 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Memory Construction and Retrieval for Personalized Conversational Agents
Feb 08, 2025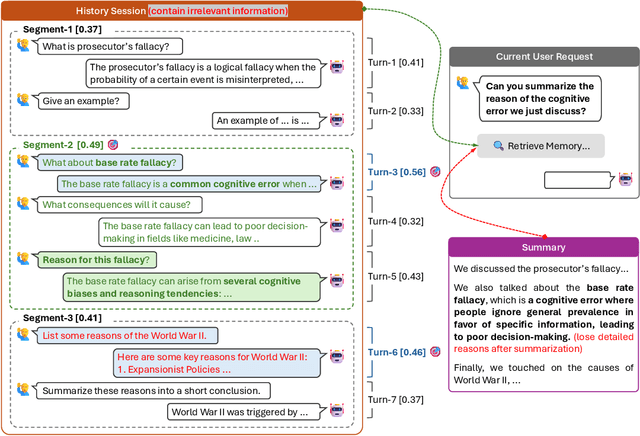
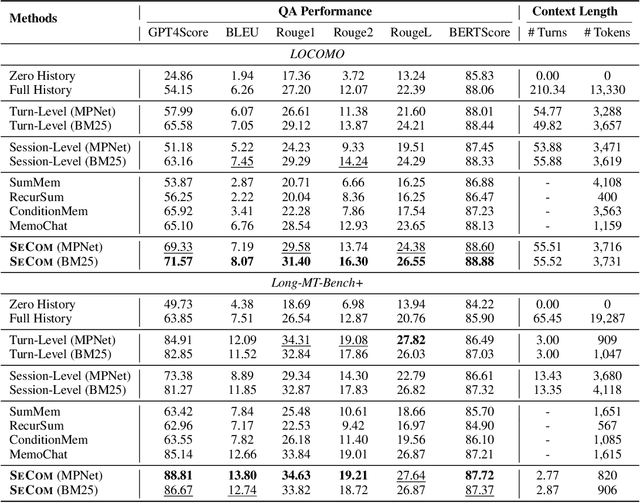
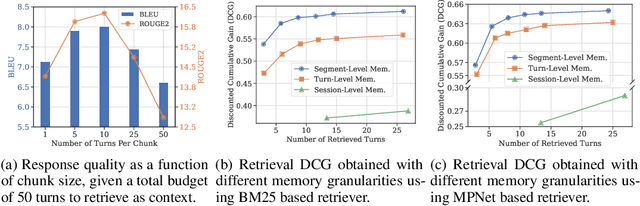

To deliver coherent and personalized experiences in long-term conversations, existing approaches typically perform retrieval augmented response generation by constructing memory banks from conversation history at either the turn-level, session-level, or through summarization techniques. In this paper, we present two key findings: (1) The granularity of memory unit matters: Turn-level, session-level, and summarization-based methods each exhibit limitations in both memory retrieval accuracy and the semantic quality of the retrieved content. (2) Prompt compression methods, such as \textit{LLMLingua-2}, can effectively serve as a denoising mechanism, enhancing memory retrieval accuracy across different granularities. Building on these insights, we propose SeCom, a method that constructs a memory bank with topical segments by introducing a conversation Segmentation model, while performing memory retrieval based on Compressed memory units. Experimental results show that SeCom outperforms turn-level, session-level, and several summarization-based methods on long-term conversation benchmarks such as LOCOMO and Long-MT-Bench+. Additionally, the proposed conversation segmentation method demonstrates superior performance on dialogue segmentation datasets such as DialSeg711, TIAGE, and SuperDialSeg.
MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention
Jul 02, 2024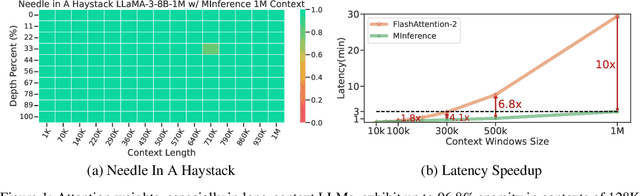

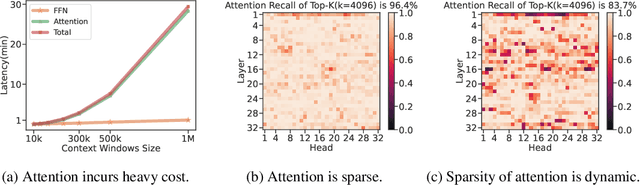
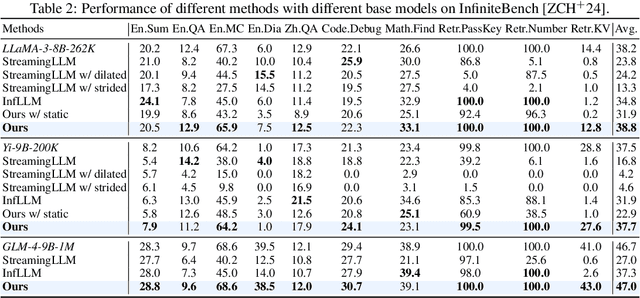
The computational challenges of Large Language Model (LLM) inference remain a significant barrier to their widespread deployment, especially as prompt lengths continue to increase. Due to the quadratic complexity of the attention computation, it takes 30 minutes for an 8B LLM to process a prompt of 1M tokens (i.e., the pre-filling stage) on a single A100 GPU. Existing methods for speeding up prefilling often fail to maintain acceptable accuracy or efficiency when applied to long-context LLMs. To address this gap, we introduce MInference (Milliontokens Inference), a sparse calculation method designed to accelerate pre-filling of long-sequence processing. Specifically, we identify three unique patterns in long-context attention matrices-the A-shape, Vertical-Slash, and Block-Sparsethat can be leveraged for efficient sparse computation on GPUs. We determine the optimal pattern for each attention head offline and dynamically build sparse indices based on the assigned pattern during inference. With the pattern and sparse indices, we perform efficient sparse attention calculations via our optimized GPU kernels to significantly reduce the latency in the pre-filling stage of long-context LLMs. Our proposed technique can be directly applied to existing LLMs without any modifications to the pre-training setup or additional fine-tuning. By evaluating on a wide range of downstream tasks, including InfiniteBench, RULER, PG-19, and Needle In A Haystack, and models including LLaMA-3-1M, GLM4-1M, Yi-200K, Phi-3-128K, and Qwen2-128K, we demonstrate that MInference effectively reduces inference latency by up to 10x for pre-filling on an A100, while maintaining accuracy. Our code is available at https://aka.ms/MInference.
Mitigate Position Bias in Large Language Models via Scaling a Single Dimension
Jun 04, 2024



Large Language Models (LLMs) are increasingly applied in various real-world scenarios due to their excellent generalization capabilities and robust generative abilities. However, they exhibit position bias, also known as "lost in the middle", a phenomenon that is especially pronounced in long-context scenarios, which indicates the placement of the key information in different positions of a prompt can significantly affect accuracy. This paper first explores the micro-level manifestations of position bias, concluding that attention weights are a micro-level expression of position bias. It further identifies that, in addition to position embeddings, causal attention mask also contributes to position bias by creating position-specific hidden states. Based on these insights, we propose a method to mitigate position bias by scaling this positional hidden states. Experiments on the NaturalQuestions Multi-document QA, KV retrieval, LongBench and timeline reorder tasks, using various models including RoPE models, context windowextended models, and Alibi models, demonstrate the effectiveness and generalizability of our approach. Our method can improve performance by up to 15.2% by modifying just one dimension of hidden states. Our code is available at https://aka.ms/PositionalHidden.
