 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Rearrangement-Based Multi-Level Alignment for Domain Generalized Segmentation
Apr 21, 2024



Domain generalized semantic segmentation is an essential computer vision task, for which models only leverage source data to learn the capability of generalized semantic segmentation towards the unseen target domains. Previous works typically address this challenge by global style randomization or feature regularization. In this paper, we argue that given the observation that different local semantic regions perform different visual characteristics from the source domain to the target domain, methods focusing on global operations are hard to capture such regional discrepancies, thus failing to construct domain-invariant representations with the consistency from local to global level. Therefore, we propose the Semantic-Rearrangement-based Multi-Level Alignment (SRMA) to overcome this problem. SRMA first incorporates a Semantic Rearrangement Module (SRM), which conducts semantic region randomization to enhance the diversity of the source domain sufficiently. A Multi-Level Alignment module (MLA) is subsequently proposed with the help of such diversity to establish the global-regional-local consistent domain-invariant representations. By aligning features across randomized samples with domain-neutral knowledge at multiple levels, SRMA provides a more robust way to handle the source-target domain gap. Extensive experiments demonstrate the superiority of SRMA over the current state-of-the-art works on various benchmarks.
Dense Dual-Attention Network for Light Field Image Super-Resolution
Oct 23, 2021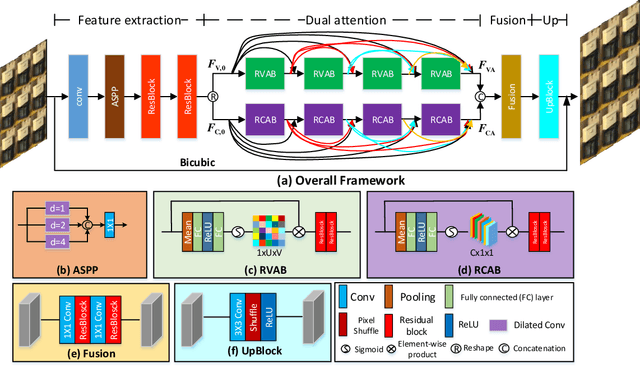
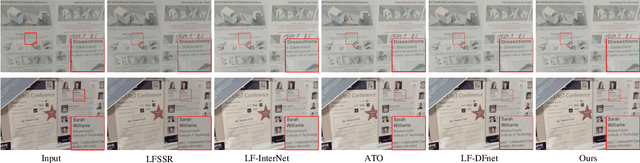

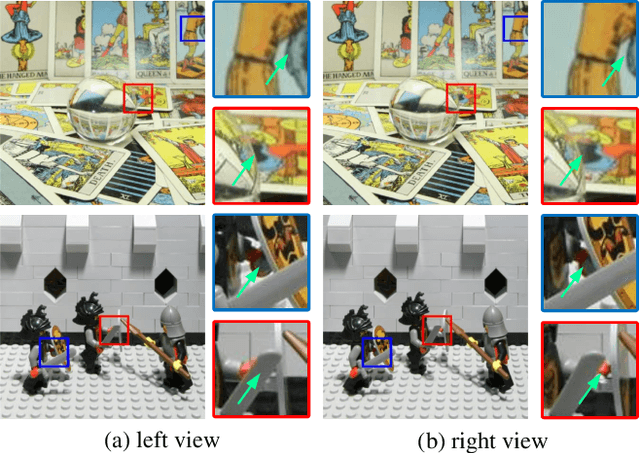
Light field (LF) images can be used to improve the performance of image super-resolution (SR) because both angular and spatial information is available. It is challenging to incorporate distinctive information from different views for LF image SR. Moreover, the long-term information from the previous layers can be weakened as the depth of network increases. In this paper, we propose a dense dual-attention network for LF image SR. Specifically, we design a view attention module to adaptively capture discriminative features across different views and a channel attention module to selectively focus on informative information across all channels. These two modules are fed to two branches and stacked separately in a chain structure for adaptive fusion of hierarchical features and distillation of valid information. Meanwhile, a dense connection is used to fully exploit multi-level information. Extensive experiments demonstrate that our dense dual-attention mechanism can capture informative information across views and channels to improve SR performance. Comparative results show the advantage of our method over state-of-the-art methods on public datasets.