state-of-art methods by a significant margin in terms of average AUROC. The hyperparamters selected via our pseudo validation set are well-matched to the real test set.
UniTrans: Unifying Model Transfer and Data Transfer for Cross-Lingual Named Entity Recognition with Unlabeled Data
Jul 15, 2020



Prior works in cross-lingual named entity recognition (NER) with no/little labeled data fall into two primary categories: model transfer based and data transfer based methods. In this paper we find that both method types can complement each other, in the sense that, the former can exploit context information via language-independent features but sees no task-specific information in the target language; while the latter generally generates pseudo target-language training data via translation but its exploitation of context information is weakened by inaccurate translations. Moreover, prior works rarely leverage unlabeled data in the target language, which can be effortlessly collected and potentially contains valuable information for improved results. To handle both problems, we propose a novel approach termed UniTrans to Unify both model and data Transfer for cross-lingual NER, and furthermore, to leverage the available information from unlabeled target-language data via enhanced knowledge distillation. We evaluate our proposed UniTrans over 4 target languages on benchmark datasets. Our experimental results show that it substantially outperforms the existing state-of-the-art methods.
* This paper is accepted by IJCAI 2020. Code is available at https://github.com/microsoft/vert-papers/tree/master/papers/UniTrans
Single-/Multi-Source Cross-Lingual NER via Teacher-Student Learning on Unlabeled Data in Target Language
Apr 26, 2020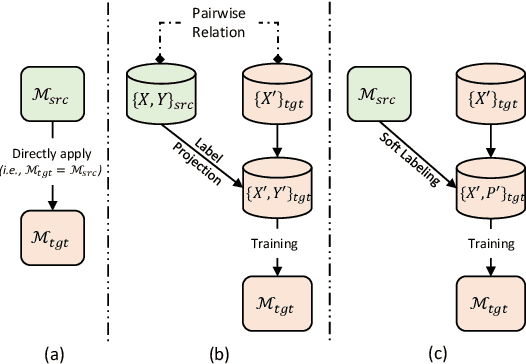

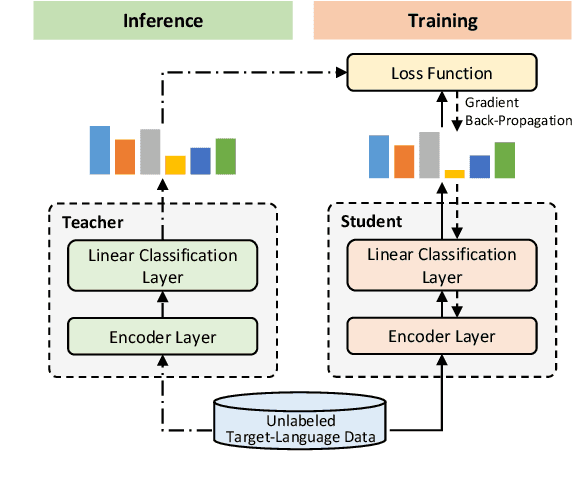

To better tackle the named entity recognition (NER) problem on languages with little/no labeled data, cross-lingual NER must effectively leverage knowledge learned from source languages with rich labeled data. Previous works on cross-lingual NER are mostly based on label projection with pairwise texts or direct model transfer. However, such methods either are not applicable if the labeled data in the source languages is unavailable, or do not leverage information contained in unlabeled data in the target language. In this paper, we propose a teacher-student learning method to address such limitations, where NER models in the source languages are used as teachers to train a student model on unlabeled data in the target language. The proposed method works for both single-source and multi-source cross-lingual NER. For the latter, we further propose a similarity measuring method to better weight the supervision from different teacher models. Extensive experiments for 3 target languages on benchmark datasets well demonstrate that our method outperforms existing state-of-the-art methods for both single-source and multi-source cross-lingual NER.
Enhanced Meta-Learning for Cross-lingual Named Entity Recognition with Minimal Resources
Nov 14, 2019



For languages with no annotated resources, transferring knowledge from rich-resource languages is an effective solution for named entity recognition (NER). While all existing methods directly transfer from source-learned model to a target language, in this paper, we propose to fine-tune the learned model with a few similar examples given a test case, which could benefit the prediction by leveraging the structural and semantic information conveyed in such similar examples. To this end, we present a meta-learning algorithm to find a good model parameter initialization that could fast adapt to the given test case and propose to construct multiple pseudo-NER tasks for meta-training by computing sentence similarities. To further improve the model's generalization ability across different languages, we introduce a masking scheme and augment the loss function with an additional maximum term during meta-training. We conduct extensive experiments on cross-lingual named entity recognition with minimal resources over five target languages. The results show that our approach significantly outperforms existing state-of-the-art methods across the board.