DesignProbe: A Graphic Design Benchmark for Multimodal Large Language Models
Apr 23, 2024A well-executed graphic design typically achieves harmony in two levels, from the fine-grained design elements (color, font and layout) to the overall design. This complexity makes the comprehension of graphic design challenging, for it needs the capability to both recognize the design elements and understand the design. With the rapid development of Multimodal Large Language Models (MLLMs), we establish the DesignProbe, a benchmark to investigate the capability of MLLMs in design. Our benchmark includes eight tasks in total, across both the fine-grained element level and the overall design level. At design element level, we consider both the attribute recognition and semantic understanding tasks. At overall design level, we include style and metaphor. 9 MLLMs are tested and we apply GPT-4 as evaluator. Besides, further experiments indicates that refining prompts can enhance the performance of MLLMs. We first rewrite the prompts by different LLMs and found increased performances appear in those who self-refined by their own LLMs. We then add extra task knowledge in two different ways (text descriptions and image examples), finding that adding images boost much more performance over texts.
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Mar 19, 2024



This paper focuses on task-agnostic prompt compression for better generalizability and efficiency. Considering the redundancy in natural language, existing approaches compress prompts by removing tokens or lexical units according to their information entropy obtained from a causal language model such as LLaMa-7B. The challenge is that information entropy may be a suboptimal compression metric: (i) it only leverages unidirectional context and may fail to capture all essential information needed for prompt compression; (ii) it is not aligned with the prompt compression objective. To address these issues, we propose a data distillation procedure to derive knowledge from an LLM to compress prompts without losing crucial information, and meantime, introduce an extractive text compression dataset. We formulate prompt compression as a token classification problem to guarantee the faithfulness of the compressed prompt to the original one, and use a Transformer encoder as the base architecture to capture all essential information for prompt compression from the full bidirectional context. Our approach leads to lower latency by explicitly learning the compression objective with smaller models such as XLM-RoBERTa-large and mBERT. We evaluate our method on both in-domain and out-of-domain datasets, including MeetingBank, LongBench, ZeroScrolls, GSM8K, and BBH. Despite its small size, our model shows significant performance gains over strong baselines and demonstrates robust generalization ability across different LLMs. Additionally, our model is 3x-6x faster than existing prompt compression methods, while accelerating the end-to-end latency by 1.6x-2.9x with compression ratios of 2x-5x.
Desigen: A Pipeline for Controllable Design Template Generation
Mar 14, 2024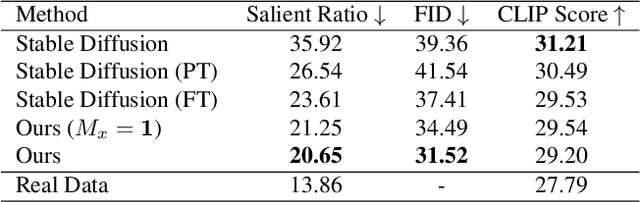
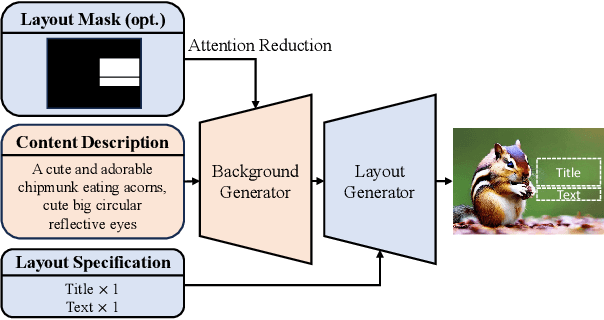
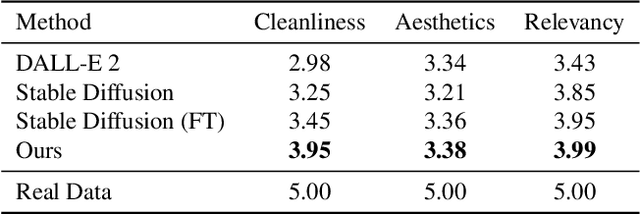
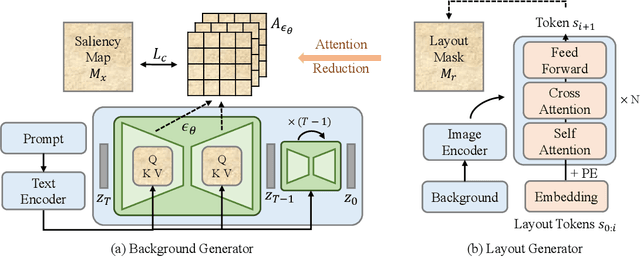
Templates serve as a good starting point to implement a design (e.g., banner, slide) but it takes great effort from designers to manually create. In this paper, we present Desigen, an automatic template creation pipeline which generates background images as well as harmonious layout elements over the background. Different from natural images, a background image should preserve enough non-salient space for the overlaying layout elements. To equip existing advanced diffusion-based models with stronger spatial control, we propose two simple but effective techniques to constrain the saliency distribution and reduce the attention weight in desired regions during the background generation process. Then conditioned on the background, we synthesize the layout with a Transformer-based autoregressive generator. To achieve a more harmonious composition, we propose an iterative inference strategy to adjust the synthesized background and layout in multiple rounds. We constructed a design dataset with more than 40k advertisement banners to verify our approach. Extensive experiments demonstrate that the proposed pipeline generates high-quality templates comparable to human designers. More than a single-page design, we further show an application of presentation generation that outputs a set of theme-consistent slides. The data and code are available at https://whaohan.github.io/desigen.
Spot the Error: Non-autoregressive Graphic Layout Generation with Wireframe Locator
Jan 29, 2024



Layout generation is a critical step in graphic design to achieve meaningful compositions of elements. Most previous works view it as a sequence generation problem by concatenating element attribute tokens (i.e., category, size, position). So far the autoregressive approach (AR) has achieved promising results, but is still limited in global context modeling and suffers from error propagation since it can only attend to the previously generated tokens. Recent non-autoregressive attempts (NAR) have shown competitive results, which provides a wider context range and the flexibility to refine with iterative decoding. However, current works only use simple heuristics to recognize erroneous tokens for refinement which is inaccurate. This paper first conducts an in-depth analysis to better understand the difference between the AR and NAR framework. Furthermore, based on our observation that pixel space is more sensitive in capturing spatial patterns of graphic layouts (e.g., overlap, alignment), we propose a learning-based locator to detect erroneous tokens which takes the wireframe image rendered from the generated layout sequence as input. We show that it serves as a complementary modality to the element sequence in object space and contributes greatly to the overall performance. Experiments on two public datasets show that our approach outperforms both AR and NAR baselines. Extensive studies further prove the effectiveness of different modules with interesting findings. Our code will be available at https://github.com/ffffatgoose/SpotError.
Unlocking Science: Novel Dataset and Benchmark for Cross-Modality Scientific Information Extraction
Nov 15, 2023Extracting key information from scientific papers has the potential to help researchers work more efficiently and accelerate the pace of scientific progress. Over the last few years, research on Scientific Information Extraction (SciIE) witnessed the release of several new systems and benchmarks. However, existing paper-focused datasets mostly focus only on specific parts of a manuscript (e.g., abstracts) and are single-modality (i.e., text- or table-only), due to complex processing and expensive annotations. Moreover, core information can be present in either text or tables or across both. To close this gap in data availability and enable cross-modality IE, while alleviating labeling costs, we propose a semi-supervised pipeline for annotating entities in text, as well as entities and relations in tables, in an iterative procedure. Based on this pipeline, we release novel resources for the scientific community, including a high-quality benchmark, a large-scale corpus, and a semi-supervised annotation pipeline. We further report the performance of state-of-the-art IE models on the proposed benchmark dataset, as a baseline. Lastly, we explore the potential capability of large language models such as ChatGPT for the current task. Our new dataset, results, and analysis validate the effectiveness and efficiency of our semi-supervised pipeline, and we discuss its remaining limitations.
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
Oct 10, 2023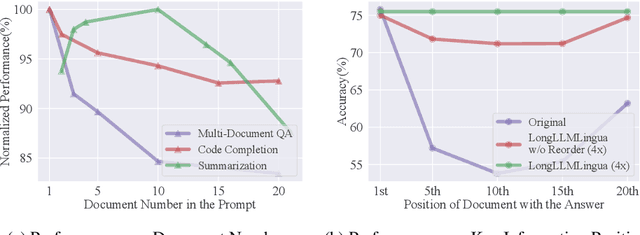



In long context scenarios, large language models (LLMs) face three main challenges: higher computational/financial cost, longer latency, and inferior performance. Some studies reveal that the performance of LLMs depends on both the density and the position of the key information (question relevant) in the input prompt. Inspired by these findings, we propose LongLLMLingua for prompt compression towards improving LLMs' perception of the key information to simultaneously address the three challenges. We conduct evaluation on a wide range of long context scenarios including single-/multi-document QA, few-shot learning, summarization, synthetic tasks, and code completion. The experimental results show that LongLLMLingua compressed prompt can derive higher performance with much less cost. The latency of the end-to-end system is also reduced. For example, on NaturalQuestions benchmark, LongLLMLingua gains a performance boost of up to 17.1% over the original prompt with ~4x fewer tokens as input to GPT-3.5-Turbo. It can derive cost savings of \$28.5 and \$27.4 per 1,000 samples from the LongBench and ZeroScrolls benchmark, respectively. Additionally, when compressing prompts of ~10k tokens at a compression rate of 2x-10x, LongLLMLingua can speed up the end-to-end latency by 1.4x-3.8x. Our code is available at https://aka.ms/LLMLingua.
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
Oct 09, 2023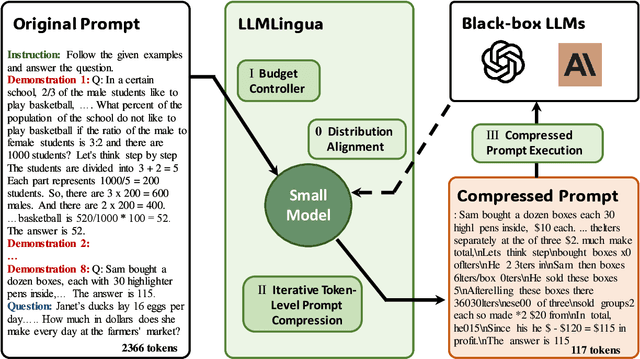


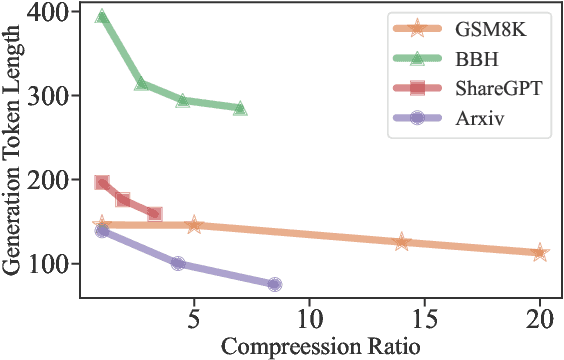
Large language models (LLMs) have been applied in various applications due to their astonishing capabilities. With advancements in technologies such as chain-of-thought (CoT) prompting and in-context learning (ICL), the prompts fed to LLMs are becoming increasingly lengthy, even exceeding tens of thousands of tokens. To accelerate model inference and reduce cost, this paper presents LLMLingua, a coarse-to-fine prompt compression method that involves a budget controller to maintain semantic integrity under high compression ratios, a token-level iterative compression algorithm to better model the interdependence between compressed contents, and an instruction tuning based method for distribution alignment between language models. We conduct experiments and analysis over four datasets from different scenarios, i.e., GSM8K, BBH, ShareGPT, and Arxiv-March23; showing that the proposed approach yields state-of-the-art performance and allows for up to 20x compression with little performance loss. Our code is available at https://aka.ms/LLMLingua.